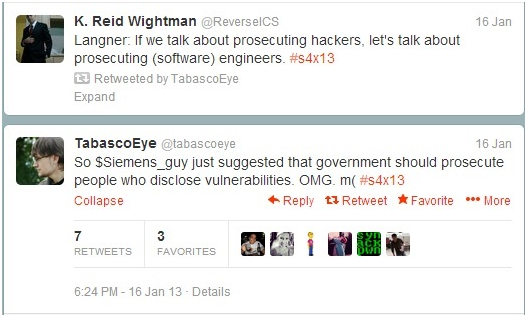
This story begins with a few merry and good hearted tweets from S4x13. These tweets in fact:
Notice the shared conviviality, and the jolly manner in which this discussion of vulnerabilities occurs.
It is with this same lightness in my heart that I thought I would explore the mysterious world of the.
So I waxed my moustache, rolled up my sleeves, and began to use the arcane powers of Quality Assurance.
Ok, how would an attacker who doesn’t have default credentials or a device to test on go about investigating one of these remotely? Why, find one on Shodan of course!
Personally, I buy mine second hand from eBay with the fortune I inherited from my grandfather’s moustache wax empire.
The first thing an attacker would normally do is scan the device to get familiar with the ports and services. A quick nmap looks like this:
Nmap scan report for Unknown (192.168.0.5)
Host is up (0.0043s latency).
Not shown: 994 closed ports
PORT STATE SERVICE VERSION
22/tcp open ssh OpenSSH 4.2 (protocol 2.0)
|_ssh-hostkey: 1024 cd:b4:33:49:62:3b:58:1a:67:5a:a3:f0:50:00:71:86 (RSA)
23/tcp open telnet?
80/tcp open http WindWeb 4.00
|_http-methods: No Allow or Public header in OPTIONS response (status
code 501)
|_http-title: Logon to SCALANCE X Management (192.168.0.5)
84/tcp open ctf?
111/tcp open rpcbind 2 (RPC #100000)
| rpcinfo:
| program version port/proto service
| 100000 2 111/tcp rpcbind
|_ 100000 2 111/udp rpcbind
443/tcp open ssl/http WindWeb 4.00
|_http-methods: No Allow or Public header in OPTIONS response (status
code 501)
|_http-title: Logon to SCALANCE X Management (192.168.0.5)
| ssl-cert: Subject: organizationName=Siemens
AG/stateOrProvinceName=BW/countryName=DE
| Not valid before: 2008-02-04T14:05:57+00:00
|_Not valid after: 2038-01-18T14:05:57+00:00
|_ssl-date: 1970-01-01T00:14:20+00:00; -43y254d14h08m05s from local time.
| sslv2:
| SSLv2 supported
| ciphers:
| SSL2_DES_192_EDE3_CBC_WITH_MD5
| SSL2_RC2_CBC_128_CBC_WITH_MD5
| SSL2_RC4_128_WITH_MD5
| SSL2_RC4_64_WITH_MD5
| SSL2_DES_64_CBC_WITH_MD5
| SSL2_RC2_CBC_128_CBC_WITH_MD5
|_ SSL2_RC4_128_EXPORT40_WITH_MD5
MAC Address: 00:0E:8C:A3:4E:CF (Siemens AG A&D ET)
Device type: general purpose
Running: Wind River VxWorks
OS CPE: cpe:/o:windriver:vxworks
OS details: VxWorks
Network Distance: 1 hop
So we have a variety of management interfaces to choose from: Telnet (really in 2014?!?), SSH, HTTP, and HTTPS. All of these interfaces share the same users and default passwords you would expect, but we are looking for something more meaningful.
Now that we’ve found them on Shodan (wait, they’re all air-gapped, right?), we quickly learn from the web interface that there are only two users: admin and user. Next we view the web page source and search for “password” which gives us this lovely snippet:
document.submitForm.encoded.value = document.logonForm.username.value + “:” + md5(document.logonForm.username.value + “:” + document.logonForm.password.value + “:” + document.submitForm.nonceA.value)
This is equivalent to the following command on Linux:
echo -n “admin:admin:C0A8006500005F31” | md5sum
Which is then posted to the device in a form such as this (although this one has a different password*):
encoded=admin%3Aafc0dc177659c8e9d72dec8a3c68650e&nonceA=C0A800610000CE29
Setting aside just how weak the use of MD5 is (and in fact I have written a script to brute-force credentials snatched off the wire), that nonceA value is very important. A nonce is a ‘number used once’, which is typically used to prevent cryptographic replay attacks. In other words, this random challenge value is provided by the server, to keep an attacker from simply capturing the hash on the wire and replaying it to the server later when they want to login. This nonce then, deserves our attention.
It appears that this is an ID field in the cookie, and that it is also the session ID. If I can predict session Ids, I can perform session hijacking while someone is managing the switch. So we set about estimating the entropy of this session ID, which initially appears to be 16 hex values. However, we won’t even need to create an equation since it turns out to be COMPLETELY predictable, as you will soon see.
We can use WGET to fetch the page a few times and get a small sample of these nonceA values. This is what we see:
C0A8006500005F31,C0A8006500001A21,C0A8006500000960,C0A80065000049A6
This seems distinctly non-random. In fact, when I measured it more precisely, it became clear that it was sequential! A little further investigation revealed that SNMP is sometimes available to us. So we use snmpwalk on one of the devices I have at home:
snmpwalk -Os -c public -v 1 192.168.0.5
iso.3.6.1.2.1.1.1.0 = STRING: “Siemens, SIMATIC NET, SCALANCE X204-2,
6GK5 204-2BB10-2AA3, HW: 4, FW: V4.03″
iso.3.6.1.2.1.1.2.0 = OID: iso.3.6.1.4.1.4196.1.1.5.2.22
iso.3.6.1.2.1.1.3.0 = Timeticks: (471614) 1:18:36.14
Well look at that!
47164 in base 10 = 7323E in hex! I wonder if the session ID is simply uptime in hex?
We do a WGET at approximately the same time and get this as a session ID:
C0A800610007323F
So if we assume the last 8 hex chars are uptime in hex (or at least close enough for us to brute-force the few values around it), then where do the first 8 hex come from?
I initially imagined they were unique for each device and set out to test that theory by getting a session ID from another device found on Shodan. Keep in mind I did not attempt a login, I just fetched the page to see what the session ID was. Sure enough it was different, but the one from the switch I have wasn’t the MAC address or any other unique identifier on the switch. I spent a week missing the point here, but luckily I have excellent company at IOActive Labs.
It was during discussions with my esteemed colleague Reid Wightman, he suggested it was an IP address. He pointed out the C0 and A8 are 192 168 in decimal. So I went and checked the IP address of the switch I have, and it was not 192.168.0.97. So again I was stumped until I realized it was the IP address of my own client machine!
In other words, the nonceA was simply the address of the web client (converted to hex) connecting to the switch, concatenated to the uptime of the switch (in hex). I can practically see the developer who thought this would be a good idea. I can hear them thinking that each session is clearly distinguished by the address it is connecting from, and made impossible to brute-force with time. Time+Space, that’s too large to brute-force or estimate right? You must admit, it has a kind of perverse logic to it. Unfortunately, it is highly predictable and insecure.
Go home Scalance X200 family session IDs, you’re drunk. Aside from being completely predictable, they are too small. 32 hex is a far cry from using the 128 bits recommended by OWASP.
I guess that’s what they refer to in this announcement with the phrases “A potential vulnerability” and “that might allow attackers to hijack web sessions over the network without authentication”.
There are a few more vulnerabilities to discuss about this switch, but to learn about those, you’ll have to see me at S4x14, or wait for the next blog post where I release a more reliable POC.
Siemens product CERT should be commended for being polite and helpful, and relatively quick with this fix. They acknowledged my work, and communicated clear timelines of when to expect a fix. This is precisely how they should go about communicating with us in the research community. It was at this point that I informed the good folks over at Siemens that I would verify the patch on Sep 12th. On the morning of the 12th, I tried to login to verify they patch they had provided, and found myself blocked from doing so.
Should a firmware release with security implications only be downloadable in a forum that requires vetting and manual processing? Is it acceptable to end users that security patches are under export restriction?
Luckily these bans were lifted later that day and I was able to confirm the fixes. I would like to commend Siemens Product CERT the team for fixing these issues rapidly and with great professionalism. They communicated with me securely using GPG encrypted emails, set realistic timelines, and gave me feedback when those timelines didn’t work out. This leads me to a formal challenge based on their performance.
I challenge any other ICS vendors to match Siemens laudable response times and produce patches within 3 months for any externally submitted security vulnerabilities.
Stay tuned for part 2 where we release the simple Python script for authentication bypass which allows firmware and configuration upload and download.
*If you can crack this, and are interested in a job, please send IOActive your CV and the cleartext password used to create that credential. It is not hard, but it might take you a while….