
I was auditing an Android smartphone, and all installed applications were in scope. My preferred approach, when time permits, is to manually inspect as much code as I can. This is how I found a subtle vulnerability that allowed me to interact with a content provider that was supposed to be protected in recent versions of Android: the user’s personal dictionary, which stores the spelling for non-standard words that the user wants to keep.
While in theory access to the user’s personal dictionary should be only granted to privileged accounts, authorized Input Method Editors (IMEs), and spell checkers, there was a way to bypass some of these restrictions, allowing a malicious application to update, delete, or even retrieve all the dictionary’s contents without requiring any permission or user interaction.
This moderate-risk vulnerability, classified as elevation of privilege and fixed on June 2018, affects the following versions of Android: 6.0, 6.0.1, 7.0, 7.1.1, 7.1.2, 8.0, and 8.1.
User’s Personal Dictionary
Android provides a custom dictionary that can be customized manually or automatically, learning from the user’s typing. This dictionary can be usually accessed from “Settings → Language & keyboard → Personal dictionary” (sometimes under “Advanced” or slightly different options). It may contain sensitive information, such as names, addresses, phone numbers, emails, passwords, commercial brands, unusual words (may include illnesses, medicines, technical jargon, etc.), or even credit card numbers.
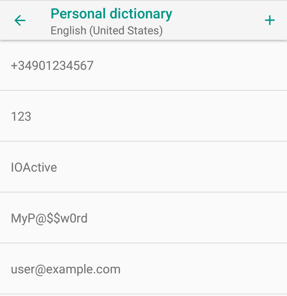
A user can also define a shortcut for each word or sentence, so instead of typing your full home address, you can add an entry and simply write the associated shortcut (e.g. “myhome”) for its autocompletion.
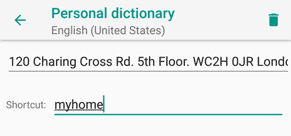
Internally, the words are stored in a SQLite database which simply contains a table named “words” (apart from the “android_metadata”). This table’s structure has six columns:
_id (INTEGER, PRIMARY KEY)word (TEXT)frequency (INTEGER)locale (TEXT)appid (INTEGER)shortcut (TEXT)
Our main interest will be focused on the “word” column, as it contains the custom words, as its name suggests; however, all remaining columns and tables in the same database would be accessible as well.
Technical Details of the Vulnerability
In older versions of Android, read and write access to the personal dictionary was protected by the following permissions, respectively:
android.permission.READ_USER_DICTIONARYandroid.permission.WRITE_USER_DICTIONARY
This is no longer true for newer versions. According to the official documentation1: “Starting on API 23, the user dictionary is only accessible through IME and spellchecker”. The previous permissions were replaced by internal checks so, theoretically, only privileged accounts (such as root and system), the enabled IMEs, and spell checkers could access the personal dictionary content provider (content://user_dictionary/words).
We can check the AOSP code repository and see how in one the changes2, a new private function named canCallerAccessUserDictionary was introduced and was invoked from all the standard query, insert, update, and delete functions in the UserDictionary content provider to prevent unauthorized calls to these functions.
While the change seems to be effective for both query and insert functions, the authorization check happens too late in update and delete, introducing a security vulnerability that allows any application to successfully invoke the affected functions via the exposed content provider, therefore bypassing the misplaced authorization check.
In the following code for the UserDictionaryProvider class3, pay attention to the highlighted fragments and see how the authorization checks are performed after the database would be already altered:
@Override
public int delete(Uri uri, String where, String[] whereArgs) {
SQLiteDatabase db = mOpenHelper.getWritableDatabase();
int count;
switch (sUriMatcher.match(uri)) {
case WORDS:
count = db.delete(USERDICT_TABLE_NAME, where, whereArgs);
break;
case WORD_ID:
String wordId = uri.getPathSegments().get(1);
count = db.delete(USERDICT_TABLE_NAME, Words._ID + "=" + wordId
+ (!TextUtils.isEmpty(where) ? " AND (" + where + ')' : ""), whereArgs);
break;
default:
throw new IllegalArgumentException("Unknown URI " + uri);
}
// Only the enabled IMEs and spell checkers can access this provider.
if (!canCallerAccessUserDictionary()) {
return 0;
}
getContext().getContentResolver().notifyChange(uri, null);
mBackupManager.dataChanged();
return count;
}
@Override
public int update(Uri uri, ContentValues values, String where, String[] whereArgs) {
SQLiteDatabase db = mOpenHelper.getWritableDatabase();
int count;
switch (sUriMatcher.match(uri)) {
case WORDS:
count = db.update(USERDICT_TABLE_NAME, values, where, whereArgs);
break;
case WORD_ID:
String wordId = uri.getPathSegments().get(1);
count = db.update(USERDICT_TABLE_NAME, values, Words._ID + "=" + wordId
+ (!TextUtils.isEmpty(where) ? " AND (" + where + ')' : ""), whereArgs);
break;
default:
throw new IllegalArgumentException("Unknown URI " + uri);
}
// Only the enabled IMEs and spell checkers can access this provider.
if (!canCallerAccessUserDictionary()) {
return 0;
}
getContext().getContentResolver().notifyChange(uri, null);
mBackupManager.dataChanged();
return count;
}Finally, notice how the AndroidManifest.xml file does not provide any additional protection (e.g. intent filters or permissions) to the explicitly exported content provider:
<manifest xmlns:android="http://schemas.android.com/apk/res/android"
package="com.android.providers.userdictionary"
android:sharedUserId="android.uid.shared">
<application android:process="android.process.acore"
android:label="@string/app_label"
android:allowClearUserData="false"
android:backupAgent="DictionaryBackupAgent"
android:killAfterRestore="false"
android:usesCleartextTraffic="false"
>
<provider android:name="UserDictionaryProvider"
android:authorities="user_dictionary"
android:syncable="false"
android:multiprocess="false"
android:exported="true" />
</application>
</manifest>
It is trivial for an attacker to update the content of the user dictionary by invoking code like the following from any malicious application, without the need to ask for any permission:
ContentValues values = new ContentValues();
values.put(UserDictionary.Words.WORD, "IOActive");
getContentResolver().update(UserDictionary.Words.CONTENT_URI, values,
null, null);It would be also trivial to delete any content, including the entire personal dictionary:
getContentResolver().delete(UserDictionary.Words.CONTENT_URI, null, null);Both methods (update and delete) are supposed to return the number of affected rows, but in this case (for non-legitimate invocations) they will always return zero, making it slightly more difficult for an attacker to extract or infer any information from the content provider.
At this point, it may appear that this is all we can do from an attacker perspective. While deleting or updating arbitrary entries could be a nuisance for the end user, the most interesting part is accessing personal data.
Even if the query function is not directly affected by this vulnerability, it is still possible to dump the entire contents by exploiting a time-based, side-channel attack. Since the where argument is fully controllable by the attacker, and due to the fact that a successful update of any row takes more time to execute than the same statement when it does not affect any row, the attack described below was proven to be effective.
Simple Proof of Concept
Consider the following code fragment running locally from a malicious application:
ContentValues values = new ContentValues();
values.put(UserDictionary.Words._ID, 1);
long t0 = System.nanoTime();
for (int i=0; i<200; i++) {
getContentResolver().update(UserDictionary.Words.CONTENT_URI, values,
"_id = 1 AND word LIKE 'a%'", null);
}
long t1 = System.nanoTime();Invoking the very same statement enough times (e.g. 200 times, depending on the device), the time difference (t1-t0) between an SQL condition that evaluates to “true” and the ones that evaluate to “false” will be noticeable, allowing the attacker to extract all the information in the affected database by exploiting a classic time-based, Boolean blind SQL injection attack.
Therefore, if the first user-defined word in the dictionary starts with the letter “a”, the condition will be evaluated to “true” and the code fragment above will take more time to execute (for example, say 5 seconds), compared to the lesser time required when the guess is false (e.g. 2 seconds), since no row will actually be updated in that case. If the guess was wrong, we can then try with “b”, “c”, and so on. If the guess is correct, it means that we know the first character of the word, so we can proceed with the second character using the same technique. Then, we can move forward to the next word and so on until we dump the entire dictionary or any filterable subset of rows and fields.
To avoid altering the database contents, notice how we updated the “_id” column of the retrieved word to match its original value, so the inner idempotent statement will look like the following:
UPDATE words SET _id=N WHERE _id=N AND (condition)
If the condition is true, the row with identifier “N” will be updated in a way that doesn’t actually change its identifier, since it will be set to its original value, leaving the row unmodified. This is a non-intrusive way to extract data using the execution time as a side-channel oracle.
Because we can replace the condition above with any sub-select statement, this attack can be extended to query any SQL expression supported in SQLite, such as:
- Is the word ‘something’ stored in the dictionary?
- Retrieve all 16-character words (e.g. credit card numbers)
- Retrieve all words that have a shortcut
- Retrieve all words that contain a dot
Real-world Exploitation
The process described above can be fully automated and optimized. I developed a simple Android application to prove its exploitability and test its effectiveness.
The proof-of-concept (PoC) application is based on the assumption that we can blindly update arbitrary rows in the UserDictionary database through the aforementioned content provider. If the inner UPDATE statement affects one or more rows, it will take more time to execute. This is essentially all that we will need in order to infer whether an assumption, in the form of a SQL condition, is evaluated to true or false.
However, since at this initial point we don’t have any information about the content (not even the values of the internal identifiers), instead of iterating through all possible identifier values, we’ll start with the row with the lowest identifier and smash the original value of its “frequency” field to an arbitrary number. This step could be done using different valid approaches.
Because several shared processes will be running at the same time in Android, the total elapsed time for the same invocation will vary between different executions. Also, this execution time will depend on each device’s processing capabilities and performance; however, from a statistical perspective, repeating the same invocation a significant amount of iterations should give us a differentiable measure on average. That’s why we’ll need to adjust the number of iterations per device and current configuration (e.g. while in battery saving mode).
Although I tried with a more complex approach first to determine if a response time should be interpreted as true or false, I ended up implementing a much simpler approach that led to accurate and reliable results. Just repeat the same number of requests that always evaluate to “true” (e.g. “WHERE 1=1”) and “false” (e.g. “WHERE 1=0”) and take the average time as the threshold to differentiate them. Measured times greater than the threshold will be interpreted as true; otherwise, as false. It’s not AI or big data, nor does it use blockchain or the cloud, but the K.I.S.S. principle applies and works!
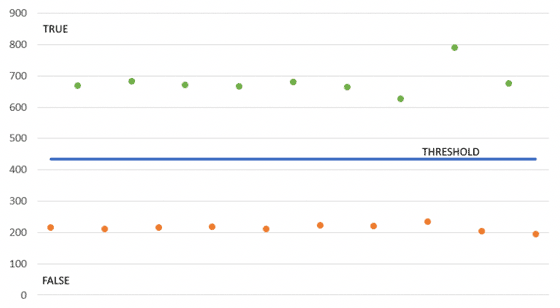
Once we have a way to differentiate between correct and wrong assumptions, it becomes trivial to dump the entire database. The example described in the previous section is easy to understand, but it isn’t the most efficient way to extract information in general. In our PoC, we’ll use the binary search algorithm4 instead for any numeric query, using the following simple approach:
- Determine the number of rows of the table (optional)
SELECT COUNT(*) FROM words
- Determine the lowest identifier
SELECT MIN(_id) FROM words
- Determine the number of characters of the word with that identifier
SELECT length(word) FROM words WHERE _id=N
- Iterate through that word, extracting character by character (in ASCII/Unicode)
SELECT unicode(substr(word, i, 1)) FROM words WHERE _id=N
- Determine the lowest identifier which is greater than the one we got and repeat
SELECT MIN(_id) FROM words WHERE _id > N
Remember that we can’t retrieve any numeric or string value directly, so we’ll need to translate these expressions into a set of Boolean queries that we can evaluate to true or false, based on their execution time. This is how the binary search algorithm works. Instead of querying for a number directly, we’ll query: “is it greater than X?” repeatedly, adjusting the value of X in each iteration until we find the correct value after log(n) queries. For instance, if the current value to retrieve is 97, an execution trace of the algorithm will look like the following:
| Iteration | Condition | Result | Max | Min | Mid |
|---|---|---|---|---|---|
| – | – | – | 255 | 0 | 127 |
| 1 | Is N > 127? | No | 127 | 0 | 63 |
| 2 | Is N > 63? | Yes | 127 | 63 | 95 |
| 3 | Is N > 95? | Yes | 127 | 95 | 111 |
| 4 | Is N > 111? | No | 111 | 95 | 103 |
| 5 | Is N > 103? | No | 103 | 95 | 99 |
| 6 | Is N > 99? | No | 99 | 95 | 97 |
| 7 | Is N > 97? | No | 97 | 95 | 96 |
| 8 | Is N > 96? | Yes | 97 | 96 | 96 |
The Proof-of-Concept Exploitation Tool
The process described above was implemented in a PoC tool, shown below. The source code and compiled APK for this PoC can be accessed from the following GitHub repository: https://github.com/IOActive/AOSP-ExploitUserDictionary
Let’s have a look at its minimalistic user interface and explain its singularities.
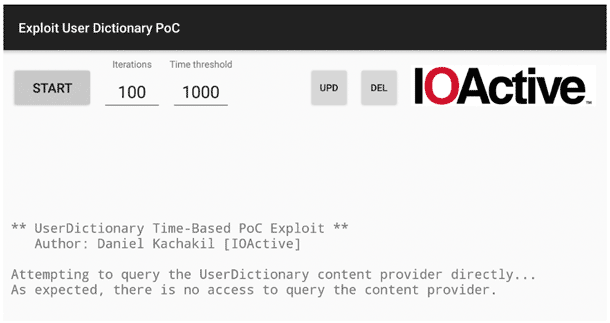
The first thing the application does is attempt to access the personal dictionary content provider directly, querying the number of entries. Under normal circumstances (not running as root, etc.), we should not have access. If for any reason we achieve direct access, it doesn’t make sense to exploit anything using a time-based, blind approach, but even in that case, you’ll be welcome to waste your CPU cycles with this PoC instead of mining cryptocurrencies.
As described before, there are only two parameters to adjust:
- Initial number of iterations: How many times will the same call be repeated to get a significant time difference.
- Minimum time threshold (in milliseconds): How much time will be considered the lowest acceptable value.
Although the current version of the tool will adjust them automatically for us, in the very first stage everything was manual and the tool was simply taking these parameters as they were provided, so this is one of the reasons why these controls exist.
In theory, the larger these numbers are, the better accuracy we’ll get, but the extraction will be slower. If they are smaller, it will run faster, but it’s more likely to obtain inaccurate results. This is why there is a hardcoded minimum of 10 iterations and 200 milliseconds.
If we press the “START” button, the application will start the auto-adjustment of the parameters. First, it will run some queries and discard the results, as the initial ones were usually quite high and not representative. Then, it will execute the initial number of iterations and estimate the corresponding threshold. If the obtained threshold is above the minimum we configured, then it will test the estimated accuracy by running 20 consecutive queries, alternating true and false statements. If the accuracy is not good enough (only one mistake will be allowed), then it will increase the number of iterations and repeat the process a set number of times until the parameters are properly adjusted or give up and exit if the conditions couldn’t be satisfied.
Once the process is started, some controls will be disabled, and we’ll see the current verbose output in the scrollable log window below (also via logcat) where we can see, among other messages, the current row identifier, all SQL subqueries, the total time, and the inferred trueness. The retrieved characters will appear in the upper line as soon as they’re extracted.
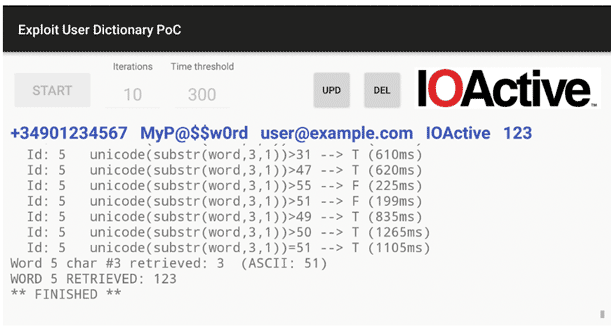
Finally, the “UPD” and “DEL” buttons on the right are completely unrelated to the time-based extraction controls, and they simply implement direct calls to the content provider to perform an UPDATE and DELETE, respectively. They were intentionally limited to affect the words starting with “123” only. This was done to avoid accidental deletions of any personal dictionary, so in order to test these methods, we’ll need to add this entry manually, unless we had it already.
Demo
Probably the easiest way to summarize the process is watching the tool in action in the following videos, recorded in a real device.
Additional Considerations
There is usually a gap between theory and practice, so I’d also like to share some of the issues I faced during the design and development of this PoC. First, bear in mind that the tool is simply a quick and dirty PoC. Its main goal was to prove that the exploitation was possible and straightforward to implement, and that’s why it has several limitations and doesn’t follow many of the recommended programming best practices, as it’s not meant to be maintainable, efficient, offer a good user experience, etc.
In the initial stages, I didn’t care about the UI and everything was dumped to the Android log output. When I decided to show the results in the GUI as well, I had to run all the code in a separate thread to avoid blocking the UI thread (which may cause the app to be considered unresponsive and therefore killed by the OS). The accuracy dropped considerably with this simple change, because that thread didn’t have much priority, so I set it to “-20”, which is the maximum allowed priority, and everything worked fine again.
Updating the UI from a separate thread may lead to crashes and it’s generally detected and restricted via runtime exceptions, so in order to show the log messages, I had to invoke them using calls to runOnUiThread. Bear in mind that in a real exploit, there’s no need for a UI at all.
If the personal dictionary is empty, we can’t use any row to force an update, and therefore all queries will take more or less the same time to execute. In this case there’ll be nothing to extract and the tool shouldn’t be able to adjust the parameters and will eventually stop. In some odd cases, it might be randomly calibrated even with an empty database and it will try to extract garbage or pseudo-random data.
In a regular smartphone, the OS will go to sleep mode after a while and the performance will drop considerably, causing the execution time to increase way above the expected values, so all calls would be evaluated as true. This could have been detected and reacted in a different manner, but I simply opted for a simpler solution: I kept the screen turned on and acquired a wake lock via the power manager to prevent the OS from suspending the app. I didn’t bother to release it afterwards, so you’ll have to kill the application if you’re not using it.
Rotating the screen also caused problems, so I forced it to landscape mode only to avoid auto-rotating and to take advantage of the extra width to show each message in a single line.
Once you press the “START” button, some controls will be permanently disabled. If you want to readjust the parameters or run it multiple times, you’ll need to close it and reopen it.
Some external events and executions in parallel (e.g. synchronizing the email, or receiving a push message) may interfere with the application’s behavior, potentially leading to inaccurate results. If that happens, try it again in more stable conditions, such as disabling access to the network or closing all other applications.
The UI doesn’t support internationalization, and it wasn’t designed to extract words in Unicode (although it should be trivial to adapt, it wasn’t my goal for a simple PoC).
It was intentionally limited to extract the first 5 words only, sorted by their internal identifiers.
Remediation
From a source code perspective, the fix is very simple. Just moving the call to check if the caller has permissions to the beginning of the affected functions should be enough to fix the issue. Along with the advisory, we provided Google a patch file with the suggested fix and this was the commit in which they fixed the vulnerability:
https://android.googlesource.com/platform/packages/…
Since the issue has been fixed in the official repository, as end users, we’ll have to make sure that our current installed security patch level contains the patch for CVE-2018-9375. For instance, in Google Pixel/Nexus, it was released on June 2018:
https://source.android.com/security/bulletin/pixel/2018-06-01
If for any reason it’s not possible to apply an update to your device, consider reviewing the contents of your personal dictionary and make sure it doesn’t contain any sensitive information in the unlikely event the issue becomes actively exploited.
Conclusions
Software development is hard. A single misplaced line may lead to undesirable results. A change that was meant to improve the security and protection of the user’s personal dictionary, making it less accessible, led to the opposite outcome, as it inadvertently allowed access without requiring any specific permission and went unnoticed for almost three years.
Identifying a vulnerability like the one described here can be as easy as reading and understanding the source code, just following the execution flow. Automated tests may help detect this kind of issue at an early stage and prevent them from happening again in further changes, but they aren’t always that easy to implement and maintain.
We also learned how to get the most from a vulnerability that, in principle, only allowed us to destroy or tamper with data blindly, increasing its final impact to an information disclosure that leaked all the data by exploiting a side-channel, time-based attack.
Always think outside the box, and remember: time is one of the most valuable resources. Every nanosecond counts!
2 Gerrit’s Change-Id: I6c5716d4d6ea9d5f55a71b6268d34f4faa3ac043
https://android.googlesource.com/platform/packages/providers/…
3 At the time of discovery, it was found in the AOSP master branch:
https://android.googlesource.com/platform/packages/providers/UserDictionaryProvider/…
After the fix, the equivalent contents can be found in the following commit:
https://android.googlesource.com/platform/packages/providers/UserDictionaryProvider/…
4 https://en.wikipedia.org/wiki/Binary_search_algorithm