About to Post a Job Opening? Think Again – You May Reveal Sensitive Information Primed for Cybersecurity Attacks
By
Alejandro Hernandez
People are always on the move, changing their homes and their workspaces. With increasing frequency, they move from their current jobs to new positions, seeking new challenges, new people and places, to higher salaries.
Time and hard work bring experience and expertise, and these two qualities are what companies look for; they’re looking for skilled workers every single day, on multiple job search and recruiting platforms. However, these job postings might reveal sensitive information about the company that even the most seasoned Human Resources specialists don’t notice.
Job posting websites are a goldmine of information. Inherently, recruiters have to disclose certain data points, such as the technologies used by the company, so that candidates can assess whether they should apply. On the other hand, these data points could be used by malicious actors to profile a specific company and launch more sophisticated targeted attacks against the company and its employees.
To demonstrate this concept, I did research on tens of job postings from the following websites:
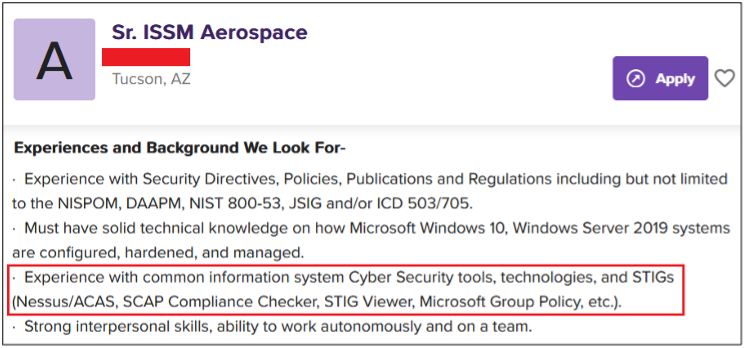
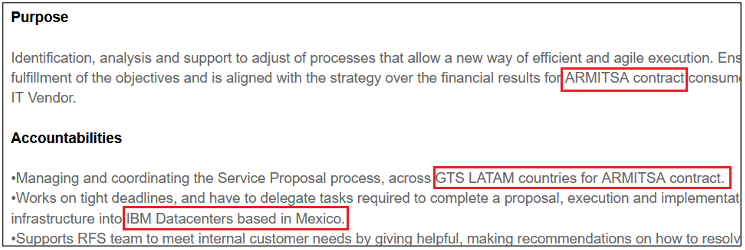
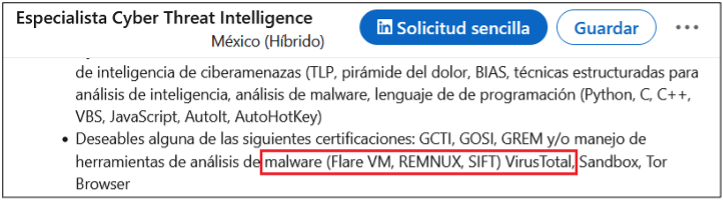
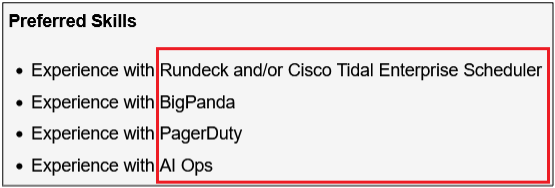
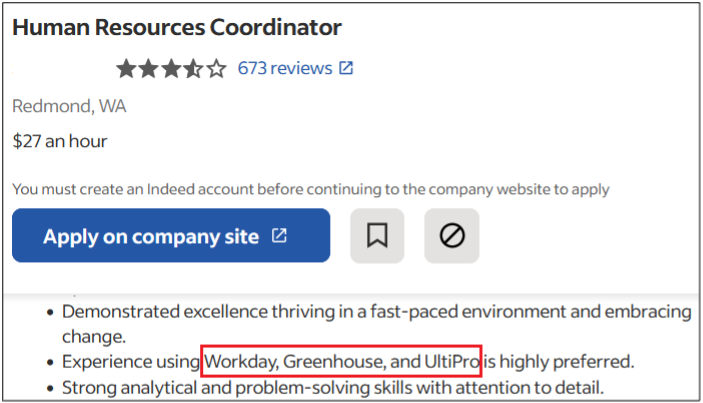
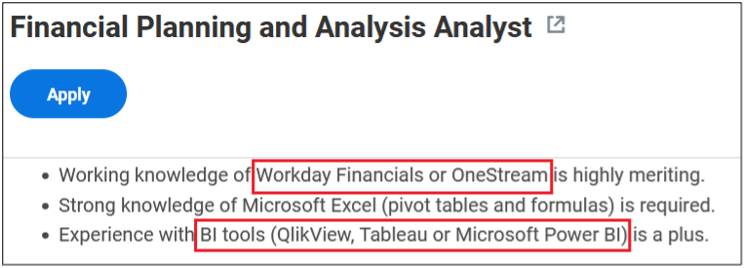
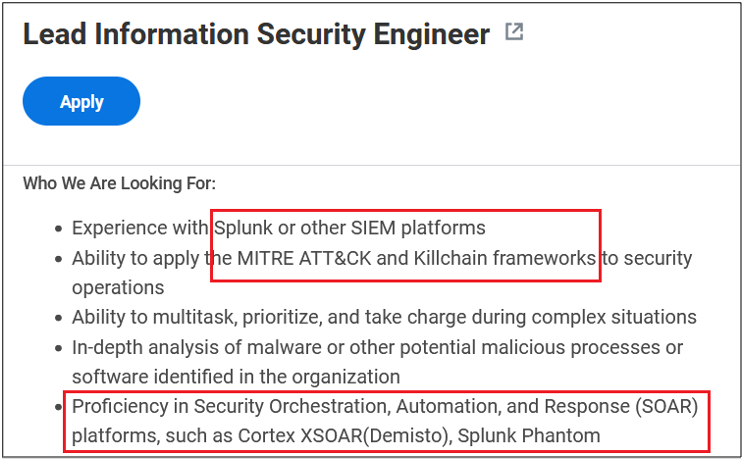
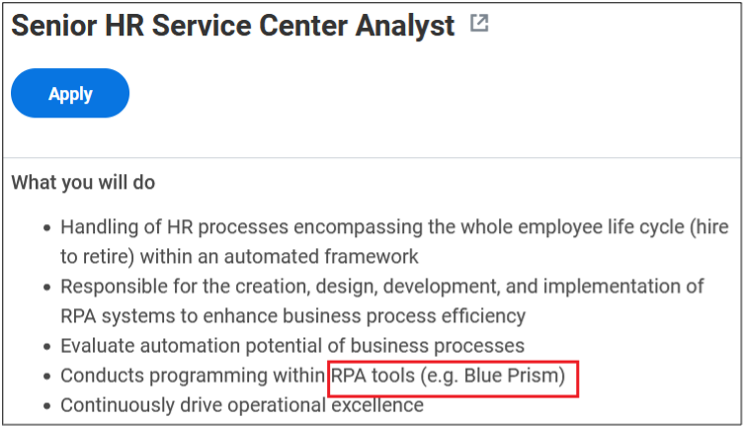
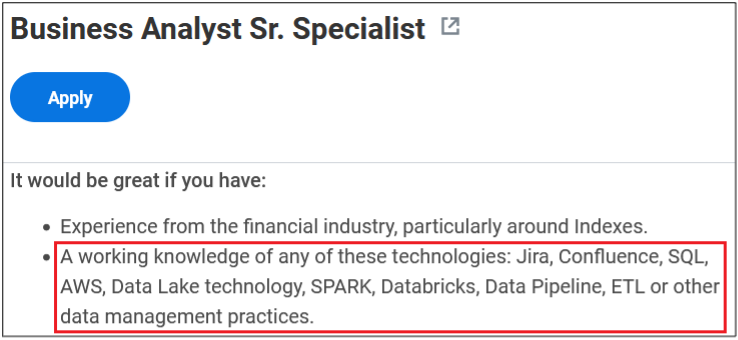
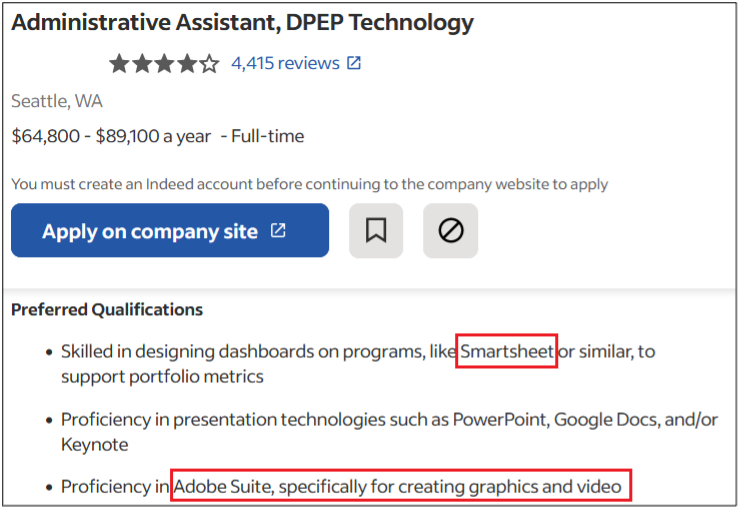
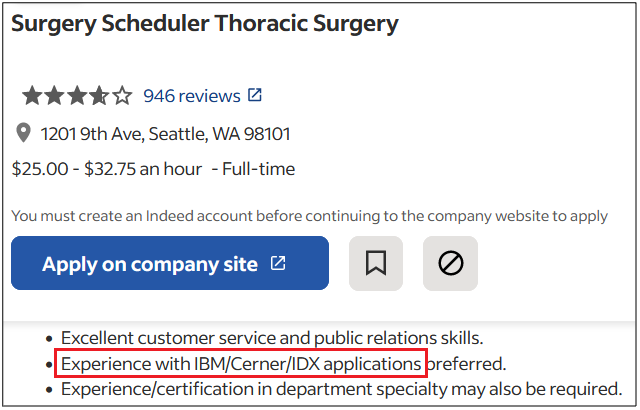
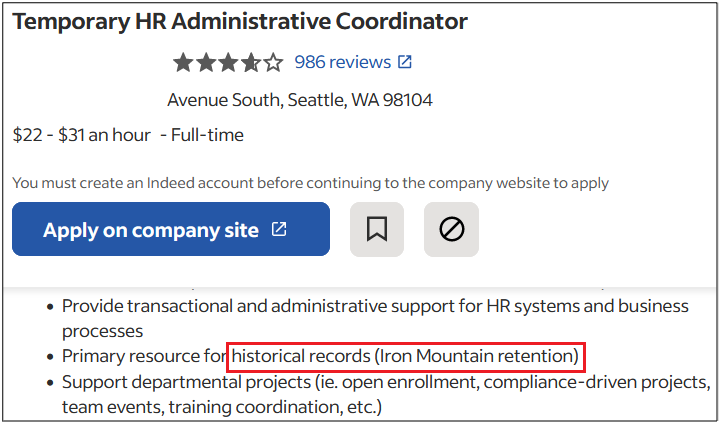
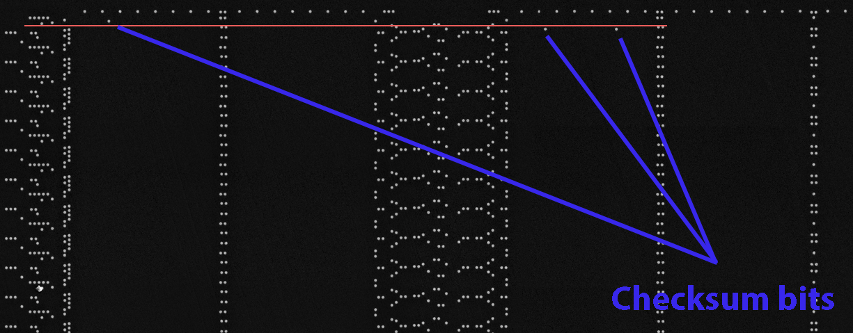
Surprisingly, more than 40% of job postings reveal relatively sensitive information, such as the following, which are just a sample of the information obtained from a variety of companies:
As you can see, a variety of information is disclosed inadvertently in these job postings:
Exact version of the software used in the backend or by end users
Programming languages, frameworks and libraries used
Cloud Service Providers where customer data resides
Intranet and collaborative software used within the company
Antivirus and endpoint security software in use
Industry-specific and third-party software used
Databases, storage and backup, and recovery platforms used
Business relationships with other companies
Security controls implemented in the company’s SDLC
Armed with this information, one can simply connect the data dots and infer things like:
Whether a company uses proprietary or open-source software, implying the use of other similar proprietary/open-source applications that could be targeted in an attack.
Whether a company performs Threat Modeling and follows a secure SDCL, providing an attacker with a vague idea of whether the in-house-developed applications are secure or not.
Whether a company has business relationship with other companies, enabling an attacker to target third-party companies in order to use them as pivot to attack the targeted company.
In summary, IOActive strongly encourages recruiters not to include sensitive information other than that required by the job position – in attempting to precisely target the exact candidate for a job, the level of detail you use could be costly.
The interconnected nature of modern technology means that, by default, even small vulnerabilities can lead to catastrophic losses. And it’s not just about finances. Unmitigated risk raises the specter of eroded customer confidence and tainted brand reputation. In this comprehensive guide, we’ll give enterprise defenders a holistic, methodical, checklist-style approach to cybersecurity risk management. We’ll focus on practical applications, best practices, and ready-to-implement strategies designed to mitigate risks and safeguard digital assets against ever-more numerous—and increasingly capable—threats and adversaries.
What is Cybersecurity Risk Management?
This subspecialty of enterprise risk management describes a systematic approach to identifying, analyzing, evaluating, and addressing cyber threats to an organization’s assets and operations. At its core, it involves a continuous cycle of risk assessment, risk decision-making, and the implementation of risk controls intended to minimize the negative impact of cyber incidents.
Getting control over cyber risk is quickly becoming a core requirement for businesses operating in today’s digital ubiquity. The proliferation of digital information and internet connectivity have paved the way for sophisticated cyber threats that can penetrate many of our most robust defenses. With the digital footprint of businesses expanding exponentially, the potential for data breaches, ransomware attacks, and other forms of cybercrime has escalated dramatically.
These incidents can result in devastating financial losses, legal repercussions, and irreparable damage to an organization’s reputation. Furthermore, as regulatory frameworks around data protection become more stringent, failure to comply can lead to significant penalties. Given these conditions, an aggressive and comprehensive approach to managing cybersecurity risks is crucial for safeguarding an organization’s assets, ensuring operational continuity, and maintaining trust with customers and stakeholders.
Effective Cyber Risk Management: A Framework-Based Approach
Adopting a structured, framework-based approach to cybersecurity risk management lets security teams corral the complexity of digital environments with a methodical, strategic mitigation methodology. For most enterprise applications, there’s no need to reinvent the wheel. There are a myriad of established frameworks that can be modified and customized for effective use in nearly any environment.
Perhaps the best known is the National Institute of Standards and Technology (NIST) Risk Management Framework (RMF), a companion to NIST’s well-tested and widely implemented Cybersecurity Framework (CSF). The NIST RMF offers a structured and systematic approach for integrating security, privacy, and risk management processes into an organization’s system development life cycle.
Such frameworks provide a comprehensive set of guidelines that help identify and assess cyber threats and facilitate the development of effective strategies to mitigate these risks. By standardizing cybersecurity practices, organizations can ensure a consistent and disciplined application of security measures across all departments and operations.
This coherence and uniformity are crucial for effectively addressing vulnerabilities and responding to incidents promptly. Equally important, frameworks incorporate best practices and benchmarks that help guide organizations toward achieving compliance with regulatory requirements, thus minimizing legal risks and enhancing the safeguarding of customer data. In essence, a framework-based approach offers a clear roadmap for managing cyber risk in a way that’s aligned with organizational strategic objectives and industry standards.
What follows is a checklist based on the 7-step RMF process. This is just a starting point. A framework to-do list like this can and should be tweaked to aid in reducing and managing specific cyber risks in your unique enterprise environment.
1. Preparation
In this initial phase, organizations focus on establishing the context and priorities for the Risk Management Framework process. This involves identifying critical assets, defining the boundaries, and codifying a risk management strategy that aligns with the organization’s objectives and resources. This is the foundation upon which a tailored approach to managing cybersecurity risk will ultimately be built throughout the system’s lifecycle.
Establish the context for risk management and create a risk management strategy.
Define roles and responsibilities across the organization.
Develop a taxonomy for categorizing information and information systems.
Determine the legal, regulatory, and contractual obligations.
Prepare an inventory of system elements, including software and hardware.
2. Systems Categorization
Expanding on the categorization step (above), this phase involves identifying the types of information processed, stored, and transmitted to determine potential impact as measured against the information security CIA triad (confidentiality, integrity, and availability). Organizations can assign appropriate security categories to their systems by leveraging a categorization standard such as the Federal Information Processing Standard (FIPS) 199, ensuring that the protective measures taken are tailored to the specific needs and risks associated with the information being handled. This step is crucial as it lays the groundwork for selecting suitable security controls in the later stages of the risk management process.
Identify the types of information processed, stored, and transmitted by the system.
Assess the potential impact of loss of Confidentiality, Integrity, and Availability (CIA) associated with each type.
Document findings in a formal security categorization statement.
3. Selecting Appropriate Security Controls
This critical step begins the safeguarding of information systems against potential threats and vulnerabilities in earnest. Based on the categorization of the information system, organizations select a baseline of security and privacy controls (NIST Special Publication 800-53 or some equivalent controls standard is a good starting point here), corresponding to the system’s impact level. This baseline acts as the jumping-off point for the security controls, which can be tailored to address the specific risks identified throughout the risk assessment process. Customization involves adding, removing, or modifying controls to ensure a robust defense tailored to the unique requirements and challenges of the organization.
Select an appropriate baseline of security controls (NIST SP 800-53 or equivalent).
Tailor the baseline controls to address specific organizational needs and identified risks.
Document the selected security controls in the system security plan.
Develop a strategy for continuously monitoring and maintaining the effectiveness of security controls.
4. Implementing the Selected Controls
Implementing security controls involves the physical and technical application of measures chosen during the previous selection phase. This step requires careful execution to ensure all controls are integrated effectively within the environment, aligning with its architecture and operational practices. Documenting the implementation details is crucial to provide a reference for future assessments and maintenance activities.
Implement the security controls as documented in Step 3.
Document the security controls and the responsible entities in place.
Test thoroughly to ensure compatibility and uninterrupted functionality.
Prepare for security assessment by documenting the implementation details.
5. Assessing Controls Performance
Assessing security controls involves evaluating effectiveness and adherence to the security requirements outlined in the overall security plan. This phase is critical for identifying any control deficiencies or weaknesses that could leave the information system vulnerable. Independent reviewers or auditors typically conduct assessments to ensure objectivity and a comprehensive analysis.
Develop and implement a plan to assess the security controls.
Perform security control assessments as per the plan.
Prepare a Security Assessment Report (SAR) detailing the effectiveness of the controls.
Determine if additional controls are needed and append the master security plan accordingly.
6. Authorizing the Risk Management Program
The authorization phase is a vital decision-making interval where one or more senior executives evaluate the security controls’ assessment results and decide whether the remaining risks to the information systems are acceptable to the organization. Upon acceptance, authorization is granted to operate the mitigation program for a specific time period, during which its compliance and security posture are continuously monitored. This authorization is formalized through the issuance of what is known as an Authorization to Operate (ATO) in some organizations, particularly in the public sector.
Compile the required authorization package, including the master plan, the SAR, and the so-called Plan of Action and Milestones (POA&M).
Assess the residual risk against the organizational risk tolerance.
Document the authorization decision in an Authorization Decision Document.
7. Monitoring and Measuring Against Performance Metrics
The monitoring phase ensures that all implemented security controls remain effective and compliant over time. Continuous surveillance, reporting, and analysis can promptly address any identified vulnerabilities or changes in the operational environment. This ongoing process supports the kind of flexible, adaptive security posture necessary for dealing with evolving threats while steadfastly maintaining the integrity and availability of the information system.
Implement the plan for ongoing monitoring of security controls.
Report the system’s security state to designated leaders in the organization.
Perform ongoing risk assessments and response actions, updating documentation as necessary.
Conduct reviews and updates regularly, in accordance with the organizational timelines, or as significant changes occur.
Conclusion: Formalizing Cyber Risk Mitigation
A solid risk management framework provides a comprehensive guide for enhancing the security and resilience of information systems through a structured process of identifying, implementing, and monitoring security controls.
Sticking to a framework checklist helps ensure a successful, systematic adoption. As noted throughout, engaging stakeholders from across the organization, including IT, security, operations, and compliance, is critical to ensuring a truly comprehensive risk management program. Additionally, periodic training and awareness for team members involved in various phases of the risk management project will contribute to the resilience and security of the organization’s digital assets.
Organizations can effectively safeguard their digital assets and mitigate unacceptable risks by following the outlined steps, tailoring the program to fit specific organizational needs, involving stakeholders, conducting regular training, and adapting to the evolving cybersecurity landscape. Ultimately, this kind of formal, structured cyber risk management fosters a culture of continuous improvement and vigilance in an enterprise, contributing to the overall security posture and the success of the organization.
INSIGHTS, RESEARCH | July 25, 2024
5G vs. Wi-Fi: A Comparative Analysis of Security and Throughput Performance
By
Ethan Shackelford
& Vince Marcovecchio
Introduction
In this blog post we compare the security and throughput performance of 5G cellular to that of WiFi. This work is part of the research IOActive published in a recent whitepaper (https://bit.ly/ioa-report-wifi-5g), which was commissioned by Dell. We used a Dell Latitude 7340 laptop as an end-user wireless device, a Panda Wireless® PAU06 as a WiFi access point, and an Ettus Research™ Universal Software Radio Peripheral (USRP™) B210 as a 5G base station to simulate a typical standalone 5G configuration and three typical WiFi network configurations (home, public, and corporate). Testing was performed between January and February 2024 during which we simulated a number of different attacks against these networks and measured performance-based results for a number of different real-world environments.
Security Tests
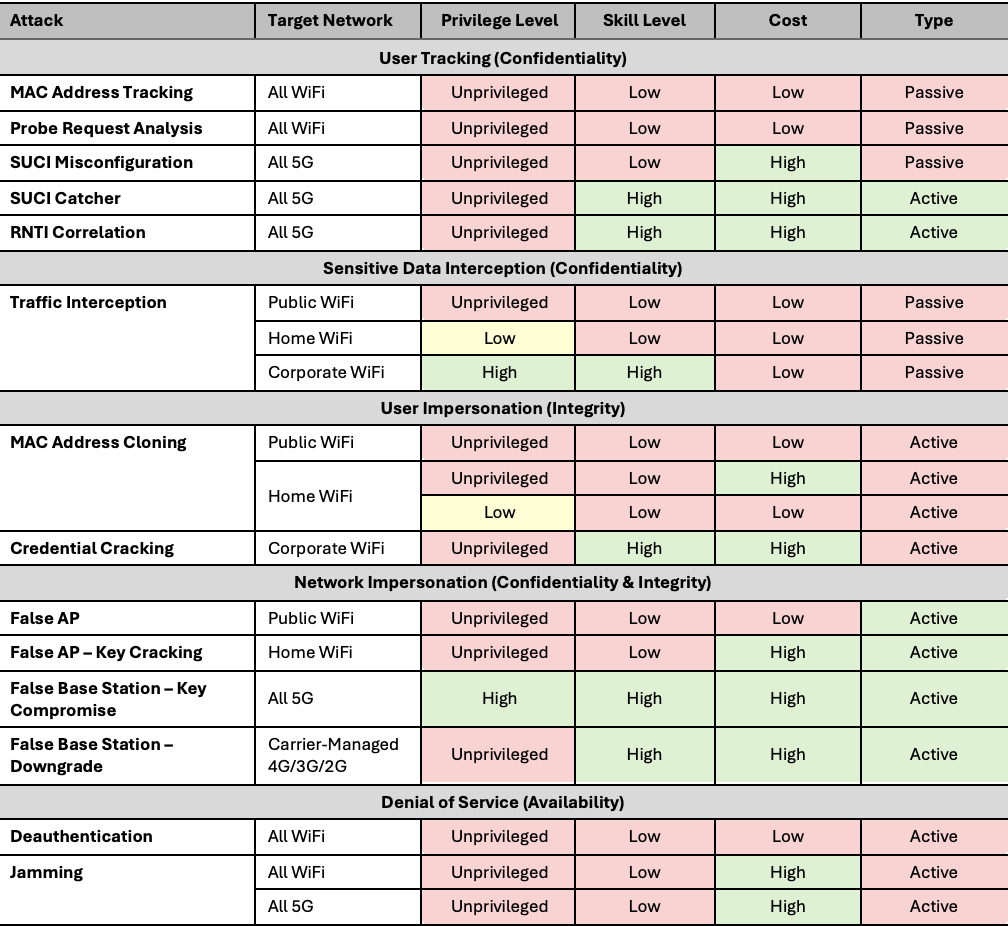
We researched known 5G and WiFi attacks and grouped them according to five different goals: user tracking, sensitive data interception, user impersonation, network impersonation, and denial of service. These goals easily map to the classic Confidentiality, Integrity, Availability (CIA) security triad. We then reproduced the attacks against our controlled test networks to better understand their requirements, characteristics, and impact. The results of these investigations are summarized below:
We noted that, in general, the 5G protocol was designed from the ground up to provide several assurances that the WiFi protocol does not provide. Although mitigations are available to address some of the attacks, WiFi is still unable to match the level of assurance provided by 5G.
For example, 5G protects against user tracking by using concealed identifiers. Attacks to bypass these identifiers are easily detectable and require highly skilled and well-funded attackers. In contrast, WiFi does not attempt to protect against user tracking, since MAC addresses are transmitted in plaintext with every packet. Although modern devices have tried to mitigate this risk by introducing MAC address randomization, passive user tracking is still easy to accomplish due to shortcomings in MAC address randomization and probe request analysis.
IOActive also noted that the use of layered security protocols mitigated most sensitive data interception and network impersonation attacks. Although the majority of users do not use a VPN when connecting to the Internet, most websites use TLS, which, when combined with HSTS and browser preload lists, effectively prevents an attacker from intercepting most of the sensitive data a user might access online. However, even multiple layered security protocols cannot protect against vulnerabilities in the underlying radio protocol. For example, a WiFi deauthentication attack would not be affected in any way by the use of TLS or a VPN.
Performance Tests
We conducted performance tests by measuring throughput and latency from a wireless device in a variety of environments, ranging from urban settings with high spectrum noise and many physical obstacles, to rural areas where measurements more closely reflected the attributes of the underlying radio protocol.
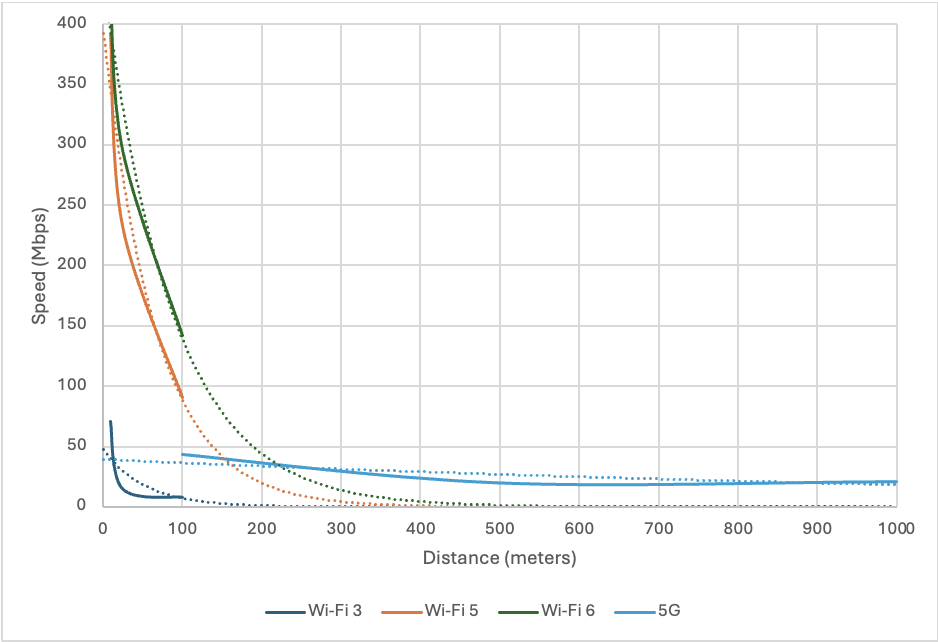
Of particular note, we found that a wireless device could maintain a connection to a 5G wireless base over a significant distance, even with substantial interference from buildings and other structures in an urban environment.
In a rural environment, our WiFi testing showed an exponential decay with distance, as was expected, and it was not possible to maintain a connection over the same range as with 5G. We did, however, note significantly higher speeds from WiFi connections at close proximity:
Surprisingly, we did not see significant changes in latency or error rates during our testing.
Conclusions
The following network security spectrum summarizes our findings:
This spectrum provides a high-level overview of network types, from less secure to more secure, based on the characteristics we observed and documented in our whitepaper. The use of layered security mechanisms moves any network towards the more secure end of the spectrum.
Overall, we found that a typical standalone 5G network is more resilient against attacks than a typical WiFi network and that 5G provided a more reliable connection than WiFi, even over significant distances; however, WiFi provided much higher speeds when the wireless device was in close proximity to the wireless access point.
WiFi and 5G: Security and Performance Characteristics Whitepaper
By
Ethan Shackelford
& Vince Marcovecchio
IOActive compared the security and performance of the WiFi and 5G wireless protocols by simulating several different network types and reproducing attacks from current academic research in a Dell-commissioned study. In total, 536 hours of testing was performed between January and February 2024 comparing each technologies’ susceptibility to five categories of attack: user tracking, sensitive data interception, user impersonation, network impersonation, and denial of service.
IOActive concluded that a typical standalone 5G network is more resilient against the five categories of attack than a typical WiFi network. Attacks against a 5G network generally had higher skill, cost, and effort requirements than equivalent attacks against a WiFi network.
Our performance comparison was based on measuring throughput and latency in several different urban and rural settings. We found that although WiFi supported significantly higher speeds than 5G at close proximity, 5G provided a more reliable connection over greater distances.
The Security Imperative in Artificial Intelligence
By
Gunter Ollmann
Artificial Intelligence (AI) is transforming industries and everyday life, driving innovations once relegated to the realm of science fiction into modern reality. As AI technologies grow more integral to complex systems like autonomous vehicles, healthcare diagnostics, and automated financial trading platforms, the imperative for robust security measures increases exponentially.
Securing AI is not only about safeguarding data but also about ensuring the core systems — in particular, the trained models that really put the “intelligence” in AI — function as intended without malicious interference. Historical lessons from earlier technologies offer some guidance and can be used to inform today’s strategies for securing AI systems. Here, we’ll explore the evolution, current state, and future direction of AI security, with a focus on why it’s essential to learn from the past, secure the present, and plan for a resilient future.
AI: The Newest Crown Jewel
Security in the context of AI is paramount precisely because AI systems increasingly handle sensitive data, make important, autonomous decisions, and operate with limited supervision in critical environments where safety and confidentiality are key. As AI technologies burrow further into sectors like healthcare, finance, and national security, the potential for misuse or harmful consequences due to security shortcomings rises to concerning levels. Several factors drive the criticality of AI security:
Data Sensitivity: AI systems process and learn from large volumes of data, including personally identifiable information, proprietary business information, and other sensitive data types. Ensuring the security of enterprise training data as it passes to and through AI models is crucial to maintaining privacy, regulatory compliance, and the integrity of intellectual property.
System Integrity: The integrity of AI systems themselves must be well defended in order to prevent malicious alterations or tampering that could lead to bogus outputs and incorrect decisions. In autonomous vehicles or medical diagnosis systems, for example, instructions issued by compromised AI platforms could have life-threatening consequences.
Operational Reliability: AI is increasingly finding its way into critical infrastructure and essential services. Therefore, ensuring these systems are secure from attacks is vital for maintaining their reliability and functionality in critical operations.
Matters of Trust: For AI to be widely adopted, users and stakeholders must trust that the systems are secure and will function as intended without causing unintended harm. Security breaches or failures can undermine public confidence and hinder the broader adoption of emerging AI technologies over the long haul.
Adversarial Activity: AI systems are uniquely susceptible to certain attacks, whereby slight manipulations in inputs — sometimes called prompt hacking — can deceive an AI system into making incorrect decisions or spewing malicious output. Understanding the capabilities of malicious actors and building robust defenses against such prompt-based attacks is crucial for the secure deployment of AI technologies.
In short, security in AI isn’t just about protecting data. It’s also about ensuring safe, reliable, and ethical use of AI technologies across all applications. These inexorably nested requirements continue to drive research and ongoing development of advanced security measures tailored to the unique challenges posed by AI.
Looking Back: Historical Security Pitfalls
We don’t have to turn the clock back very far to witness new, vigorously hyped technology solutions wreaking havoc on the global cybersecurity risk register. Consider the peer-to-peer recordkeeping database mechanism known as blockchain. When blockchain exploded into the zeitgeist circa 2008 — alongside the equally disruptive concept of cryptocurrency — its introduction brought great excitement thanks to its potential for both decentralization of data management and the promise of enhanced data security. In short order, however, events such as the DAO hack —an exploitation of smart contract vulnerabilities that led to substantial, if temporary, financial losses — demonstrated the risk of adopting new technologies without diligent security vetting.
As a teaching moment, the DAO incident highlights several issues: the complex interplay of software immutability and coding mistakes; and the disastrous consequences of security oversights in decentralized systems. The case study teaches us that with every innovative leap, a thorough understanding of the new security landscape is crucial, especially as we integrate similar technologies into AI-enabled systems.
Historical analysis of other emerging technology failures over the years reveals other common themes, such as overreliance on untested technologies, misjudgment of the security landscape, and underestimation of cyber threats. These pitfalls are exacerbated by hype-cycle-powered rapid adoption that often outstrips current security capacity and capabilities. For AI, these themes underscore the need for a security-first approach in development phases, continuous vulnerability assessments, and the integration of robust security frameworks from the outset.
Current State of AI Security
With AI solutions now pervasive, each use case introduces unique security challenges. Be it predictive analytics in finance, real-time decision-making systems in manufacturing systems, or something else entirely, each application requires a tailored security approach that takes into account the specific data types and operational environments involved. It’s a complex landscape where rapid technological advancements run headlong into evolving security concerns. Key features of this challenging infosec environment include:
Advanced Threats: AI systems face a range of sophisticated threats, including data poisoning, which can skew an AI’s learning and reinforcement processes, leading to flawed outputs; model theft, in which proprietary intellectual property is exposed; and other adversarial actions that can manipulate AI perceptions and decisions in unexpected and harmful ways. These threats are unique to AI and demand specialized security responses that go beyond traditional cybersecurity controls.
Regulatory and Compliance Issues: With statutes such as GDPR in Europe, CCPA in the U.S., and similar data security and privacy mandates worldwide, technology purveyors and end users alike are under increased pressure to prioritize safe data handling and processing. On top of existing privacy rules, the Biden administration in the U.S. issued a comprehensive executive order last October establishing new standards for AI safety and security. In Europe, meanwhile, the EU’s newly adopted Artificial Intelligence Act provides granular guidelines for dealing with AI-related risk. This spate of new rules can often clash with AI-enabled applications that demand more and more access to data without much regard for its origin or sensitivity.
Integration Challenges: As AI becomes more integrated into critical systems across a wide swath of vertical industries, ensuring security coherence across different platforms and blended technologies remains a significant challenge. Rapid adoption and integration expose modern AI systems to traditional threats and legacy network vulnerabilities, compounding the risk landscape.
Explainability: As adoption grows, the matter of AI explainability — or the ability to understand and interpret the decisions made by AI systems — becomes increasingly important. This concept is crucial in building trust, particularly in sensitive fields like healthcare where decisions can have profound impacts on human lives.Consider an AI system used to diagnose disease from medical imaging. If such a system identifies potential tumors in a scan, clinicians and patients must be able to understand the basis of these conclusions to trust in their reliability and accuracy. Without clear explanations, hesitation to accept the AI’s recommendations ensues, leading to delays in treatment or disregard of useful AI-driven insights. Explainability not only enhances trust, it also ensures AI tools can be effectively integrated into clinical workflows, providing clear guidance that healthcare professionals can evaluate alongside their own expertise.
Addressing such risks requires a deep understanding of AI operations and the development of specialized security techniques such as differential privacy, federated learning, and robust adversarial training methods. The good news here: In response to AI’s risk profile, the field of AI security research and development is on a steady growth trajectory. Over the past 18 months the industry has witnessed increased investment aimed at developing new methods to secure AI systems, such as encryption of AI models, robustness testing, and intrusion detection tailored to AI-specific operations.
At the same time, there’s also rising awareness of AI security needs beyond the boundaries of cybersecurity organizations and infosec teams. That’s led to better education and training for application developers and users, for example, on the potential risks and best practices for securing A-powered systems.
Overall, enterprises at large have made substantial progress in identifying and addressing AI-specific risk, but significant challenges remain, requiring ongoing vigilance, innovation, and adaptation in AI defensive strategies.
Data Classification and AI Security
One area getting a fair bit of attention in the context of safeguarding AI-capable environments is effective data classification. The ability to earmark data (public, proprietary, confidential, etc.) is essential for good AI security practice. Data classification ensures that sensitive information is handled appropriately within AI systems. Proper classification aids in compliance with regulations and prevents sensitive data from being used — intentionally or unintentionally — in training datasets that can be targets for attack and compromise.
The inadvertent inclusion of personally identifiable information (PII) in model training data, for example, is a hallmark of poor data management in an AI environment. A breach in such systems not only compromises privacy but exposes organizations to profound legal and reputational damage as well. Organizations in the business of adopting AI to further their business strategies must be ever aware of the need for stringent data management protocols and advanced data anonymization techniques before data enters the AI processing pipeline.
The Future of AI Security: Navigating New Horizons
As AI continues to evolve and tunnel its way further into every facet of human existence, securing these systems from potential threats, both current and future, becomes increasingly critical. Peering into AI’s future, it’s clear that any promising new developments in AI capabilities must be accompanied by robust strategies to safeguard systems and data against the sophisticated threats of tomorrow.
The future of AI security will depend heavily on our ability to anticipate potential security issues and tackle them proactively before they escalate. Here are some ways security practitioners can prevent future AI-related security shortcomings:
Continuous Learning and Adaptation: AI systems can be designed to learn from past attacks and adapt to prevent similar vulnerabilities in the future. This involves using machine learning algorithms that evolve continuously, enhancing their detection capabilities over time.
Enhanced Data Privacy Techniques: As data is the lifeblood of AI, employing advanced and emerging data privacy technologies such as differential privacy and homomorphic encryption will ensure that data can be used for training without exposing sensitive information.
Robust Security Protocols: Establishing rigorous security standards and protocols from the initial phases of AI development will be crucial. This includes implementing secure coding practices, regular security audits, and vulnerability assessments throughout the AI lifecycle.
Cross-Domain Collaboration: Sharing knowledge and strategies across industries and domains can lead to a more robust understanding of AI threats and mitigation strategies, fostering a community approach to AI security.
Looking Further Ahead
Beyond the immediate horizon, the field of AI security is set to witness several meaningful advancements:
Autonomous Security: AI systems capable of self-monitoring and self-defending against potential threats will soon become a reality. These systems will autonomously detect, analyze, and respond to threats in real time, greatly reducing the window for attacks.
Predictive Security Models: Leveraging big data and predictive analytics, AI can forecast potential security threats before they manifest. This proactive approach will allow organizations to implement defensive measures in advance.
AI in Cybersecurity Operations: AI will increasingly become both weapon and shield. AI is already being used to enhance cybersecurity operations, providing the ability to sift through massive amounts of data for threat detection and response at a speed and accuracy unmatchable by humans. The technology and its underlying methodologies will only get better with time. This ability for AI to remove the so-called “human speed bump” in incident detection and response will take on greater importance as the adversaries themselves increasingly leverage AI to generate malicious attacks that are at once faster, deeper, and potentially more damaging than ever before.
Decentralized AI Security Frameworks: With the rise of blockchain technology, decentralized approaches to AI security will likely develop. These frameworks can provide transparent and tamper-proof systems for managing AI operations securely.
Ethical AI Development: As part of securing AI, strong initiatives are gaining momentum to ensure that AI systems are developed with ethical considerations in mind will prevent biases and ensure fairness, thus enhancing security by aligning AI operations with human values.
As with any rapidly evolving technology, the journey toward a secure AI-driven future is complex and fraught with challenges. But with concerted effort and prudent innovation, it’s entirely within our grasp to anticipate and mitigate these risks effectively. As we advance, the integration of sophisticated AI security controls will not only protect against potential threats, it will foster trust and promote broader adoption of this transformative technology. The future of AI security is not just about defense but about creating a resilient, reliable foundation for the growth of AI across all sectors.
Charting a Path Forward in AI Security
Few technologies in the past generation have held the promise for world-altering innovation in the way AI has. Few would quibble with AI’s immense potential to disrupt and benefit human pursuits from healthcare to finance, from manufacturing to national security and beyond. Yes, Artificial Intelligence is revolutionary. But it’s not without cost. AI comes with its own inherent collection of vulnerabilities that require vigilant, innovative defenses tailored to their unique operational contexts.
As we’ve discussed, embracing sophisticated, proactive, ethical, collaborative AI security and privacy measures is the only way to ensure we’re not only safeguarding against potential threats but also fostering trust to promote the broader adoption of what most believe is a brilliantly transformative technology.
The journey towards a secure AI-driven future is indeed complex and fraught with obstacles. However, with concerted effort, continuous innovation, and a commitment to ethical practices, successfully navigating these impediments is well within our grasp. As AI continues to evolve, so too must our strategies for defending it.
Field-Programmable Chips (FPGAs) in Critical Applications – What are the Risks?
What is an FPGA?
Field-Programmable Gate Arrays (FPGAs) are a type of Integrated Circuit (IC) that can be programmed or reprogrammed after manufacturing. They consist of an array of logic blocks and interconnects that can be configured to perform various digital functions. FPGAs are commonly used in applications where flexibility, speed, and parallel processing capabilities are required, such as telecommunications, automotive, aerospace, and industrial sectors.
FPGAs are often found in products that are low volume or demand short turnaround time because they can be purchased off the shelf and programmed as needed without the setup and manufacturing costs and long lead times associated with Application-Specific Integrated Circuits (ASICs). FPGAs are also popular for military and aerospace applications due to the long lifespan of such hardware as compared to typical consumer electronics. The ability to update deployed systems to meet new mission requirements or implement new cryptographic algorithms—without replacing expensive hardware—is valuable.
These benefits come at a cost, however: additional hardware is required to enable reprogramming. An FPGA-based design will use many more transistors than the same design implemented as an ASIC, increasing power consumption and per-device costs.
Implementing a circuit with an FPGA vs an ASIC can also come with security concerns. FPGA designs are compiled to a “bitstream,” a digital representation of the circuit netlist, which must be loaded into the FPGA for it to function. While bitstream formats are generally undocumented by the manufacturer, several projects are working towards open-source toolchains (e.g., Project X-Ray for the Xilinx 7 series) and have reverse engineered the bitstream formats for various devices.
FPGA bitstreams can be loaded in many ways, depending on the FPGA family and application requirements:
Serial or parallel interfaces from an external processor
JTAG from a debug cable attached to a PC
Serial or parallel interfaces to an external flash memory
Separate stacked-die flash memory within the same package as the FPGA
Flash or One-Time-Programmable (OTP) memory integrated into the FPGA silicon itself
In this post, we will focus on Xilinx because it was the first company to make a commercially viable FPGA back in 1985 and continues to be a world leader in the field. AMD acquired Xilinx in 2020 in a deal worth $60 billion, and today they control over 50% of the world’s programmable logic chips.
The Spartan™ 6 family of Xilinx FPGAs offers low-cost and low-power solutions for high-volume applications like displays, military/emergency/civil telecommunications equipment, and wireless routers. Spartan 6 was released in 2009, so these chips are relatively low-tech compared with their successors, the Spartan 7 and Xilinx’s higher end solutions (e.g., the Zynq and Versal families).
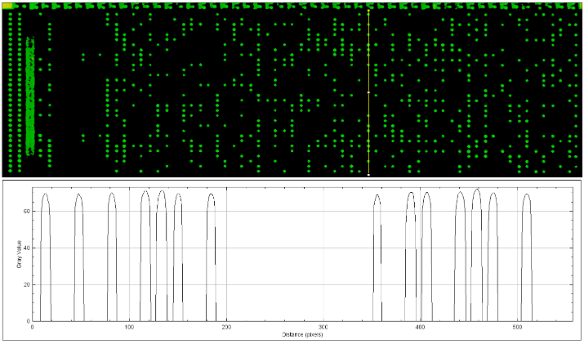
The Spartan 6 bitstream format is not publicly known, but IOActive is aware of at least one research group with unreleased tooling for it. These devices do not contain internal memory, so the bitstream must be provided on external pins each time power is applied and is thus accessible for an attacker to intercept and potentially reverse engineer.
FPGA vendors are, of course, aware of this risk and provide security features, such as allowing bitstreams to be encrypted on external flash and decrypted on the FPGA. In the case of the Spartan 6 family, the bitstream can be encrypted with AES-256 in CBC mode. The key can be stored in either OTP eFuses or battery-backed Static Random Access Memory (SRAM), which enables a self-destruct function where the FPGA can erase the key if it detects tampering.
Since its release in 2012, several researchers have discovered that the radio provides built-in protocols to allow communication across multiple standards, including older analogue Russian radios, UAV commands, and even TETRA. While the advertised frequency range is 27 to 520 MHz, recent firmware updates enabled a lower range of frequencies down to 100 kHz with AM.
The features of this radio are fairly well known. The following was posted by @SomeGumul, a Polish researcher, on Twitter/X:
The trophy in the form of the Russian radio station “Azart”, announced by the Russians as a “native, Russian” sixth-generation device for conducting encrypted conversations, works on American radio components. The basis of the encryption system is, in particular, the Spartan®-6 FPGA (field-programmable gate array) system. It is produced by the American company XILINX (AMD) in Taiwan.
Ironically, despite being advertised as the forefront of Russia’s military technical prowess, the heart of this device was revealed by Ukrainian serviceman Serhii Flash (Сергей Флэш) to be powered by the Spartan 6 FPGA. This FPGA is what enables the handheld radio’s capabilities to be redefined by mere software updates, allowing its users to speak over virtually any radio standard required—past, present, or future. While most of the currently implemented protocols are unencrypted to allow backward compatibility with other older, active service equipment, communication between two AZART radios enables frequency hopping up to 20,000 frequencies per second. This high rate of frequency hopping creates challenges for eavesdropping and position triangulation. The radio’s implementation of TETRA also supports encryption with the inclusion of a supporting radio trunk, where the radio is referred to as being in Trunked Mode Operation (TMO). Otherwise, while in Direct Mode Operation (DMO), the radio only supports voice scrambling in the time and frequency domains.
20,000 frequency hops per second is quite a feat for a radio. Extremely precise timing is required for two or more radios to sync across hops and still communicate clearly. This timing source is gained wirelessly from GPS and GLONASS. As such, this advanced feature can be disabled simply by jamming GPS frequencies.
While this attack may be sufficient, GPS signals are ubiquitous and neutral sources of precise timing that are often required by both sides of any conflict. So, while jamming the frequencies may work in a pinch, it would be cleaner to find a solution to track this high rate of frequency hopping without having to jam a useful signal. To find this solution, we must investigate the proprietary Angstrem algorithm that drives the pseudo-random frequency hopping. To do this, we begin by looking at the likely driver: the Spartan 6 FPGA.
Chipset Overview
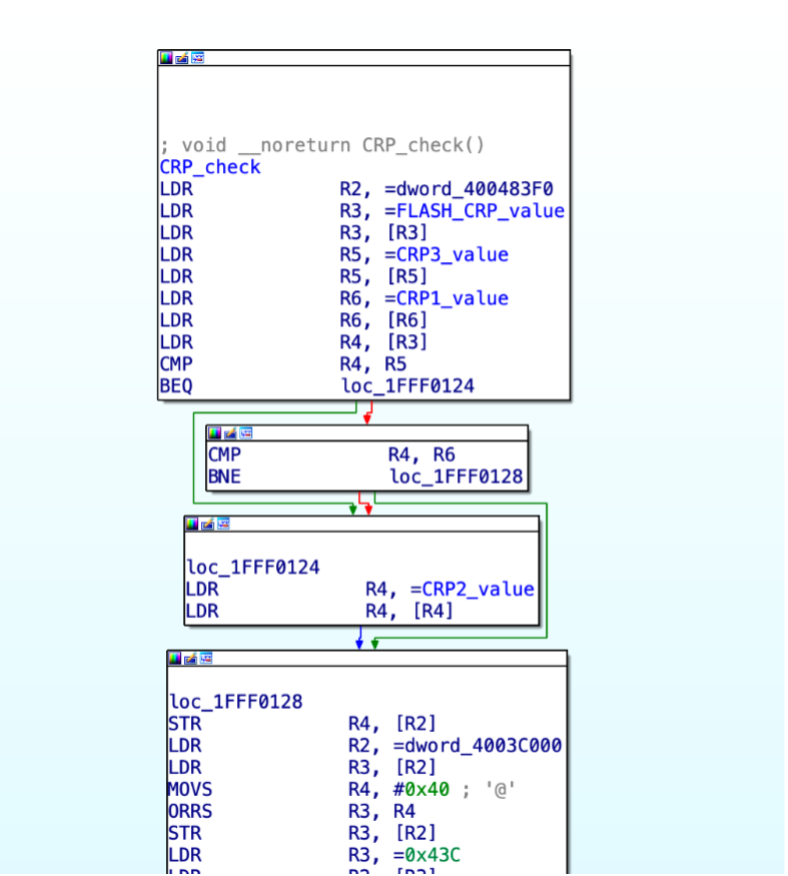
It is currently unknown if the Spartan 6 on the AZART is utilizing an encrypted bitstream; however, due to its wartime purpose, it must not be ruled out. While waiting for the procurement of a functioning radio, IOActive began a preliminary investigation into the functioning of the Spartan 6 with a specific focus on areas related to encryption and decryption of the bitstream.
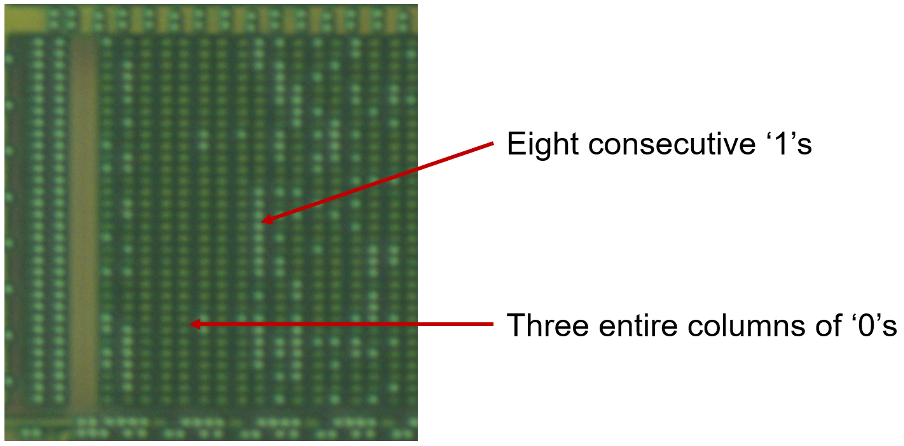
Mainboard of AZART Highlighting the Spartan 6
At the time of writing this post, the XC6SLX75-3CSG484I sells for around $227 from authorized US distributors; however, it can be obtained for much lower prices in Asian markets, with sellers on AliExpress listing them for as low as $8.47. While counterfeits are prevalent in these supply chains, legitimate parts are not difficult to obtain with a bit of luck.
In addition to the FPGA, one other notable component visible on the board is the Analog Devices TxDAC AD9747, a dual 16-bit 250 Msps Digital-to-Analog Converter (DAC) intended for SDR transmitters. Assuming this is being used to transmit I/Q waveforms, we can conclude that the theoretical maximum instantaneous bandwidth of the radio is 250 MHz, with the actual bandwidth likely being closer to 200 MHz to minimize aliasing artifacts.
Device Analysis
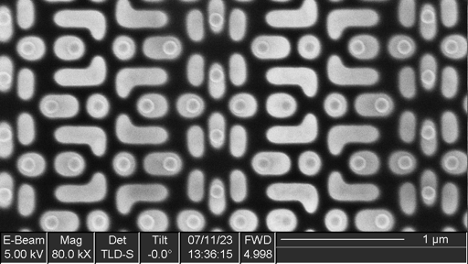
IOActive procured several Spartan 6 FPGAs from a respected supplier for a preliminary silicon teardown to gain insight into how the chip handles encrypted bitstreams and identify any other interesting features. As a standalone package, the Spartan chip looks like this:
The CSG484 package that contains the Spartan 6 is a wire-bonded Ball-Grid Array (BGA) consisting of the IC die itself (face up), attached by copper ball bonds to a four-layer FR4 PCB substrate and overmolded in an epoxy-glass composite. The substrate has a grid of 22×22 solder balls at 0.8 mm pitch, as can be seen in the following cross section. The solder balls are an RoHS-compliant SAC305 alloy, unlike the “defense-grade” XQ6SLX75, which uses Sn-Pb solder balls. The choice of a consumer-grade FPGA for a military application is interesting, and may have been driven by cost or component availability issues (as the XQ series parts are produced in much lower volume and are not common in overseas supply chains).
Spartan 6 Cross Section Material Analysis
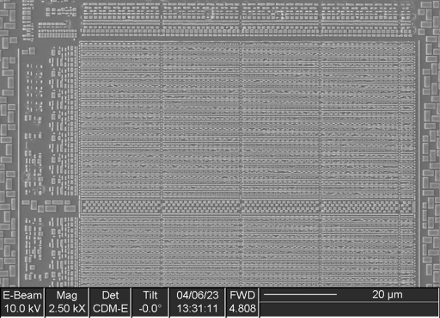
The sample was then imaged in an SEM to gain insight into the metal layers for to order to perform refined deprocessing later. The chip logic exists on the surface of the silicon die, as outlined by the red square in the following figure.
Close-up of FPGA Metal Layers on Silicon Die
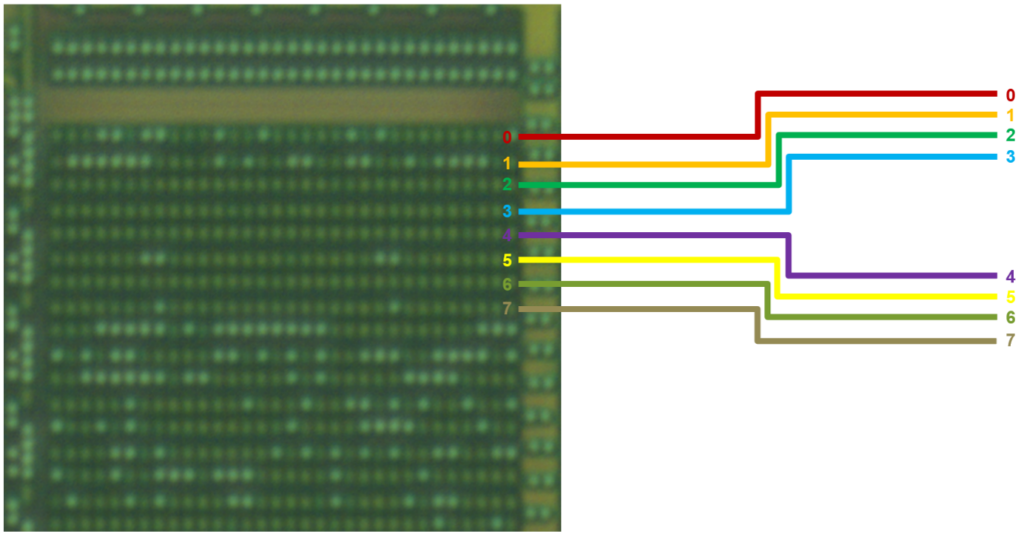
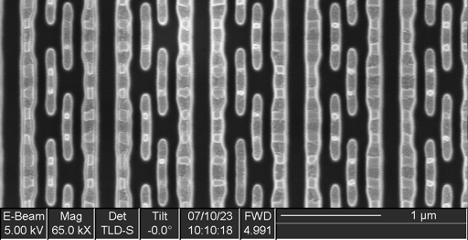
The XC6SLX75 is manufactured by Samsung on a 45 nm process with nine metal layers. A second FPGA was stripped of its packaging for a top-down analysis, starting with metal layer nine.
Optical Overview Image of Decapsulated Die Xilinx XC6SLX75
Looking at the top layer, not much structure is visible, as the entire device is covered by a dense grid of power/ground routing. Wire bond pads around the perimeter for power/ground and I/O pins can clearly be seen. Four identical regions, two at the top and two at the bottom, have a very different appearance from the rest of the device. These are pairs of multi-gigabit serial transceivers, GTPs in Xilinx terminology, capable of operation at up to 3.2 Gbps. The transceivers are only bonded out in the XC6SLX75T; the non –T version used in the radio does not connect them, so we can ignore them for the purposes of this analysis.
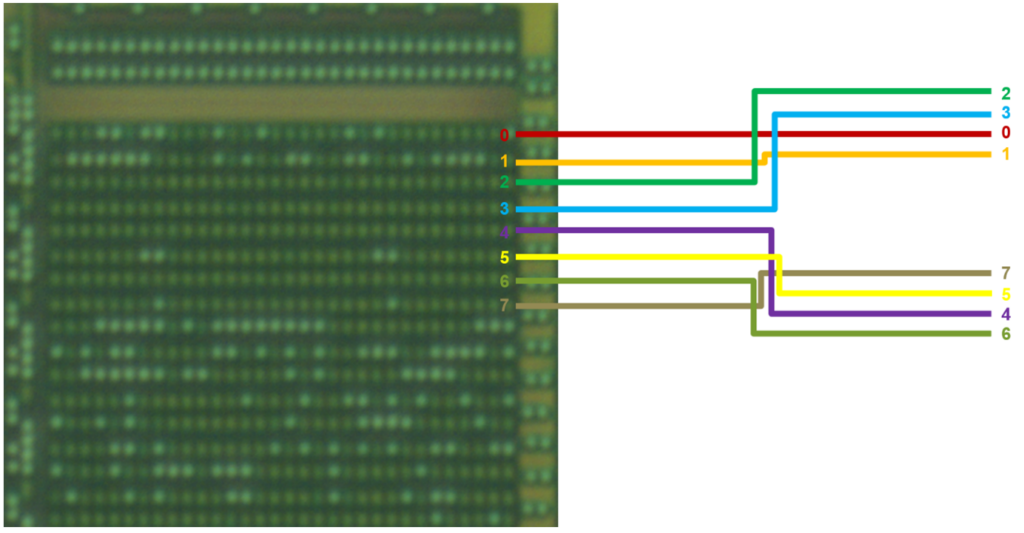
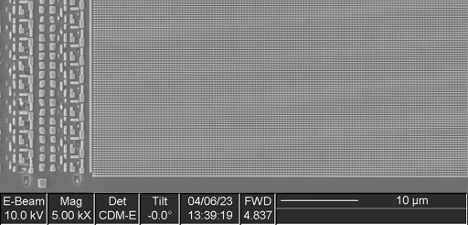
The metal layers were then etched off to expose the silicon substrate layer, which provides better insight into chip layout, as shown in the following figure.
Optical Overview Image of Floorplan of Die Xilinx XC6SLX75
After etching off the metal and dielectric layers, a much clearer view of the device floorplan becomes visible. We can see that the northwest GTP tile has a block of logic just south of it. This is a PCIe gen1 controller, which is not used in the non –T version of the FPGA and can be ignored.
The remainder of the FPGA is roughly structured as columns of identical blocks running north-south, although some columns are shorter due to the presence of the GTPs and PCIe blocks. The non-square logic array of Spartan 6 led to poor performance as user circuitry had to be shoehorned awkwardly around the GTP area. Newer-generation Xilinx parts place the GTPs in a rectangular area along one side of the device, eliminating this issue.
The light-colored column at the center contains clock distribution buffers as well as Phase-Locked Loops (PLLs) and Digital Clock Managers (DCMs) for multiplying or dividing clocks to create different frequencies. Smaller, horizontal clock distribution areas can be seen as light-colored rows throughout the rest of the FPGA.
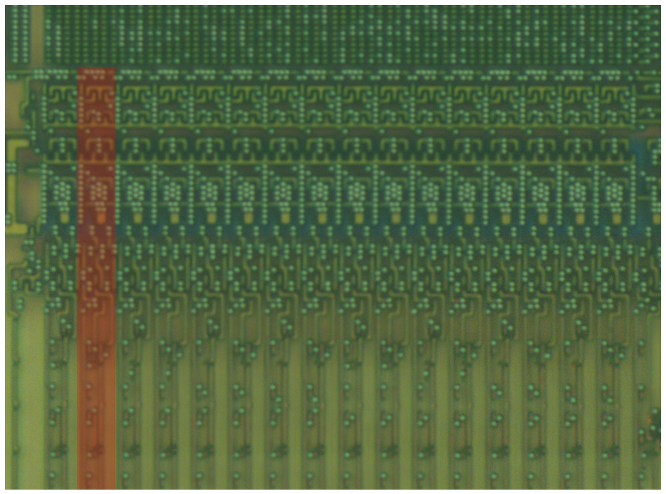
There are four columns of RAM containing a total of 172 tiles of 18 kb, and three columns of DSP blocks containing a total of 132 tiles, each consisting of an 18×18 integer multiplier and some other logic useful for digital signal processing. The remaining columns contain Configurable Logic Blocks (CLBs), which are general purpose logic resources.
The entire perimeter of the device contains I/O pins and related logic. Four light-colored regions of standard cell logic can be seen in the I/O area, two on each side. These are the integrated DDR/DDR2/DDR3 Memory Controller Blocks (MCBs).
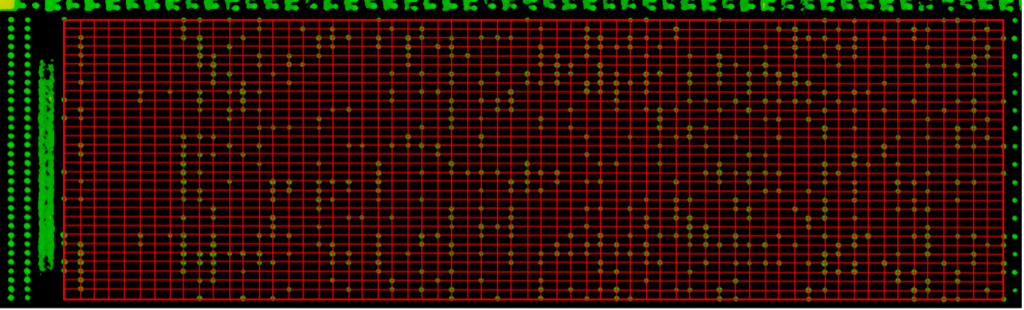
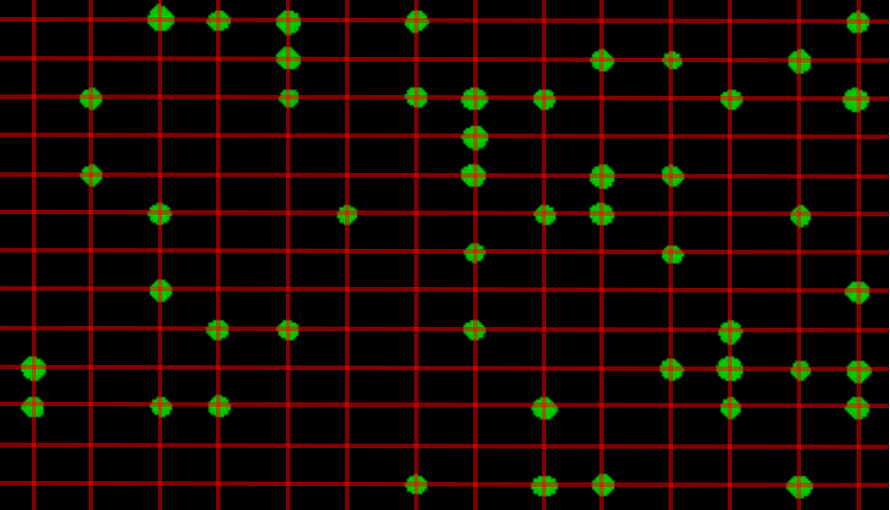
The bottom right contains two larger regions of standard cell logic, which appear related to the boot and configuration process. We expect the eFuse and Battery-Backed SRAM (BBRAM), which likely contain the secrets required to decrypt the bitstream, to be found in this area. As such, this region was scanned in high resolution with the SEM for later analysis.
SEM Substrate Image of Boot/AES Logic Block 1
Utilizing advanced silicon deprocessing and netlist extraction techniques, IOActive hopes to refine methodologies for extracting the configured AES keys required to decrypt the bitstream that drives the Spartan 6 FPGA.
Once this is complete, there is a high probability that the unencrypted bitstream that configures the AZART can be obtained from a live radio and analyzed to potentially enumerate the secret encryption and frequency hopping algorithms that protect the current generation of AZART communications. We suspect that we could also apply this technique to previous generations of AZART, as well as other FPGA-based SDRs like those commonly in use by law enforcement, emergency services, and military operations around the world.
Evolving Cyber Threatscape: What’s Ahead and How to Defend
By
IOActive
The digital world is a dangerous place. And by all accounts, it’s not getting a whole lot better.
Damages from cybercrime will topa staggering $8 trillion this year, up from an already troubling $1 trillion just five years ago and rocketing toward $14 trillion by 2028. Supply chains are becoming juicier targets, vulnerabilities are proliferating, and criminals with nation-state support are growing more active and more sophisticated. Ransomware, cryptojacking, cloud compromises, and AI-powered shenanigans are all on a hockey-stick growth trajectory.
Looking ahead, there are few sure things in infosec other than the stone-cold, lead-pipe lock that systems will be hacked, data will be compromised, money will be purloined, and bad actors will keep acting badly.
Your organization needn’t be a victim, however. Forewarned is forearmed, after all.
Here’s what to expect in the evolving cyber threatscape over the next 12 to 18 months along with some steps every security team can take to stay secure in this increasingly hostile world.
The Weaponization of AI
The Threat: The coming year promises to be a big one for exploiting the ability of AI (artificial intelligence) and Large Language Models (LLMs) to spew misinformation, overwhelm authentication controls, automate malicious coding, and spawn intelligent malware that proactively targets vulnerabilities and evades detection. Generative AI promises to empower any attacker — even those with limited experience or modest resources — with malicious abilities previously limited to experienced users of frameworks like Cobalt Strike or Metasploit.
Expect to see at least some of these new, nefarious generative AI tools offered as a service through underground criminal syndicates, broadening the global cabal of troublesome threat actors while expanding both the population and the richness of available targets.The steady increase in Ransomware-as-a-Service is the clearest indicator to date that such criminal collaboratives are already on the rise.
Particularly ripe for AI-enabled abuse are social engineering-based operations like phishing, business email compromise, and so-called “pig butchering” investment, confidence and romance scams. Generative AI is eerily adept at turning out convincing, persuasive text, audio, and video content with none of the spelling, grammar, or cultural errors that traditionally made such hack attempts easy to spot. Add the LLMs ability to ingest legitimate business communications content for repurposing and translation and it’s easy to see how AI will soon be helping criminals craft super-effective global attacks on an unprecedented scale.
The Response: On a positive note, AI, as it turns out, can play well on both sides of the ball: offense and defense.
AI is already proving its worth, bolstering intelligent detection, response, and mitigation tools. AI-powered security platforms can analyze, model, learn, adapt, and act with greater speed and capacity than any human corps of security analysts ever could. Security professionals need to skill-up now on the techniques used to develop AI-powered attacks with the goal of creating equally innovative and effective mitigations and controls.
And because this new generation of smart malware will make the targeting of unmitigated vulnerabilities far more efficient, the basic infosec blocking and tackling — diligent asset inventory, configuration management, patching — will be more critical than ever.
Clouds Spawn Emerging Threats
The Threat: Business adoption of cloud computing technology has been on a steady rise for more than a decade. The current macroeconomic climate, with all of its challenges and uncertainty, promises to accelerate that trend for at least the next few years. Today, more than four in ten enterprises say they are increasing their use of cloud-based products and services and about one-third plan to continue migrating from legacy software to cloud-based tools this year. A similar share is moving on-premises workloads in the same direction.
Good for business. However, the cloud transformation revolution is not without its security pitfalls.
The cloud’s key benefits — reduced up-front costs, operational vs. capital expenditure, improved scalability and efficiency, faster deployment, and streamlined management — are counterbalanced by cloud-centric security concerns. The threatscape in the era of cloud is dotted with speed bumps like misconfigurations, poor coding practices, loose identity and access controls, and a pronounced lack of detailed environmental visibility. All of this is compounded by a general dearth of cloud-specific security expertise on most security teams.
One area to watch going forward: Better than half of enterprise IT decision-makers now describe their cloud strategy as primarily hybrid cloud or primarily multi-cloud. Three-quarters use multiple cloud vendors. Criminals are taking note. Attacks targeting complex hybrid and multi-cloud environments — with their generous attack surface and multiple points of entry — are poised to spike.
The recent example of azero-day exploited by Chinese hackers that allowed rogue code execution on guest virtual machines (VMs) shows that attacks in this realm are getting more mature and potentially more damaging. Threat actors are targeting hybrid and multi-cloud infrastructure, looking for ways to capitalize on misconfigurations and lapses in controls in order to move laterally across different cloud systems.
Another area of concern is the increased prevalence of serverless infrastructure in the cloud. The same characteristics that make serverless systems attractive to developers — flexibility, scalability, automated deployment — also make them irresistible to attackers. Already there’s been an uptick in instances of crypto miners surreptitiously deployed on serverless infrastructure. Though serverless generally presents a smaller attack surface than hybrid and multi-cloud infrastructure, giving up visibility and turning over control of the constituent parts of the infrastructure to the cloud service provider (CSP) raises its own set of security problems. Looking ahead, nation-state backed threat actors will almost certainly ramp up their targeting of serverless environments, looking to take advantage of insecure code, broken authentication, misconfigured assets, over-privileged functions, abusable API gateways, and improperly secured endpoints.
The Response: The best advice on securing modern cloud environments in an evolving threatscape begins with diligent adherence to a proven framework like theCenter for Internet Studies’ Critical Security Controls (CIS Controls V8) and the CIS’s companionCloud Security Guide. These prioritized safeguards, regularly updated by an engaged cadre of security community members, offer clear guidance on mitigating the most prevalent cyber-attacks against cloud-based systems and cloud-resident data. As a bonus, the CIS Controls are judiciously mapped to several other important legal, regulatory, and policy frameworks.
Beyond that fundamental approach, some steps cloud defenders can take to safeguard the emerging iterations of cloud infrastructure include:
Embracing the chaos: The big challenge for security teams today is less about current configurations and more about unwinding the sins of the past. Run a network visualization and get arms around the existing mess of poorly managed connections and policy violations. It’s a critical first step toward addressing critical vulnerabilities that put the company and its digital assets at risk.
Skilling Up: Most organizations rely on their existing networking and security teams to manage their expanding multi-cloud and hybrid IT environments. It’s a tall order to expect experts in more traditional IT to adapt to the arcana of multi-cloud without specific instruction and ongoing training. TheCloud Security Alliance offers a wealth of vendor-agnostic training sessions in areas ranging from cloud fundamentals, to architecture, auditing and compliance.
Taking Your Share of Shared Responsibility: The hierarchy of jurisdiction for security controls in a cloud environment can be ambiguous at best and confusing at worst. Add more clouds to the mix, and the lines of responsibility blur even further. While all major cloud providers deliver some basic default configurations aimed at hardening the environment, that’s pretty much where their burden ends. The client is on the hook for securing their share of the system and its data assets. This is especially true in multi-cloud and hybrid environments where the client organization alone must protect all of the points where platforms from various providers intersect. Most experts agree the best answer is a third-party security platform that offers centralized, consolidated visibility into configurations and performance.
Rethinking networking connections: Refactoring can move the needle on security while conserving the performance and capabilities benefits of the cloud. Consider the “minimum viable network” approach, a nod to how cloud can, in practice, turn a packet-switched network into a circuit-switched one. The cloud network only moves packets where users say they can move. Everything else gets dropped. Leveraging this eliminates many security issues like sniffing, ARP cache poisoning, etc. This application-aware schema calls for simply plugging one asset into another, mapping only the communications required for that particular stack, obviating the need for host-based firewalls or network zones.
Once defenders get comfortable with the minimum viable network concept, they can achieve adequate security in even the most challenging hybrid environments. The trick is to start simple and focus on reducing network connections down to the absolute minimum of virtual wires.
Supply Chains in the Crosshairs
The Threat: Because they’re such a central component in a wide variety of business operations — and because they feature complex layers of vendor, supplier, and service provider relationships — supply chains remain a tempting target for attackers. And those attackers are poised to grow more prolific and more sophisticated, adding to their prominence in the overall threatscape.
As global businesses become more dependent on interconnected digital supply chains, the compromise of a single, trusted software component in that ecosystem can quickly cascade into mayhem. Credential theft, malicious code injection, and firmware tampering are all part of the evolving supply-chain threat model. Once a trusted third party is compromised, the result is most often data theft, data wiping, or loss of systems availability via ransomware or denial of service attack. Or all of the above.
Prime examples includethe 2020 SolarWinds hack, in which government-backed Russian attackers inserted malicious code into a software update for SolarWinds popular Orion IT monitoring and management platform. The compromise went undetected for more than a year, even as SolarWinds and its partners continued serving up malicious code to some 30,000 private companies and government agencies. Many of those victims saw their data, systems and networks compromised by the backdoor buried in the bad update before the incident was finally detected and mitigated.
More recently, in the summer of 2023, attackers leveraged a flaw in Progress Software’s widely used MOVEit file transfer client, exposing the data of thousands of organizations and nearly 80 million users. In arguablythe largest supply-chain hack ever recorded, a Russian ransomware crew known as Clop leveraged a zero-day vulnerability in MOVEit to steal data from business and government organizations worldwide. Victims ranged from New York City’s public school system, the state of Maine, and a UK-based HR firm serving major clients such as British Airways and the BBC.
The Response: Given the trajectory, it’s reasonable to assume that supply chain and third-party attacks like the MOVEit hack will grow in both frequency and intensity as part of the threatscape’s inexorable evolution. This puts the integrity and resilience of the entire interconnected digital ecosystem at grave and continuing risk.
To fight back, vendor due diligence (especially in the form of formal vendor risk profiles) is key. Defenders will need to take a proactive stance that combines judicious and ongoing assessment of the security posture of all the suppliers and third-party service providers they deal with. Couple that with strong security controls — compensating ones, if necessary — and proven incident detection and response plans focused on parts of the environment most susceptible to third-party compromise.
These types of attacks will happen again. As the examples above illustrate, leveraging relevant threat intelligence on attack vectors, attacker techniques, and emerging threats should feature prominently in any scalable, adaptable supply chain security strategy.
Dishonorable Mentions
The cybersecurity threatscape isn’t limited to a handful of hot-button topics. Watching the threat environment grow and change over time means keeping abreast of many dozens of evolving risk factors, attack vectors, hacker techniques and general digital entropy. Some of the other issues defenders should stay on top of in this dynamic threat environment include:
Disinfo, misinfo and “deep fakes”: A product of the proliferation of AI, bad-faith actors (and bots that model them) will churn out increasing volumes of disingenuous data aimed at everything from election interference to market manipulation.
Rising hacktivism: Conflicts in Ukraine and Israel illustrate how hacker collabs with a stated political purpose are ramping up their use of DDoS attacks, Web defacements and data leaks. The more hacktivism cyber attacks proliferate — and the more effective they appear — the more likely nation-states will jump in the fray to wreak havoc on targets both civilian and military.
Modernizing malware code: C/C++ has long been the lingua franca of malware. But that is changing. Looking to harness big libraries, easier integration, and a more streamlined programming experience, the new breed of malware developers is turning to languages like Rust and Go. Not only are hackers able to churn their malicious code faster to evade detection and outpace signatures, but the malware they create can be much more difficult for researchers to reverse engineer as well.
Emerging quantum risk: As the quantum computing revolution inches ever closer, defenders can look forward to some significant improvements to their security toolkit. Like AI, quantum computing promises to deliver unprecedented new capabilities for threat intelligence gathering, vulnerability management, and DFIR. But also like AI, quantum has a dark side. Quantum computers can brute force their way through most known cryptographic algorithms. Present-day encryption and password-based protections are likely to prove woefully ineffective in the face of a quantum-powered attack.
Taking Stock of a Changing Threatscape
Yes, the digital world is a dangerous place, and the risks on the horizon of the threatscape can seem daunting. Navigating this challenging terrain forces security leaders to prioritize strong, scalable defenses, the kind that can adapt to emerging technology threats and evolving attack techniques all at once. It’s a multi-pronged approach.
What does it take? Adherence to solid security frameworks, judicious use of threat intelligence, updated response plans, and even tactical efforts like mock drills, penetration tests, and red team exercises can play a role in firming up security posture for an uncertain future.
Perhaps most importantly, fostering a culture of security awareness and training within the organization can be vital for preventing common compromises, from phishing and malware attacks to insider threats, inadvertent data leaks, and more.
Surviving in the evolving cyber threatscape comes down to vigilance, adaptability, and a commitment to constant learning. It’s a daunting task, but with a comprehensive, forward-thinking strategy, it’s possible to stay ahead of the curve.
Untested Is Untrusted: Penetration Tests and Red Teaming Key to Mature Security Strategy
By
IOActive
Organizations need to know how well their defenses can withstand a targeted attack. Red team exercises and penetration tests fit the bill, but which is right for your organization?
Information security at even well-defended enterprises is often a complex mesh of controls, policies, people, and point solutions dispersed across critical systems both inside and outside the corporate perimeter. Managing that murky situation can be challenging for security teams, many of whom are understaffed and forced to simply check as many of the boxes as they can on the organization’s framework of choice and hope for the best.
Even in a known hostile climate replete with ransomware, sophisticated bad actors, and costly data breaches, security teams are often pressured to deploy tools, coordinate with disparate IT teams, then left to stand guard: monitoring, analyzing, patching, responding, and recovering.
This largely reactive posture is table stakes for most defenders, but on its own, it leaves one important question hanging. How well will all these defenses work when bad guys come calling? Like an orchestra of talented musicians that have never had a dress rehearsal, or a well-conditioned team of athletes that have never scrimmaged, it’s difficult to know just how well the group will perform under real-world conditions. In information security in particular, organizations are often unsure if their defenses will hold in an increasingly hostile world–a world with endless vulnerabilities, devastating exploits, and evolving attackers with powerful tools and expanding capabilities.
Security’s Testing Imperative
At its heart, effective security infrastructure is a finely engineered system. Optimizing and maintaining that system can benefit greatly from the typical engineer’s inclination to both build and test. From bird feeders to bridges, sewing machines to skyscrapers, no industrial product survives the journey from design to production without being pushed to its limits – and beyond – to see how it will fare in actual use. Tensile strength, compressive parameters, shear forces, thermal capacity, points of failure, every potential weakness is fair game. The concept of stress testing is common in every engineering discipline. Security should be no exception.
Security systems aren’t subjected to blistering heat, abrasive friction, or crushing weight, of course. But the best ones are regularly probed, prodded, and pushed to their technical limits. To accomplish this, organizations turn to one of two core testing methodologies: the traditional penetration test, and the more robust red team exercise. Both penetration testing and red teaming are proven, well-documented approaches for establishing the effectiveness of an organization’s defenses,
Determining which one is best for a particular organization comes down to understanding how penetration tests and red team exercises work and how they differ in practice, core purpose, and scope.
Penetration Tests (“pentests” for short) are a proactive form of application and infrastructure security evaluation in which an ethical hacker is authorized to scan an organization’s systems to discover weaknesses that could lead to compromise or a data breach. The pentester’s objectives are to identify vulnerabilities in the client environment, exploit them to demonstrate the vulnerability’s impact, and document the findings.
Penetration testing is generally considered the next step up from traditional vulnerability assessments. Vulnerability assessments – usually the product of software-driven, automated scanning and reporting – expose many unaddressed weaknesses by cross-referencing the client’s systems and software with public lists of known vulnerabilities. Penetration testing takes the discipline a step further, adding the expert human element in order to recreate the steps a real cybercriminal might take to compromise systems. Techniques such as vulnerability scanning, brute-force password attacks, web app exploitation, and social engineering can be included in the test’s stated parameters.
Penetration tests are more targeted and deliver a more accurate list of vulnerabilities present than a vulnerability assessment. Because exploitation is often included, the pentest shows client organizations which vulnerabilities pose the biggest risk of damage, helping to prioritize mitigation efforts. Penetration tests are usually contracted with strict guidelines for time and scope — and because internal stakeholders are generally aware the pentest is taking place — provide little value for measuring detection and response and provide no visibility into the security posture of IT assets outside the scope of the examination.
Penetration Testing in Action
Traditional penetration tests are a go-to approach for organizations that want to immediately address exploitable vulnerabilities and upgrade their approach beyond static vulnerability scanning. Pentests provide valuable benefits in use cases such as:
Unearthing hidden risk: Penetration tests identify critical weaknesses in a single system, app or network that automated scanning tools often miss. As a bonus, pentests weed out the false positives from machine scanning that can waste valuable security team resources.
Validating security measures: Penetration testing can help validate the effectiveness of security controls, policies, and procedures, ensuring they work as intended.
Governance and compliance: Penetration testing allows an organization to check and prove that security policies, regulations and other related mandates are being met, including those that explicitly require regular pentests.
Security training: The reported outcome of a penetration testmakes for a valuable training tool for both security teams and end users, helping them understand how vulnerabilities can impact their organization.
Business continuity planning: Penetration testing also supports the organization’s business continuity plan, identifying potential threats and vulnerabilities that could result in system downtime and data loss.
Red Team Exercises: Laser Focus Attacks, Big-Picture Results
Red Teams take a more holistic — and more aggressive — approach to testing an organization’s overall security under real-world conditions. Groups of expert ethical hackers simulate persistent adversarial attempts to compromise the target’s systems, data, corporate offices, and people.
Red team exercises focus on the same tactics, tools, and procedures (TTPs) used by real-world adversaries. Where penetration tests aim to uncover a comprehensive list of vulnerabilities, red teams emulate attacks that focus more on the damage a real adversary could inflict. Weak spots are leveraged to gain initial access, move laterally, escalate privileges, exfiltrate data, and avoid detection. The goal of the red team is really to compromise an organization’s most critical digital assets, its crown jewels. Because the red team’s activities are stealthy and known only to select client executives (and sometimes dedicated “blue team” defenders from the organization’s own security team), the methodology is able to provide far more comprehensive visibility into the organization’s security readiness and ability to stand up against a real malicious attack. More than simply a roster of vulnerabilities, it’s a detailed report card on defenses, attack detection, and incident response that enterprises can use to make substantive changes to their programs and level-up their security maturity.
Red Team Exercises in Action
Red team exercises take security assessments to the next level, challenging more mature organizations to examine points of entry within their attack surface a malicious actor may exploit as well as their detection response capabilities. Red teaming proves its mettle through:
Real-world attack preparation: Red team exercises emulate attacks that can help organizations prepare for the real thing, exposing flaws in security infrastructure, policy, process and more.
Testing incident response: Red team exercises excel at testing a client’s incident response strategies, showing how quickly and effectively the internal team can detect and mitigate the threat.
Assessing employee awareness: In addition to grading the security team,red teaming is also used to measure the security awareness among employees. Through approaches like spear phishing, business email compromise and on-site impersonation, red teams highlight areas where additional employee training is needed.
Evaluating physical security: Red teams go beyond basic cyberthreats, assessing the effectiveness of physical security measures — locks, card readers, biometrics, access policies, and employee behaviors — at the client’s various locations.
Decision support for security budgets: Finally, red team exercises provide solid, quantifiable evidence to support hiring, purchasing and other security-related budget initiatives aimed at bolstering a client’s security posture and maturity
Stress Test Shootout: Red Teams and Penetration Tests Compared
When choosing between penetration tests and red team exercises, comparing and contrasting key attributes is helpful in determining which is best for the organization given its current situation and its goals:
Penetration tests
Red team exercises
Objective
Identify vulnerabilities en masse and strengthen security
Simulate real-world attacks and test incident response
Scope
Tightly defined and agreed upon before testing begins
Goal oriented often encompassing the entire organization’s technical, physical, and human assets
Duration
Typically shorter, ranging from a few days to a few weeks
Longer, ranging from several weeks to a few months
Realism
May not faithfully simulate real-world threats
Designed to closely mimic real-world attack scenarios
Targets
Specific systems or applications
Entire organization, including human, physical, and digital layers
Notification
Teams are notified and aware the test is taking place
Unannounced to mimic real attacks and to test responses
Best for…
Firms just getting started with proactive testing or those that perform limited tests on a regular cycle
Orgs with mature security postures that want to put their defenses the test
It’s also instructive to see how each testing methodology might work in a realistic scenario.
Scenario 1: Pentesting a healthcare organization
Hospitals typically feature a web of interconnected systems and devices, from patient records and research databases to Internet-capable smart medical equipment. Failure to secure any aspect can result in data compromise and catastrophic system downtime that violates patient privacy and disrupts vital services. A penetration test helps unearth a broad array of security weak spots, enabling the hospital to maintain systems availability, data integrity, patient confidentiality and regulatory compliance under mandates such as the Health Insurance Portability and Accountability Act (HIPAA).
A pentest for a healthcare org might focus on specific areas of the hospital’s network or critical applications used to track and treat patients. If there are concerns around network-connected medical equipment and potential impact to patient care, a hardware pentest can uncover critical vulnerabilities an attacker could exploit to gain access, modify medication dosage, and maintain a network foothold. The results from the pentest helps identify high risk issues and prioritize remediation but does little in the way of determining if an organization is ready and capable of responding to a breach.
Scenario 2: Red teaming a healthcare organization
While the pentest is more targeted and limited in scope, a red team exercise against the same healthcare organization includes not only all of the networks and applications, but also the employees and physical locations. Here, red team exercises focus on bypassing the hospital’s defenses to provide valuable insights into how the organization might fare against sophisticated, real-world attackers. These exercises expose technical weaknesses, risky employee behaviors, and process shortcomings, helping the hospital continually bolster its resilience.
The red team performs reconnaissance initially to profile the employees, offices, and external attack surface looking for potential avenues for exploitation and initial access. An unmonitored side entrance, someone in scrubs tailgating a nurse into a secure area, or a harmless-looking spearphish, a red team will exploit any weakness necessary to reach its goals and act on its objectives. The goal may be to access a specific fake patient record and modify the patient’s contact information or the team is expected to exfiltrate data to test the hospital’s network monitoring capabilities. In the end, the healthcare organization will have a better understanding of its readiness to withstand a sophisticated attack and where to improve its defenses and ability to respond effectively.
Simulated Attacks, Authentic Results
In security, as in any other kind of engineered system, without testing there can be no trust. Testing approaches like penetration tests and red team exercises are paramount for modern, digital-centric organizations operating in a hostile cyber environment.
These simulated attack techniques help to identify and rectify technical as well as procedural vulnerabilities, enhancing the client’s overall cybersecurity posture. Taken together, regular penetration tests and red team exercises should be considered integral components of a robust and mature cybersecurity strategy. Most organizations will start with penetration testing to improve the security of specific applications and areas of their network, then graduate up to red team exercises that measure the effectiveness of its security defenses along with detection and response capabilities.
Organizations that prioritize such testing methods will be better equipped to defend against threats, reduce risks, and maintain the trust of their users and customers in today’s challenging digital threatscape.
Bits to Binary to Bootloader to Glitch: Exploiting ROM for Non-invasive Attacks
By
Tony Moor
In this paper, we explore how ROM can be leveraged to perform a non-invasive attack (i.e., voltage glitching) by a relatively unsophisticated actor without a six-figure budget. We begin by explaining what ROM is, why it is used, and how it can be extracted.
What exactly is ROM?
Put simply, Read-Only Memory (ROM) is a type of Non-Volatile Memory (NVM) that is constructed as physical structures within chips. The structures are patterned as ones and zeroes on one, and only one, of several layers of the chip. Why just one? Cost. ROM is real hardware, and making any hardware changes in the layout of a chip is very expensive.
The fact that ROM is physically encoded in a chip makes it uniquely reliable and thus appropriate for critical functions, such as boot code execution. ROM is infinitely more reliable than NVM that relies on an electrical charge, like Flash.
The following table provides a brief overview of memory classes.
Table 1. Summary of memory classes, type, and uses
How can you extract data from ROM?
If there is no protection on the device (i.e., it is embedded on a development board), then it is simple to access the data and dump it as a binary (.bin) file. By doing so, we have essentially extracted the final code, as opposed to the raw bits. This means that the code is in an understandable format (no need to decrypt or descramble) and can be analyzed using standard software reverse engineering tools, like IDA Pro or Binary Ninja, to isolate a weakness in the bootloader.
If the ROM is protected, then there is the option to physically deprocess sample chips (more on that later) and extract the raw bits as ones and zeroes. The process is very skill dependent; however, it is possible to carry out on a shoestring budget depending on the age of the chip technology. In some cases, only a polishing wheel, a handheld polishing jig, and an optical microscope are needed.
Reading out the raw bits is only the first step of the process, as these bits need to be further analyzed and manipulated to properly understand the code. The complexity of reverse engineering will vary depending on the following:
Is the ROM scrambled?
Scrambling is when the data is ‘mixed-up’ at the periphery of the memory block. In this case, it is enough to study the peripheral circuitry to make sense of the data.
Figure 1. Normal (unscrambled) output
Figure 2. Scrambled output
The ordering may also vary byte-to-byte, making reverse engineering more difficult.
Is the ROM encrypted?
Encryption is far more difficult to reverse engineer because the data is routed out of the memory and into the CPU logic, which is usually vast and, on its face, random. The data will be routed to the decryption circuitry, which may only be a few dozen logic cells.
Finding the decryption circuitry in a sea of one hundred thousand logic cells with no direction on where to start is an extremely difficult task. It may be necessary to reverse engineer the entire CPU logic; however, there are isolation techniques like thermal or photon emission that can help identify a specific area of interest on the chip. Using such techniques, the chip is instructed to repeatedly decrypt data while the entire chip is monitored for heat or light emissions, revealing the area of the chip that is performing the decryption. This smaller area of the chip then becomes the focus of reverse engineering.
Is the ROM both scrambled and encrypted?
If the ROM is both scrambled and encrypted, recovering the data will require analysis of the addressing logic and reverse engineering some if not all of the CPU logic. If the raw data is encrypted, the physical bit pattern will look the same, whether it is scrambled or not.
How do you deprocess a chip?
Deprocessing is the physical removal of layers from a finished chip using chemical and mechanical techniques. The process is necessarily destructive and can be used to remove one or more layers, depending on the target.
Consider the following example chip:
Figure 3. Example chip cross-section showing metal layers and transistors
We can see that the chip is constructed of many layers of copper circuitry, all embedded in an insulator (glass-type material). Transistors are literally the building blocks of digital components and are fabricated on the silicon substrate at the bottom of the chip. Therefore, the ROM transistors will be located on the bottom as well. The raw bits we are looking for (the ROM encoding layer) will likely be at the Contact, Metal 1, or Via 1 layer (between Metal 1 and Metal 2), but we won’t know for sure until we start destroying some chips.
If we have the time and sufficient samples, we can start by removing all of the layers from one chip in order to analyze the floorplan. Based on this analysis, we can map out where the memories are located and even identify what types of memories are present, such as Flash, SRAM, DRAM, or ROM. This will help identify the specific area of the chip to focus on when attempting to extract the raw bits. In addition, we could also cross-section a chip at the location of the ROM to help determine which layer contains the bit encoding to guide our work.
If we don’t have the time or the samples, we can just go ahead and carefully deprocess a single chip, and at some point, the ROM bits will appear. But if we deprocess too far, we will go past the bit encoding layer and lose the data.
For our work, we will use the most basic and fastest technique—mechanical polishing. While many argue that mechanical polishing is the most effective method for deprocessing chips, it is also the most skill dependent.
We can polish in several ways (in order of increasing sophistication and cost):
Manual finger polishing: The decapsulated chip is placed on the fingertip and polished on a static plate or piece of glass.
Turntable finger polishing: Similar to manual but uses a rotating platen to expedite the polishing process (and eliminate Repetitive Strain Injury!).
Manual polishing with fixture (jig): Uses a rotating platen in conjunction with a polishing fixture that can be adjusted to compensate for non-planarity.
In this example we used the third approach because a turntable accelerates progress, and a polishing jig offers fine angle control. Additionally, the manual polishing table and jig, as well as the abrasives involved, are relatively low-cost items, keeping the approach within reach of a skilled and motivated hobbyist.
Figure 4. A decapsulated chip mounted to the polishing stub
Figure 5. The stub attached to the polishing jig while being polished
Determining when to stop polishing (end pointing) is difficult; however, when we hit the ROM encoding layer, we should see some kind of pattern under an optical microscope, even at 5x magnification.
The image below was taken at 20x magnification, and we can categorically say that we have reached the right layer.
Figure 6. Corner of ROM exposed at bit encoding layer
The bits appear as white dots from above, because they are bullet-shaped Tungsten interconnects, a little like the contacts shown in the following cross-section images:
Figure 7. ROM cross-section fully processed (left) and deprocessed to the bit encoding layer (right)
Figure 8. Sample area for initial visual inspection
We can see from a very high-level visual inspection that the ROM cannot possibly be encrypted, due to the distribution of ones versus zeroes. If the data was properly encrypted, then the distribution would appear random; however, a visual assessment is sufficient to confirm a lack of entropy without the need to formally calculate[1] it with binwalk[2] or another tool. We can conclude that although the data may be scrambled, it is not encrypted. There is enough evidence to tell us that if we extract the raw bits, we can derive the addressing to then get us back to an understandable binary.
For now, we don’t need to carefully analyze the addressing circuit; all we need is to determine if there is any scrambling in the addressing logic. We can do this visually.
Figure 9. Sample area of decoding/addressing circuit (bottom)
Figure 10. Sample area of decoding/addressing circuit (left)
Figure 11 Sample area of decoding/addressing circuit (between blocks)
When we isolate a small area of the decoding/addressing circuitry at any point (bottom, left, or between the blocks), it is perfectly repeated. This proves that the ROM is not scrambled, and all we need to do is to work out how the bits are read to recreate the full binary. That, and extract the raw bits, of course.
No Scrambling 😊
No Encryption 😊
How do you extract the raw bits?
It is preferable that we automate the extraction process, as the ROM’s capacity is 16 KB (128,000 single bits), which is far too much to extract manually. First, we must determine if our optical images are good enough to reliably extract the raw bits. If not, we may need to use a Scanning Electron Microscope (SEM) to obtain higher resolution, higher contrast images.
Figure 12. Sample area of raw bits imaged optically (top) and by SEM (bottom)
Clearly there is a huge difference in resolution and, more importantly, contrast between the two types of images. It’s obvious that using SEM images would expedite the extraction process, but let’s see if we can use the optical images and do this on a shoestring budget.
First, we need to optimize the optical test image with photo editing software to maximize our chances of success. A good start is always to use the filters in Photoshop such as ‘Noise – Despeckle’ and ‘Noise – Dust and Scratches.’ The final step would be to manipulate the levels to maximize the contrast.
Figure 13. Screenshots showing Adobe Photoshop noise filters being applied
Figure 14. Sample area of raw bits imaged optically and filtered/optimized
Perhaps quite surprisingly, simply by filtering and adjusting the levels of the optical image, we can almost end up with the same result as with the SEM.
Figure 15. Plot of unfiltered optical image
Figure 16. Plot of filtered optical image
From this simple test, we can conclude that any effective tool will be capable of reliably extracting the raw bits from our optical images.
Figure 17. Single block with bit extraction grid overlaid
Figure 18. Zoomed view of bits with extraction grid overlaid
Commercial software is available for semi-automated ROM bit extraction. The software measures the brightness of the area around the line intersections and compares that against a user-defined estimate for both a one and a zero. The software then assigns values to each area in which a bit exists, then exports the values to a text file. Below is the text extracted from this small piece of ROM. This is a fraction of one of 64 sections within the memory array, so some time is required for a full extraction. There is certainly an AI/ML opportunity here to expedite the process.
After repeating the process many times, we have the entire ROM in our hands, and we can move onto the next step: deriving how the bits are addressed. At this point, we will have a usable binary to work with in IDA Pro or Binary Ninja so we can understand the boot process and find some potential areas of weakness we can glitch.
Bits to Binary
As this is a chip with a known vulnerability, it was possible to dump the entire ROM via JTAG. We will use this dump to help us do two things:
Deduce how the ROM is addressed
Compare our physically extracted ROM with the JTAG dump to validate our process
To illustrate the analysis of our physically extracted dump, we will use the higher-resolution SEM images we acquired after the optical images were taken.
Let’s start by looking at the electrical dump of the ROM. The following output is the beginning and end of the ROM .bin, with the end looking very much like a checksum. We know this is commonly used by this manufacturer, so after many zero bytes, there are two bytes of data at the very end of the file.
Figure 19. Hex dump output of the start (top) and end (bottom) of the ROM .bin
Figure 20. Bottom section of ROM SEM stitch with checksum bits annotated
Figure 21. Close-up showing that the three bits are not in the same row. One on the first row, then two on the second row (the red line is perfectly parallel)
From the fact that we have the two-byte checksum (0105) in hex, and that the corresponding raw bits (0000 0001 0000 0101) are not in a linear pattern, then we must assume that there is some flipping/mirroring happening on the bit addressing. The fact that the bits are split over two rows also gives us a clue.
Now our checksum is beginning to make sense. With a checksum of 0105 (0000 0001 0000 0101), there must only be one way to read it. Essentially, we are looking for how the three ones are addressed.
First, we can see that the three bits are all on the same bit column, so we can ignore the rest. It makes things easier to visualize by annotating all of the bit columns, then highlighting the only column (column 0) we care about in yellow. The values are now much easier to read by eye, and we can see the direction in which they are read by the memory array.
Figure 22. Right side of checksum area annotated with columns, binary values, and hex
Figure 23. Entire width of checksum area annotated with columns, binary values, and hex
We now see that 0105, albeit not in a logical order for a human. There is one question mark remaining: Do we assume that we read the left side in reverse first (01) followed by the second (05)? There we have a simple 50% chance of being correct, and to find out, we can apply that to the more densely populated areas of ROM.
Figure 24. Opposite end of ROM annotated with read order, binary values, and corresponding hex
The portion of ROM above shows the hex value along with the raw binary for the two-word width of the ROM array. The colored arrows illustrate the direction in which the bits are read from the .bin and how they are read from the raw bit image. The following is a closer view of one byte, where blue bits are logical ones and yellows are logical zeros:
the end of the ROM, annotated with read order and binary values
Finally, a binary!!!
The following image contains some dumped bytes from the target. This can be later be opened in the reversing tool of our choice, and after some preparation work, we can begin reverse engineering and identifying the potential weaknesses. In this case, as some readers might know, the target sample has a known vulnerability that can be exploited via fault injection. This vulnerability can allow an attacker with physical access to the device to retrieve the entire contents, even if the chip has been locked down.
Figure 26. Some bytes dumped from the target chip
Figure 27. Part of the boot process where CRP values are read and are controlling access to the debugging interfaces
Overall Conclusions
While a chip with a known vulnerability was used in this case study for comparative purposes, the same techniques can be applied to a chip without this vulnerability
The electrical version of the ROM dump matched 100% with the physically extracted version
Physical ROM bit extraction is skill-dependent, but can be carried out using a relatively basic toolset such as:
Basic polishing turntable
Handheld polishing jig
Diamond abrasives
Optical microscope
ROM binary extraction is dependent on:
Existence of encryption
Complexity of scrambling
Patience!
ROM binary analysis and isolation of glitching/fault injection points is possible
Electrical and electromagnetic fault injection techniques are skill- and chip-dependent; however, the bar of entry is relatively low (hundreds to thousands of dollars)
In this post, we continue our deep dive comparison of the security processors used on a consumer product and an unlicensed clone. Our focus here will be identifying and characterizing memory arrays.
Given a suitably deprocessed sample, memories can often be recognized as such under low magnification because of their smooth, regular appearance with distinct row/address decode logic on the perimeter, as compared to analog circuitry (which contains many large elements, such as capacitors and inductors) or autorouted digital logic (fine-grained, irregular structure).
Identifying memories and classifying them as to type, allows the analyst to determine which ones may contain data relevant to system security and assess the difficulty and complexity of extracting their content.
OEM Component
Initial low-magnification imaging of the OEM secure element identified 13 structures with a uniform, regular appearance consistent with memory.
Higher magnification imaging resulted in three of these structures being reclassified as non-memory (two as logic and one as analog), leaving 10 actual memories.
Figure 1. Logic circuitry initially labeled as memory due to its regular structure
Figure 2. Large capacitor in analog block
Of the remaining 10 memories, five distinct bit cell structures were identified:
Single-port (6T) SRAM
Dual-port (8T) SRAM
Mask ROM
3T antifuse
Floating gate NOR flash
Single-port SRAM
13 instances of this IP were found in various sized arrays, with capacities ranging from 20 bits x 8 rows to 130 bits x 128 rows.
Some of these memories include extra columns, which appear to be intended as spares for remapping bad columns. This is a common practice in the semiconductor industry to improve yield: memories typically cover a significant fraction of the die surface and thus are responsible for a large fraction of manufacturing defects. If the device can remain operable despite a defect in a memory array, the overall yield of usable chips will be higher.
Figure 3. Substrate overview of a single-port SRAM array
Figure 4. Substrate closeup view of single-port SRAM bit cells
Dual-port SRAM
Six instances of this IP were found, each containing 320 bit cells (40 bytes).
Two instances of this IP were found, with capacities of 256 Kbits and 320 Kbits respectively. No data was visible in a substrate view of the array.
Figure 6. Substrate view of mask ROM showing no data visible
A cross section (Figure 7) showed irregular metal 1 patterns as well as contacts that did not go to any wires on metal 1, strongly suggesting this was a metal 1 programmed ROM. A plan view of metal 1 (Figure 8) confirms this. The metal 1 pattern also shows that the transistors are connected in series strings of 8 bits (with each transistor in the string either shorted by metal or not, in order to encode a logic 0 or 1 value), completing the classification of this memory as a metal 1 programmed NAND ROM.
Figure 7. Cross section of metal 1 programmed NAND ROM showing irregular metal patterns and via with unconnected top
Figure 8. Top-right corner of one ROM showing data bits and partial address decode logic
IOActive successfully extracted the contents of both ROMs and determined that they were encrypted. Further reverse engineering would be necessary to locate the decryption circuitry in order to make use of the dumps.
Antifuse
Five instances of this IP were found, four with a capacity of 4 rows x 32 bits (128 bits) and one with a capacity of 32 rows x 64 bits (2048 bits).
The bit cells consist of three transistors (two in series and one separate) and likely function by gate dielectric breakdown: during programming, high voltage applied between a MOSFET gate and the channel causes the dielectric to rupture, creating a short circuit between the drain and gate terminals.
Antifuse memory is one-time programmable and is expensive due to the very low density (significantly larger bit cell compared to flash or ROM); however, it offers some additional security because the ruptured dielectric is too thin to see in a top-down view of the array, rendering it difficult to extract the contents of the bit cells. It is also commonly used for small memories when the complexity and re-programmability of flash memory is unnecessary, such as for storing trim values for analog blocks or remapping data for repairing manufacturing defects in SRAM arrays.
Figure 9. Antifuse array
Figure 10. Cross section of antifuse bit cells
Flash
A single instance of this IP was found, with a capacity of 1520 Kbits.
This memory uses floating-gate bit cells connected in a NOR topology, as is common for embedded flash memories on microcontrollers.
Figure 11. Substrate plan view of bit cells
Figure 12. Cross section of NOR Flash memory
Clone Component
Floorplan Overview
Figure 13. Substrate view of clone secure element after removal of metal and polysilicon
The secure element from the clone device contains three obvious memories, located at the top right, bottom left, and bottom right corners.
Lower-left Memory
The lower-left memory consists of a bit cell array with addressing logic at the top, left, and right sides. Looking closely, it appears to be part of a larger rectangular block that contains a large region of analog circuitry above the memory, as well as a small amount of digital logic.
This is consistent with the memory being some sort of flash (likely the primary code and data storage for the processor). The large analog block is probably the high voltage generation for the program/erase circuitry, while the small digital block likely controls timing of program/erase operations.
The array appears to be structured as 32 bits (plus 2 dummy or ECC columns) x 64 blocks wide, by 2 bits * 202 rows (likely 192 + 2 dummy features + 8 spare). This gives an estimated usable array capacity of 786432 bits (98304 bytes, 96kB).
Figure 14. Overview of bottom left (flash) memory
Figure 15. SEM substrate image of flash memory
A cross section was taken, which did not show floating gates (as compared to the OEM component). This suggests that this component is likely using a SONOS bit cell or similar charge-trapping technology.
Lower-right Memory
The lower-right memory consists of two identical blocks side-by-side, mirrored left-to-right. Each block consists of 128 columns x 64 cells x 3 blocks high, for a total capacity of 49152 bits (6144 bits, 6 kB).
Figure 16. Lower-right memory
At higher magnification, we can see that the individual bit cells consist of eight transistors, indicative of dual-port SRAM—perhaps some sort of cache or register file.
Figure 17. Dual-port SRAM on clone secure element (substrate)
Figure 18. Dual-port SRAM on clone secure element (metal 1)
Upper-right Memory
The upper – right memory consists of a 2 x 2 grid of identical tiles, each 128 columns x 160 rows (total capacity 81920 bits/10240 bytes/10 kB).
Figure 19. Upper-right SRAM array
Upon closer inspection, the bit cell consists of six transistors arranged in a classic single-port SRAM structure.
Figure 20. SEM substrate image of 6T SRAM cells
Figure 21. SEM metal 1 image of 6T SRAM cells
Concluding Remarks
The OEM component contains two more memory types (mask ROM and antifuse) than the clone component. It has double the flash memory and nearly triple the persistent storage (combined mask ROM and flash) capacity of the clone, but slightly less SRAM.
Overall, the memory technology of the clone component is significantly simpler and lower cost.
Overall Conclusions
OEMs secure their accessory markets for the following reasons:
To ensure an optimal user experience for their customers
To maintain the integrity of their platform
To secure their customers’ personal data
To secure revenue from accessory sales
OEMs routinely use security chips to protect their platforms and accessories; cost is an issue for OEMs when securing their platforms, which potentially can lead to their security being compromised.
Third-party solution providers, on the other hand:
Invest in their own labs and expertise to extract the IP necessary to make compatible solutions
Employ varied attack vectors with barriers of entry ranging from non-invasive toolsets at a cost of $1,000 up, to an invasive, transistor-level Silicon Lab at a cost of several million dollars
Often also incorporate a security chip to secure their own solutions, and to in turn lock out their competitors
Aim to hack the platform and have the third-party accessory market to themselves for as long as possible