
This year I gave a series of presentations on “The Future of Automated Malware Generation”. This past week the presentation finished its final debut in Tokyo on the 10th anniversary of PacSec.
Hopefully you were able to attend one of the following conferences where it was presented:
- IOAsis (Las Vegas, USA)
- SOURCE (Seattle, USA)
- EkoParty (Buenos Aires, Argentina)
- PacSec (Tokyo, Japan)

Motivation / Intro
- Greg Hoglund’s talk at Blackhat 2010 on malware attribution and fingerprinting
- The undeniable steady year by year increase in malware, exploits and exploit kits
- My unfinished attempt in adding automatic classification to the cuckoo sandbox
- An attempt to clear up the perception by many consumers and corporations that many security products are resistant to simple evasion techniques and contain some “secret sauce” that sets them apart from their competition
- The desire to educate consumers and corporations on past, present and future defense and offense techniques
- Lastly to help reemphasize the philosophy that when building or deploying defensive technology it’s wise to think offensively…and basically try to break what you build
Current State of Automated Malware Generation
Automated Malware Generation centers on Malware Distribution Networks (MDNs).
MDNs are organized, distributed networks that are responsible for the entire exploit and infection vector.
There are several players involved:
- Pay-per-install client – organizations that write malware and gain a profit from having it installed on as many machines as possible
- Pay-per-install services – organizations that get paid to exploit and infect user machines and in many cases use pay-per-install affiliates to accomplish this
- Pay-per-install affiliates – organizations that own a lot of infrastructure and processes necessary to compromise web legitimate pages, redirect users through traffic direction services (TDSs), infect users with exploits (in some cases exploit kits) and finally, if successful, download malware from a malware repository.
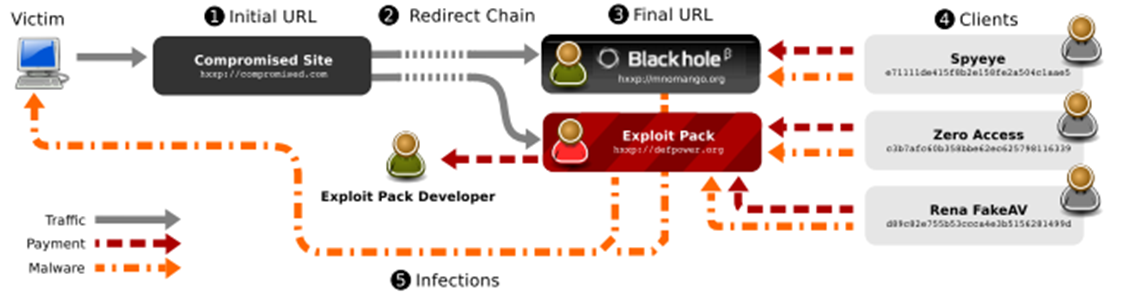
Source: Manufacturing Compromise: The Emergence of Exploit-as-a-Service

Figure: Basic Break-down of Malware Repository Types
Current State of Malware Defense
- hashes – cryptographic checksums of either the entire malware file or sections of the file, in some cases these could include black-listing and white-listing
- signatures – syntactical pattern matching using conditional expressions (in some cases format-aware/contextual)
- heuristics – An expression of characteristics and actions using emulation, API hooking, sand-boxing, file anomalies and/or other analysis techniques
- semantics – transformation of specific syntax into a single abstract / intermediate representation to match from using more abstract signatures and heuristics
EVERY defense technique can be broken – with enough time, skill and resources.
In the above defensive techniques:
- hash-based detection can be broken by changing the binary by a single byte
- signature-based detection be broken using syntax mutation
e.g.- Garbage Code Insertion e.g. NOP, “MOV ax, ax”, “SUB ax 0”
- Register Renaming e.g. using EAX instead of EBX (as long as EBX isn’t already being used)
- Subroutine Permutation – e.g. changing the order in which subroutines or functions are called as long as this doesn’t effect the overall behavior
- Code Reordering through Jumps e.g. inserting test instructions and conditional and unconditional branching instructions in order to change the control flow
- Equivalent instruction substitution e.g. MOV EAX, EBX <-> PUSH EBX, POP EAX
- heuristics-based detection can be broken by avoiding the characteristics the heuristics engine is using or using uncommon instructions that the heuristics engine might be unable to understand in it’s emulator (if an emulator is being used)
- semantics-based detection can be broken by using techniques such as time-lock puzzle (semantics-based detection are unlikely to be used at a higher level such as network defenses due to performance issues) also because implementation requires extensive scope there is a high likelihood that not all cases have been covered. Semantic-based detection is extremely difficult to get right given the performance requirements of a security product.
There are a number of other examples where defense techniques were easily defeated by proper targeted research (generally speaking). Here is a recent post by Trail of Bits only a few weeks ago [Trail of Bits Blog] in their analysis of ExploitSheild’s exploitation prevention technology. In my opinion the response from Zero Vulnerability Labs was appropriate (no longer available), but it does show that a defense technique can be broken by an attacker if that technology is studied and understood (which isn’t that complicated to figure out).
Malware Trends
Check any number of reports and you can see the rise in malware is going up (keep in mind these are vendor reports and have a stake in the results, but being that there really is no other source for the information we’ll use them as the accepted experts on the subject) [Symantec] [Trend] McAfee [IBM X-Force] [Microsoft] [RSA]
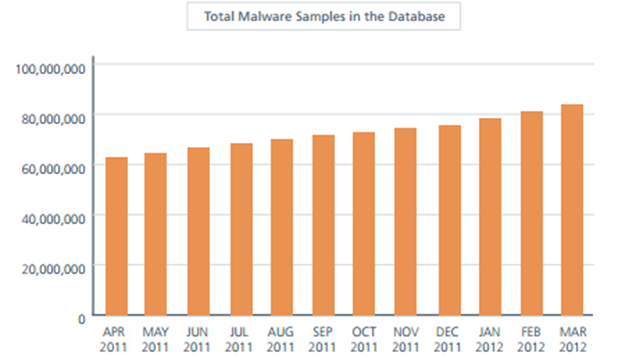

So how can the security industry use automatic classification? Well, in the last few years a data-driven approach has been the obvious step in the process.
The Future of Malware Defense
With the increase in more malware, exploits, exploit kits, campaign-based attacks, targeted attacks, the reliance on automation will heave to be the future. The overall goal of malware defense has been to a larger degree classification and to a smaller degree clustering and attribution.
Thus statistics and data-driven decisions have been an obvious direction that many of the security companies have started to introduce, either by heavily relying on this process or as a supplemental layer to existing defensive technologies to help in predictive pattern-based analysis and classification.
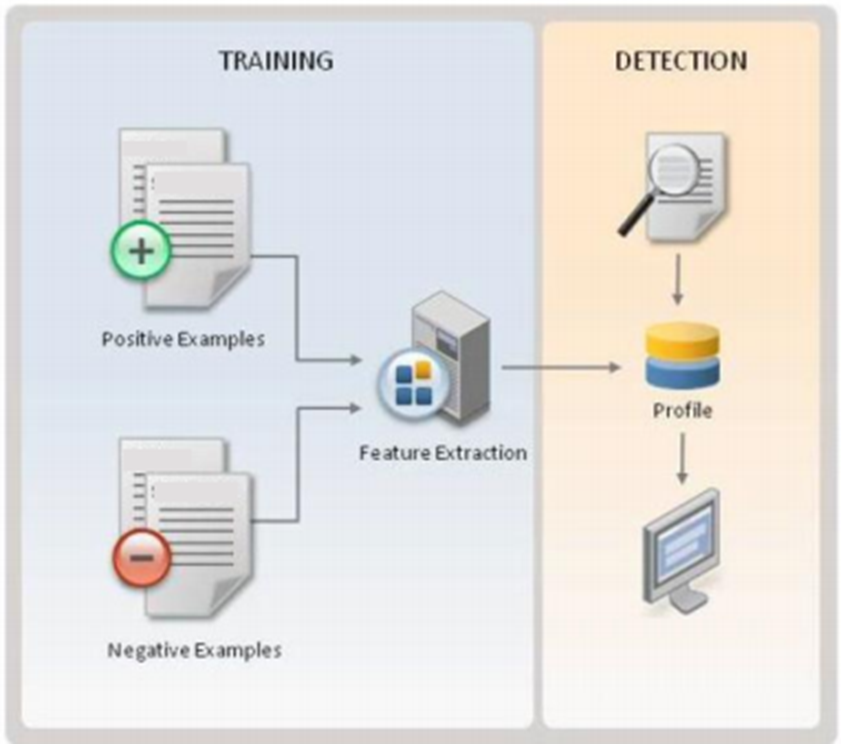
Training machine learning classifiers involves breaking down whatever content you want to analyze e.g. a network stream or an executable file into “features” (basically characteristics).
For example historically certain malware has:
- No icon
- No description or company in resource section
- Is packed
- Lives in windows directory or user profile
Each of the above qualities/characteristics can be considered “features”. Once the defensive technology creates a list of features, it then builds a parser capable of breaking down the content to find those features. e.g. if the content is a PE WIN32 executable, a PE parser will be necessary. The features would include anything you can think of that is characteristic of a PE file.
The process then involves training a classifier on a positive (malicious) and negative (benign) sample set. Once the classifier is trained it can be used to determine if a future unknown sample is benign or malicious and classify it accordingly.
- Compressed JavaScript
- PDF header location e.g %PDF – within first 1024 bytes
- Does it contain an embedded file (e.g. flash, sound file)
- Signed by a trusted certificate
- Encoded/Encrypted Streams e.g. FlatDecode is used quite a lot in malicious PDFs
- Names hex escaped
- Bogus xref table
There are two open-source projects that I want to mention using machine learning to determine if a file is malicious:
PDF-XRay from Brandon Dixon:

Adobe Open Source Malware Classification Tool by Karthik Raman/Adobe
Shifting away from analysis of files, we can also attempt to classify shellcode on the wire from normal traffic. Using marchov chains which is a discipline of Artificial Intelligence, but in the realm of natural language processing, we can determine and analyze a network stream of instructions to see if the sequence of instructions are likely to be exploit code.

The Future of Automated Malware Generation
In many cases the path of attack and defense techniques follows the same story of cat and mouse. Just like Tom and Jerry, the chase continues forever, in the context of security, new technology is introduced, new attacks then emerge and in response new countermeasures are brought in to the detection of those attacks…an attacker’s game can come to an end IF they makes a mistake, but whereas cyber-criminal organizations can claim a binary 0 or 1 success or failure, defense can never really claim a victory over all it’s attackers. It’s a “game” that must always continue.

That being said you’ll hear more and more products and security technologies talk about machine learning like it’s this unbeatable new move in the game….granted you’ll hear it mostly from savvy marketing, product managers or sales folks. In reality it’s another useful layer to slow down an attacker trying to get to their end goal, but it’s by no means invincible.
Use of machine learning can be taken circumvented by an attacker in several possible ways:
- Likelihood of false positives / false negatives due to weak training corpus
- Circumvention of classification features
- Inability to parse/extract features from content
- Ability to poison training corpus
Conclusion
In reality, we haven’t yet seen malware that contains anti machine learning classification or anti-clustering techniques. What we have seen is more extensive use of on-the-fly symmetric-key encryption where the key isn’t hard-coded in the binary itself, but uses something unique about the target machine that is being infected. Take Zeus for example that makes use of downloading an encrypted binary once the machine has been infected where the key is unique to that machine, or Gauss who had a DLL that was encrypted with a key only found on the targeted user’s machine.
What this accomplishes is that the binary can only work the intended target machine, it’s possible that an emulator would break, but certainly sending it off to home-base or the cloud for behavioral and static analysis will fail, because it simply won’t be able to be decrypted and run.
Most defensive techniques if studied, targeted and analyzed can be evaded — all it takes is time, skill and resources. Using Machine learning to detect malicious executables, exploits and/or network traffic are no exception. At the end of the day it’s important that you at least understand that your defenses are penetrable, but that a smart layered defense is key, where every layer forces the attackers to take their time, forces them to learn new skills and slowly gives away their resources, position and possibly intent — hopefully giving you enough time to be notified of the attack and cease it before ex-filtration of data occurs. What a smart layered defense looks like is different for each network depending on where your assets are and how your network is set up, so there is no way for me to share a one-size fits all diagram, I’ll leave that to you to think about.
Useful Links:
Coursera – Machine Learning Course
CalTech – Machine Learning Course
MLPY (https://mlpy.fbk.eu/)
PyML (http://pyml.sourceforge.net/)
Milk (http://pypi.python.org/pypi/milk/)
Shogun (http://raetschlab.org/suppl/shogun) Code is in C++ but it has a python wrapper.
MDP (http://mdp-toolkit.sourceforge.net) Python library for data mining
PyBrain (http://pybrain.org/)
Orange (http://www.ailab.si/orange/) Statistical computing and data mining
PYMVPA (http://www.pymvpa.org/)
scikit-learn (http://scikit-learn.org): Numpy / Scipy / Cython implementations for major algorithms + efficient C/C++ wrappers
Monte (http://montepython.sourceforge.net) a software for gradient-based learning in Python
Rpy2 (http://rpy.sourceforge.net/): Python wrapper for R

About Stephan
Stephan Chenette has been involved in computer security professionally since the mid-90s, working on vulnerability research, reverse engineering, and development of next-generation defense and attack techniques. As a researcher he has published papers, security advisories, and tools. His past work includes the script fragmentation exploit delivery attack and work on the open source web security tool Fireshark.
Stephan is currently the Director of Security Research and Development at IOActive, Inc.
Twitter: @StephanChenette