Countless movies feature hackers remotely turning off security systems in order to infiltrate buildings without being noticed. But how realistic are these depictions? Time to find out.
Today we’re releasing information on a critical security vulnerability in a wireless home security system from SimpliSafe. This system consists of two core components, a keypad and a base station. These may be combined with a wide array of sensors ranging from smoke detectors to magnet switches to motion detectors to create a complete home security system. The system is marketed as a cost-effective and DIY-friendly alternative to wired systems that require expensive professional installation and long term monitoring service contracts.


Looking at the FCC documentation for the system provides a few hints. It appears the keypad and sensors transmit data to the base station using on-off keying in the 433 MHz ISM band. The base station replies using the same modulation at 315 MHz.
After dismantling a few devices and looking at which radio(s) were installed on the boards, I confirmed the system is built around a star topology: sensors report to the base station, which maintains all system state data. The keypad receives notifications of events from the base station and drives the LCD and buzzer as needed; it then sends commands back to the base station. Sensors only have transmitters and therefore cannot receive messages.
Rather than waste time setting up an SDR or building custom hardware to mess with the radio protocol, I decided to “cheat” and use the conveniently placed test points found on all of the boards. Among other things, the test points provided easy access to the raw baseband data between the MCU and RF upconverter circuit.
I then worked to reverse engineer the protocol using a logic analyzer. Although I still haven’t figured out a few bits at the application layer, the link-layer framing was pretty straightforward. This revealed something very interesting: when messages were sent multiple times, the contents (except for a few bits that seem to be some kind of sequence number) were the same! This means the messages are either sent in cleartext or using some sort of cipher without nonces or salts.
After a bit more reversing, I was able to find a few bits that reliably distinguished a “PIN entered” packet from any other kind of packet.
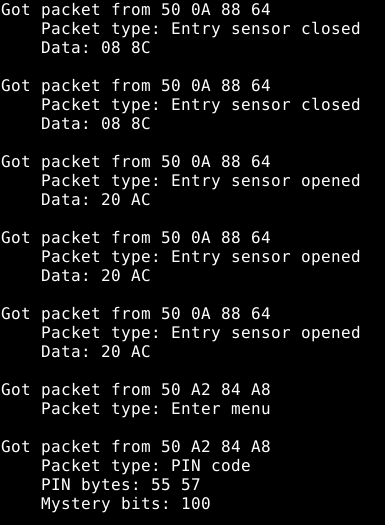
I spent quite a while trying to figure out how to convert the captured data bytes back to the actual PIN (in this case 0x55 0x57 -> 2-2-2-2) but was not successful. Luckily for me, I didn’t need that for a replay attack.
To implement the actual attack I simply disconnected the MCUs from the base station and keypad, and soldered wires from the TX and RX basebands to a random microcontroller board I had sitting around the lab. A few hundred lines of C later, I had a device that would passively listen to incoming 433 MHz radio traffic until it saw a SimpliSafe “PIN entered” packet, which it recorded in RAM. It then lit up an LED to indicate that a PIN had been recorded and was ready to play back. I could then press a button at any point and play back the same packet to disarm the targeted alarm system.

This attack is very inexpensive to implement – it requires a one-time investment of about $250 for a commodity microcontroller board, SimpliSafe keypad, and SimpliSafe base station to build the attack device. The attacker can hide the device anywhere within about a hundred feet of the target’s keypad until the alarm is disarmed once and the code recorded. Then the attacker retrieves the device. The code can then be played back at any time to disable the alarm and enable an undetected burglary, or worse.
While I have not tested this, I expect that other SimpliSafe sensors (such as entry sensors) can be spoofed in the same fashion. This could allow an attacker to trigger false/nuisance alarms on demand.
Unfortunately, there is no easy workaround for the issue since the keypad happily sends unencrypted PINs out to anyone listening. Normally, the vendor would fix the vulnerability in a new firmware version by adding cryptography to the protocol. However, this is not an option for the affected SimpliSafe products because the microcontrollers in currently shipped hardware are one-time programmable. This means that field upgrades of existing systems are not possible; all existing keypads and base stations will need to be replaced.
IOActive made attempts through multiple channels to contact SimpliSafe upon finding this critical vulnerability, but received no response from the vendor. IOActive also notified CERT of the vulnerability in the normal course of responsible disclosure. The timeline can be found here within the release advisory.
SimpliSafe claims to have its units installed in over 300,000 homes in North America. Consumers of this product need to know the product is inherently insecure and vulnerable to even a low-level attacker. This simple vulnerability is particularly alarming because; 1) it exists within a “security product” that is trusted to secure over a million homes; 2) it enables an attacker to completely own the system (i.e., disable it, change PIN codes, etc.), and; 3) many unsuspecting consumers prominently display window and yards signs promoting their use of this system…essentially self-identifying their home as a viable target for an attacker.