The Internet is ablaze with talk of the “heartbleed” OpenSSL vulnerability disclosed yesterday (April 7, 2014) here: https://www.openssl.org/news/secadv_20140407.txt
While the bug itself is a simple “missing bounds check,” it affects quite a number of high-volume, big business websites.
Make no mistake, this bug is BAD. It’s sort of a perfect storm: the bug is in a library used to encrypt sensitive data (OpenSSL), and it allows attackers a peak into a server’s memory, potentially revealing that same sensitive data in the clear.
Initially, it was reported that private keys could be disclosed via this bug, basically allowing attackers to decrypt captured SSL sessions. But as more people start looking at different sites, other issues have been revealed – servers are leaking information ranging from user sessions (https://www.mattslifebytes.com/?p=533) to encrypted search queries (duckduckgo) and passwords (https://twitter.com/markloman/status/453502888447586304). The type of information accessible to an attacker is entirely a function of what happens to be in the target server’s memory at the time the attacker sends the request.
While there’s lot of talk about the bug and its consequences, I haven’t seen much about what actually causes the bug. Given that the bug itself is pretty easy to understand (and even spot!), I thought it would be worthwhile to walk through the vulnerability here for those of you who are curious about the why, and not just the how-to-fix.
The Bug
The vulnerable code is found in OpenSSL’s TLS Heartbeat Message handling routine – hence the clever “heartbleed” nickname. The TLS Heartbeat protocol is defined in RFC 6520 – “Transport Layer Security (TLS) and Datagram Transport Layer Security (DTLS) Heartbeat Extension”.
Before we get into the OpenSSL code, we should examine what this protocol looks like.
The structure of the Heartbeat message is very simple, consisting of a 8-bit message type, a 16-bit payload length field, the payload itself, and finally a sequence of padding bytes. In pseudo-code, the message definition looks like this (copied from the RFC):
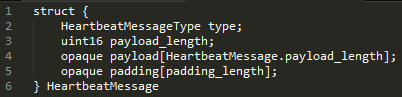
The type (line 2) is simply 1 or 2, depending on whether the message is a request or a response.
The payload_length (line 3) indicates the size of the payload part of the message, which follows immediately. Being a 16-bit unsigned integer, its maximum value is 2^16-1 (which is 65535). If you’ve done some other reading about this bug, you’ll recognize the 64k as being the upper limit on how much data can be accessed by an attacker per attack sent.
The payload (line 4) is defined to be “arbitrary content” of length payload_length.
And padding (line 5) is “random content” at least 16 bytes long, and “MUST be ignored.”
Easy enough!
Now I think it should be noted here that the RFC itself appears sound – it describes appropriate behavior for what an implementation of the protocol should and shouldn’t do. In fact, the RFC explicitly states that “If the payload_length of a received HeartbeatMessage is too large, the received HeartbeatMessage MUST be discarded silently.” Granted, “too large” isn’t defined, but I digress…
There is one last part of the RFC that’s important for understanding this bug: The RFC states that “When a HeartbeatRequest message is received … the receiver MUST send a corresponding HeartbeatResponse message carrying an exact copy of the payload of the received HeartbeatRequest.” This is important in understanding WHY vulnerable versions of OpenSSL are sending out seemingly arbitrary blocks of memory.
Now, on to OpenSSL code!
Here’s a snippet from the DTLS Heartbeat handling function in (the vulnerable) openssl-1.0.1fssld1_both.c:
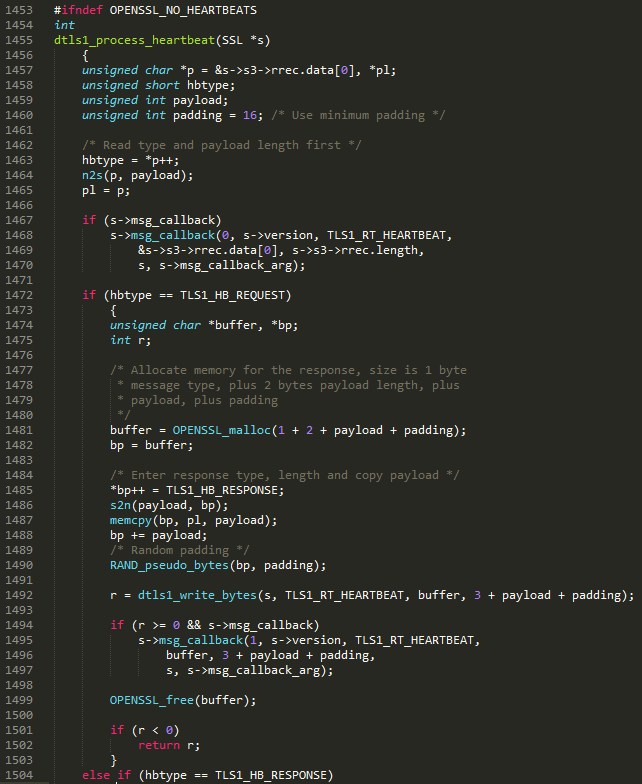
If you’re not familiar with reading C, this can be a lot to digest. The bug will become clearer if we go through this function piece by piece. We’ll start at the top…
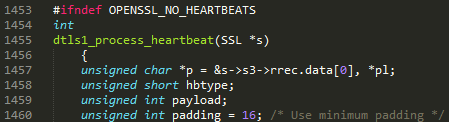
This part just defines local variables for the function. The most important one here is the char pointer p (line 1457), which points to the heartbeat message the attacker controls. hbtype (line 1458)will hold the HeartbeatMessageType value mentioned in the RFC, and payload (line 1459)will hold the payload_length value. Don’t let the fact that the payload_length value is being stored in the payload variable confuse you!

Here, the first byte of the message is copied into the hbtype variable (line 1463), and the 16-bit payload-length is copied from p (the attacker-controlled message) to the payload variable using the n2s function (line 1464). The n2s function simply converts the value from the sequence of bits in the message to a number the program can use in calculations. Finally, the pl pointer is set to point to the payload section of the attacker-controlled message (line 1465).
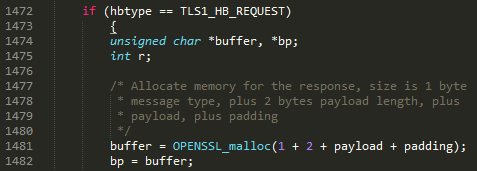
On line 1474, a variable called buffer is defined and then allocated (line 1481) an area of memory using the attacker-controlled payload variable to calculate how much memory should be allocated. Then, on line 1482, the bp pointer is set to point to the buffer that was just allocated for the server’s response.
As an aside, if the payload_length field which gets stored in the payload variable were greater than 16-bits (say, 32 or 64-bits instead), we’d be looking at another couple of vulnerabilities: either an integer overflow leading to a buffer overflow, or potentially a null-pointer dereference. The exact nature and exploitability of either of these would depend upon the platform itself, and the exact implementation of OPENSSL_malloc. Payload_length *is* only 16-bits however, so we’ll continue…

This code snippet shows the server building the response. It’s here that this bug changes from being an attacker-controlled length field leading to Not Very Much into a serious information disclosure bug causing a big stir. Line 1485 simply sets the type of the response message pointed to by bp to be a Heartbeat Response. According to the RFC, the payload_length should be next, and indeed – it is being copied over to the bp response buffer via the s2n function on line 1486. The server is just copying the value the attacker supplied, which was stored in the payload variable. Finally, the payload section of the attacker message (pointed to by pl, on line 1465) is copied over to the response buffer, pointed to by the bp variable (again, according to the RFC specification), which is then sent back to the attacker.
And herein lies the vulnerability – the attacker-controlled payload variable (which stores the payload_length field!) is used to determine exactly how many bytes of memory should be copied into the response buffer, WITHOUT first being checked to ensure that the payload_length supplied by the attacker is not bigger than the size of the attacker-supplied payload itself.
This means that if an attacker sends a payload_length greater than the size of the payload, any data located in the server’s memory after the attacker’s payload would be copied into the response. If the attacker set the payload_length to 10,000 bytes and only provided a payload of 10 bytes, then a little less than an extra 10,000 bytes of server memory would be copied over to the response buffer and sent back to the attacker. Any sensitive information that happened to be hanging around in the process (including private keys, unencrypted messages, etc.) is fair game. The only variable is what happens to be in memory. In playing with some of the published PoCs against my own little test server (openssl s_server FTW), I got a whole lot of nothing back, in spite of targeting a vulnerable version, because the process wasn’t doing anything other than accepting requests. To reiterate, the data accessed entirely depends on what’s in memory at the time of the attack.
Testing it yourself
There are a number of PoCs put up yesterday and today that allow you to check your own servers. If you’re comfortable using an external service, you can check out http://filippo.io/Heartbleed/. Or you can grab filippo’s golang code from https://github.com/FiloSottile/Heartbleed, compile it yourself, and test on your own. If golang is not your cup of tea, I’d check out the simple Python version here: https://gist.github.com/takeshixx/10107280. All that’s required is a Python2 installation.
Happy Hunting!