
The other week I was invited to keynote at the ISSA CISO Forum on Incident Response in Dallas and in the weeks prior to it I was struggling to decide upon what angle I should take. Should I be funny, irreverent, diplomatic, or analytical? Should I plaster slides with the last quarter’s worth of threat statistics, breach metrics, and headline news? Should I quip some anecdote and hope the attending CISO’s would have an epiphany that’ll fundamentally change the way they secure their organizations?
If you attended RSA USA (or any major security vendor/booth conference) this year you can’t have missed the fact that everything from Antivirus through to USB memory sticks now come with a dab of big data, a sprinkling of machine learning, and a dollop of cloud for good measure. Thankfully I’m a cynic; or else I’d have been thrashing around on the ground in an epileptic fit from all the flashy marketing claims and trademarked nonsense phrases.
I guess I’m lucky to be in the position of having had several years of exposure to some of the greatest minds at Georgia Tech as they drummed in to me on a daily basis the “what and how” of machine learning in the context of solving many of today’s toughest security problems.
What was the net result of this self-inflection and impending deadline? I crafted a short presentation for CISO’s… a 101 course on machine learning and big data… and it included ducks.
If you’re in the upper tiers of your organization and you’ve had sales folks pimping you their latest cloud-infused, big data-munching, machine learning, and world-hunger-solving security solution, please carry on reading as I attempt to explain the basics of the latest and greatest in buzzwords…

Now I could easily spend another 5,000 words explaining why such an idiom doesn’t apply to modern security threats, targeted attacks and advanced persistent threats, but you’ll have to wait for a different blog post. Rather, for this 101 lesson, it’s important to understand the concept of “Feature Selection” – which in the case of this idiom includes: walking, flying and quacking.
If you’ve been tasked with dealing with a duck problem, ideally you’d be an aficionado on the feet, wings and sounds of ducks. You’d be able to apply this knowledge to each bird you have the time to focus your attention on and make a determination: Duck, or Not a Duck. As a security professional, you’d be versed in the various attributes of certain threats – and able to derive a conclusion as to the nature of the security problem.

Meanwhile, making decisions and taking actions upon the data is typically the most difficult part. With every doubling of data, your problem grows exponentially.


If those features (or parameters) used for classification are too narrow (or too broad) then evasion is not only probable, but guaranteed. In essence, for a threat (or duck) to be classified, it must have been observed in the past or carefully predicted (although rare).
From an attacker’s perspective, knowledge of those features and triggering parameters makes it a trivial task to evade or to conduct false flag operations. Just think – hunters do this all the time with their floating duck decoys. Even fellow duck hunters have been known to mistakenly take pot-shots at them too.
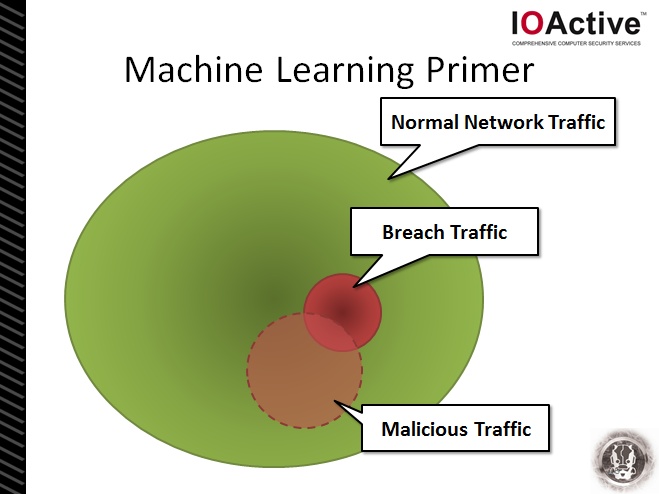
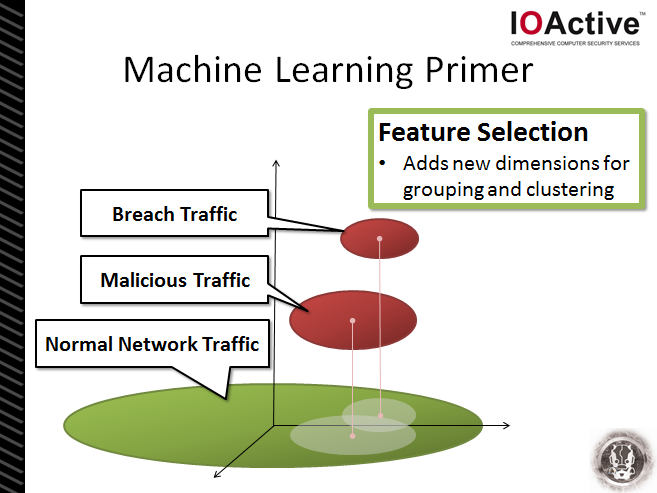
The trick in differentiating between the network traffic types lies in increasing the dimensionality of the problem. What was a two-dimensional blob suddenly becomes much clearer when an appropriate view or perspective to the data is added. In the context of the above diagram, the addition of a z-axis and an extension in to the third-dimension allows the observer (i.e. analyst) to easily differentiate between the traffic types – for example, the axis could represent “country code of destination IP address”. In this context, the appropriate feature selection can greatly simplify the detection problem. Choosing appropriate features is important – nay, it’s critical!
This is where advances in machine learning over the last half-decade have really come to the fore in computer science and more recently in information security.

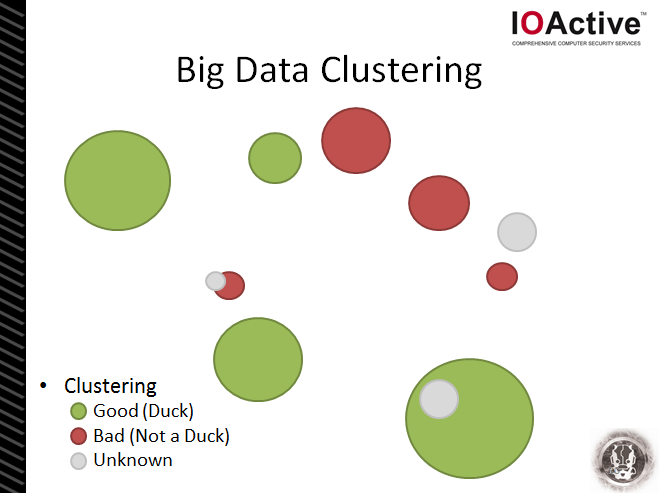
So, in this example we’ve taken a bunch of ducks and grouped them together. They become our “+ve class” – which basically means these are the things we’re interested in. But, equally important, is our “-ve class” – our collection of things we know not to be ducks. In many cases our -ve class may be more important than our +ve class because it contains all those false positives and “nearly” ducks – the things that may have caught us out once before.

The number of features reviewed, assessed and weighted by the machine learning system will eventually be determined by the type of data being used and how “rich” it is. For example, in the network security realm we may be feeding the system with collated samples of firewall logs, DNS traffic samples, IP blacklists/whitelists, IPS alerts, etc. It’s important to note though that the “richer” the data set (i.e. the more possible features there could be), the more complex the problem is for the computer to solve and the longer it’ll take to train the system.
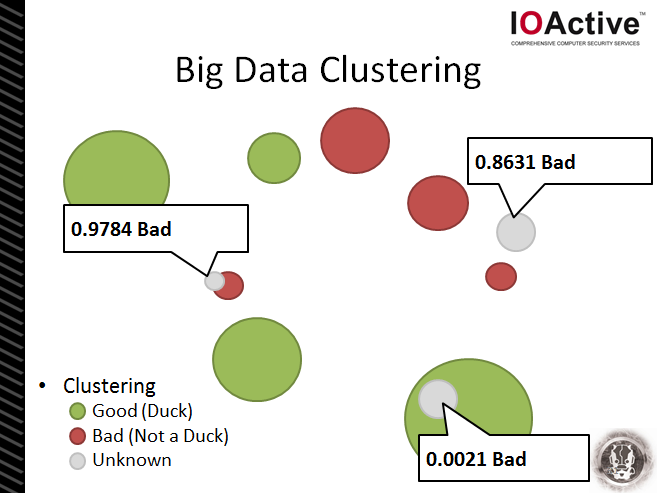
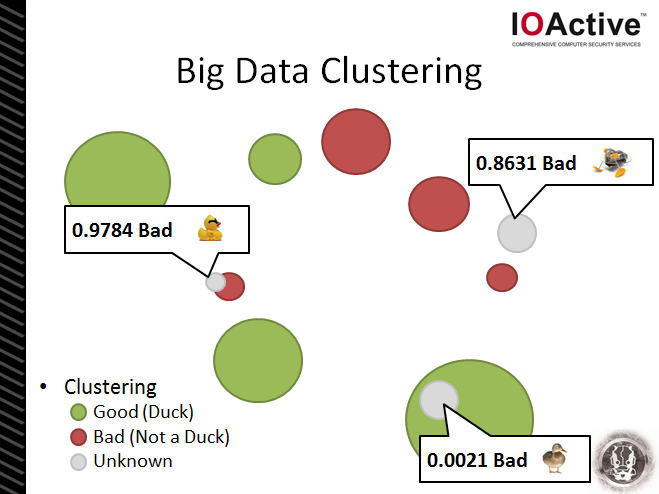
Then, to improve our machine learning system further, we add these newly labeled clusters to our +ve and -ve training sets… and the system continues to learn and become more precise over time.
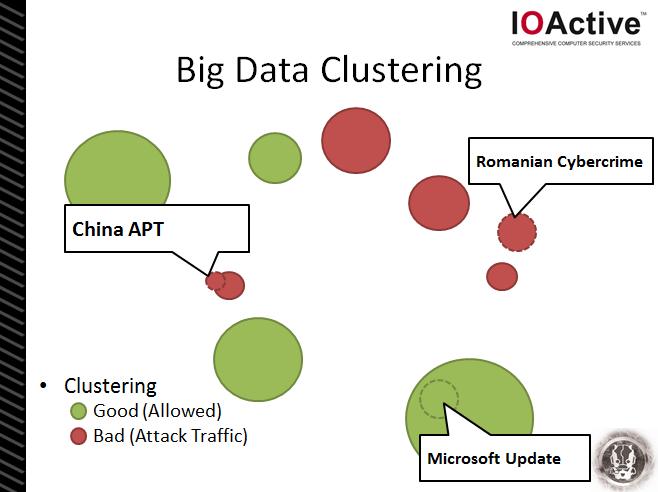
And, if we’re a really smart CISO, we can use this clustering system (and labeled clusters) to automatically alert us to new threats or to initiate automatic network security actions – e.g. enable blocking of a new malicious URL, stop blocking a new cloud service delivering official updates to applications, etc.
The application of machine learning techniques to the toughest security problems facing business today has come along in leaps and bounds recently. However as with any buzz word that falls in to the hands of marketers and gets manipulated until it squeaks and glitters, or oozes onto every product in this year’s price list, senior technical staff need to take added care not to be bamboozled by well-practiced but meaningless word salad.