
Introduction
The rise of fraud and identity theft poses a growing concern for both individuals and organizations. As AI and deepfake technologies advance at an unprecedented pace, the need for a robust form of identity verification has become increasingly important. Traditional identity verification technology has become vulnerable to sophisticated attacks, such as spoofing, where fraudsters mimic someone’s identity. To combat the growing threat, identity providers integrated liveness detection to ensure the person undergoing verification is real, live, and physically present. However, as liveness detection evolves, fraudsters have adapted to bypass this protection.
In this article, we will explore how liveness detection, which is designed to distinguish real users from spoofed representations, can be undermined through the use of virtual devices. We will cover the tools and techniques, the setup process, and a demonstration of the bypasses. We will also discuss how criminals take advantage of the biometric data (facial images, voice recordings, and ID photos) individuals and organizations often unknowingly post and leave online. Finally, we will conclude with practical recommendations to help identity providers combat such attacks and improve their systems.
Understanding Remote Identity Proofing
Remote Identity Proofing (RIDP) is the process of verifying someone’s identity through digital channels without requiring their physical presence. This helps combat fraud by confirming the end users are real and who they claim to be. In sectors like banking, insurance, cryptocurrencies, and payments, RIDP has emerged as a key component of digital trust. RIDP also plays a big role in regulatory programs like Know Your Customer (KYC), Customer Due Diligence (CDD), and Anti‑Money Laundering (AML).
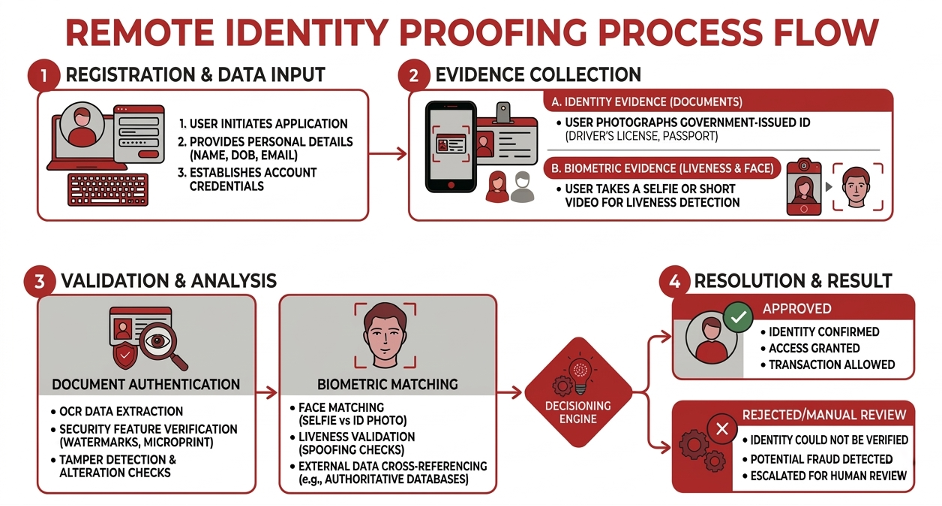
Common forms of RIDP include:
- Document validation, which relies upon the authenticity of government‑issued IDs such as passports or driver’s licenses.
- Biometric verification, such as facial recognition, fingerprint scanning, and voice authentication, which focuses on someone’s unique physical characteristics.
- Knowledge-based approaches, wherein multiple signals (e.g., passwords, PINs, OTPs) are collected.
Verification Methods & Their Attacks
This article focuses on the following forms of identity verification:
- Facial Recognition
- Document Validation
- Voice Authentication
Facial Recognition
Facial recognition is the process where a user’s facial features are captured, extracted, and compared against a database of faces to confirm identity. In practice, this makes the camera pipeline and its integrity (how the face data is acquired and delivered to the verification component) a critical security boundary.
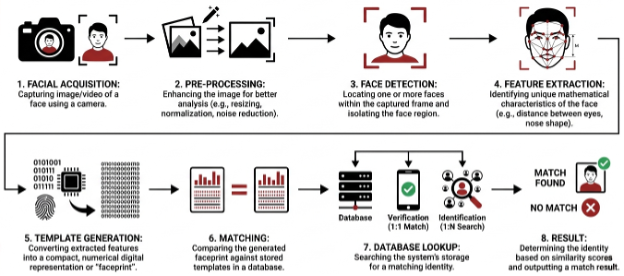
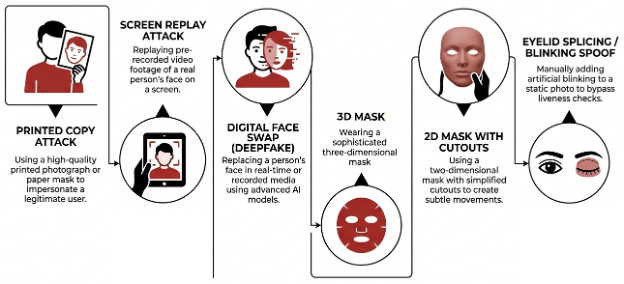
With this type of verification, fraudsters seek to impersonate a real person through Facial Spoofing, wherein a valid‑looking fake representation of the target is presented to the camera. This is typically carried out via:
- 2D Spoofing – presenting a printed photo or image displayed on a digital device (e.g., monitor or phone) to the camera.
- Video Replay – presenting a pre‑recorded video to the camera rather than a live capture.
- 3D/Silicon Masks – creating a 3D reconstruction of a face or a mask to simulate a face in a physically present form.
Document Validation
Another method is verifying the authenticity and validity of an identity document such as a passport, national ID, or driver’s license. This method, called Document Validation, typically includes checking visual and structural cues and determining whether the presented document is legitimate versus altered or fabricated.
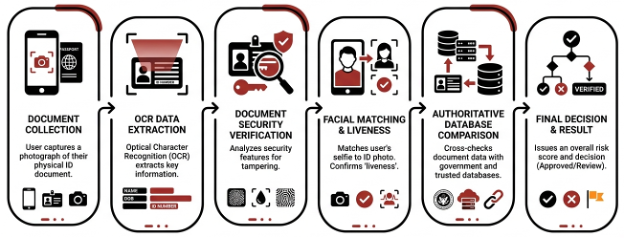
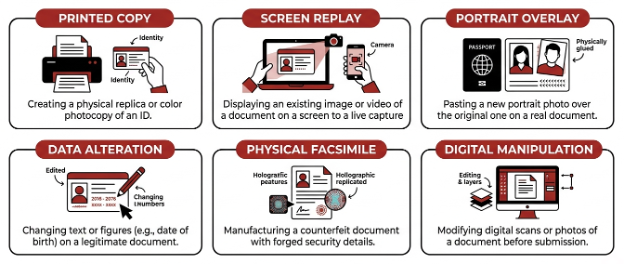
In an attempt to bypass document validation, fraudsters typically impersonate someone by presenting stolen, forged, or falsified documents. This is called Document Spoofing, and common methods include:
- Printed Copy – using a printed reproduction of an authentic or forged document.
- Screen Replay – presenting a legitimate (stolen) or forged document via a digital screen.
- Portrait Overlay/Substitution – placing someone else’s photo over the original photo in a legitimate document.
Voice Authentication
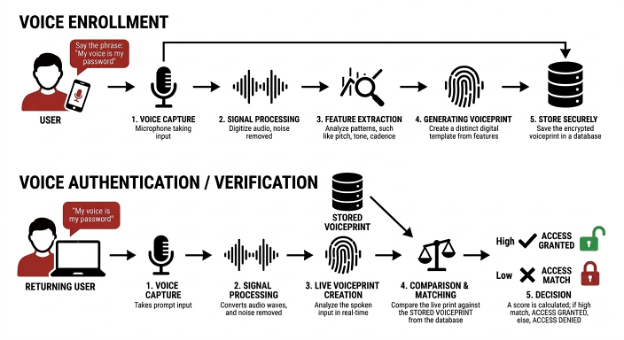
Voice authentication identifies a person based on the unique biological characteristics of their voice, including traits such as dynamics, pitch, intensity, and articulation. As with face and document capture, the trustworthiness of the capture channel (microphone input and the path from device to verification system) is foundational.
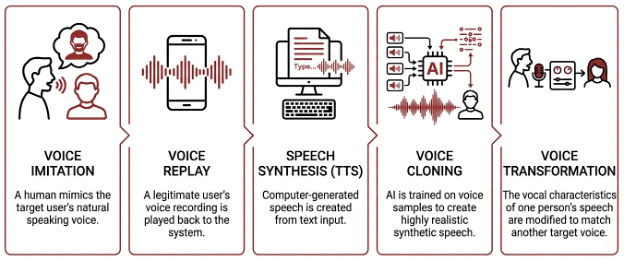
Speech Spoofing focuses on impersonating a target user by producing a voice output that matches the target’s “voice print/pattern” and speech behavior. Common methods are:
- Voice Imitation/Conversion – making the fraudster’s voice sound similar to the target’s voice.
- Speech Synthesis/Cloning – using AI and text‑to‑speech (TTS) technologies to generate a replica of the target’s voice.
- Voice Replay – using a pre‑recorded voice of the target
Liveness Detection as a Defensive Control
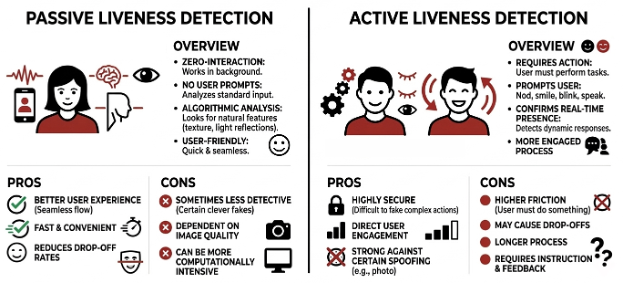
Liveness detection aims to prevent spoofing attacks by ensuring the user is live and physically or actively present at the time of the verification process rather than a recording or synthetic source. Liveness detection is implemented either passively or actively. With passive liveness detection, the verification system analyzes biometric signals without requiring explicit user interaction for a faster and seamless experience. As for active liveness detection, the system prompts users to perform actions such as head movements or speaking phrases to ensure users are actively/physically present during the verification process; however, it adds friction and inconvenience to some users.
The following demonstrates how liveness detection works for each verification system discussed above:
Facial Liveness
RIDP systems typically check for facial liveness using a combination of active and passive methods. Active liveness uses randomized challenge–response prompts, such as blinking or head movements, to confirm real‑time interaction. On the other hand, passive liveness runs in the background, analyzing depth cues, skin texture, light reflections, and subtle physiological signals that are difficult for photos, videos, or deepfakes to replicate.
Document Liveness
Instead of checking a document’s format or text alone, document liveness analyzes how a document interacts with light and motion. Real IDs exhibit natural reflections on holograms and laminates, realistic shadows, and consistent texture patterns. Screen replays and printed copies expose artifacts such as Moiré patterns (image distortion due to the overlapping grid pattern between the display and the camera capturing it), color limitations, or unnatural edges, which modern AI models are trained to detect within a single image or a short video capture.
Voice Liveness
Passive voice liveness analyzes spectral and temporal characteristics of speech, identifying artifacts common in text‑to‑speech, voice cloning, and replay attacks. Whereas active liveness adds challenge‑response prompts, requiring users to speak unpredictable phrases (instead of predefined ones) in real time, making replay and synthetic attacks far more difficult.
Injection Attacks Against Liveness Detection
As liveness detection matured and spoofing/replay attacks became easier to detect, threat actors shifted toward more sophisticated techniques. This led to the rise of injection attacks, which target the verification pipeline instead of the sensor. Instead of fooling the sensors by presenting falsified media to a camera or microphone, injection attacks feed prerecorded, manipulated, or synthetic biometric data directly into the application or API. This makes the system believe the input is legitimate, since the injected data is a bit-for-bit replica of the source media and is of high quality.
The following diagram illustrates the difference between a replay and an injection attack:
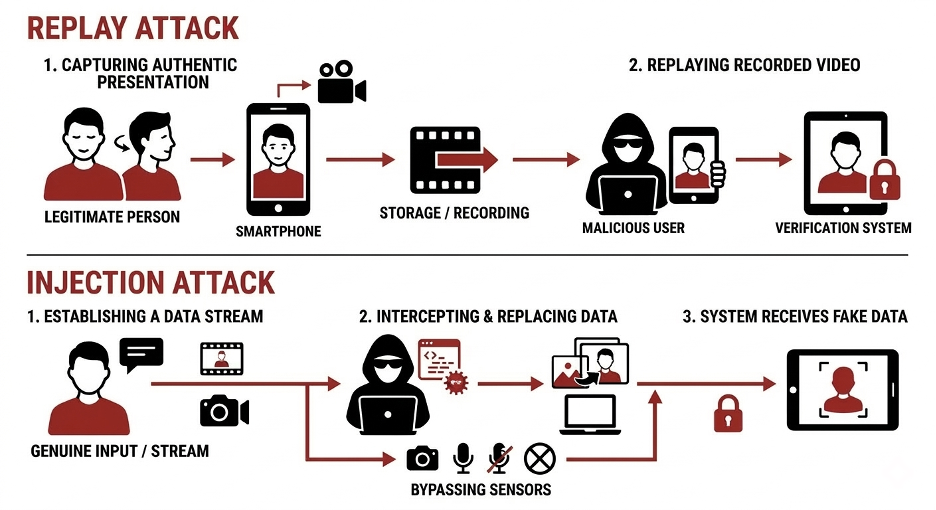
Typically, Injection Attack Methods (IAM) fall into two categories: attacks performed via modified or falsified devices and attacks performed via substitution of captured media.
Injection via Modified or Falsified Devices
In this type of attack, the attacker manipulates the capture environment itself so that falsified media is treated as legitimate. One approach involves the use of virtual devices, where software‑based cameras or microphones emulate physical hardware. These virtual components can present attacker‑controlled images, videos, or audio streams directly to the verification system while appearing as standard capture devices.

Another approach uses hardware modules inserted between the sensor and the RIDP system. In this method, the hardware intercepts and replaces genuine sensor output with attacker‑supplied data before it reaches the verification logic.

A third variant relies on device emulators, where the entire verification environment is simulated. Emulated devices can present falsified data while mimicking expected device characteristics, allowing attackers to test and refine injection techniques at scale.
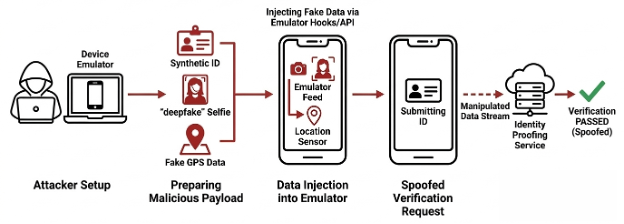
Injection via Substitution of Captured Media
Rather than altering the device itself, some threat actors may instead target the verification path that handles the captured media. One technique involves function hooking, where application- or system‑level functions responsible for camera or microphone input are intercepted and modified. This allows attackers to replace genuine capture data with prerecorded or synthetic media at runtime.
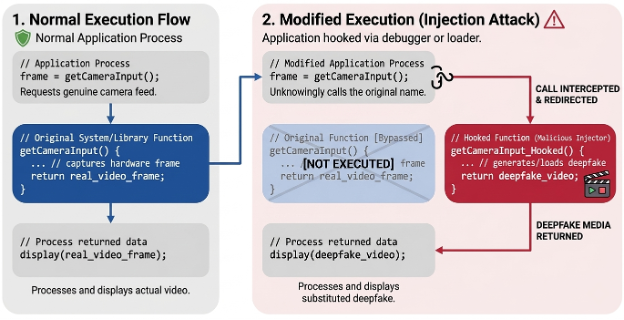
Another method relies on traffic interception, commonly described as a man‑in‑the‑middle (MiTM) scenario. In this case, media streams are intercepted and altered as they are transmitted between the client and backend services, enabling substitution without modifying the physical capture process.
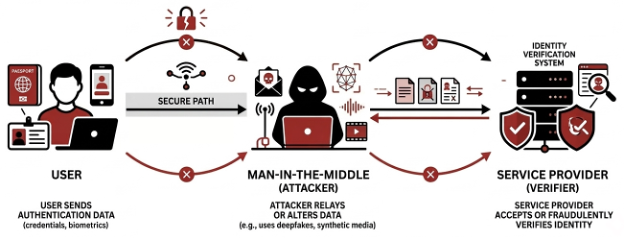
Using Virtual Devices to Circumvent Liveness Detection
The final area to address is the use of virtual devices as a cheap and simple means to defeat liveness detection implemented with different verification methods.
Virtual devices are software-based devices that mimic the capabilities of physical devices and allow users to select different source media (images, videos, audio, scenes, etc.) and feed them to other applications. Because virtual devices are inexpensive (mostly open-source), easy to configure, and widely used for legitimate purposes such as streaming and conferencing, they present a scalable and practical attack vector.
Attack Demonstration
Virtual Device Against Facial Liveness
Scenario: Instead of using the phone’s native camera for a live capture, a fraudster injects a pre-recorded video using a virtual camera.
Virtual Device Against Document Liveness
Scenario: Instead of using a camera to capture the ID, the fraudster uses a virtual camera to submit it to the RIDP system.
Virtual Device Against Voice Liveness
Scenario: Instead of speaking through a microphone, the fraudster submits an audio record to the RIDP system using a virtual audio cable.
Threats: Widespread Biometric Data Exposure
A major factor behind the growing success of identity theft and imposter scams is the widespread availability of biometric data. Identity impersonation is no longer a high‑effort operation. Today, attackers can obtain biometric artifacts of their victims remotely, quickly, and at scale. Identity theft and impersonation no longer depend on physical proximity to the victim; attackers can now acquire usable biometric samples remotely and at scale.
Social media platforms have effectively become open biometric repositories. Profile pictures, short‑form videos, and live streams expose high‑quality facial imagery and voice samples across a wide range of lighting conditions, angles, and expressions. For attackers, this content is often more than sufficient to fuel replay attacks, deepfake generation, or voice cloning. Vlogs and user‑generated video content further raise the bar by offering extended, natural recordings of both face and voice. These longer samples reveal behavioral nuances, such as speech rhythm, pauses, expressions, and movement patterns, that can be leveraged to evade passive liveness detection and behavioral analysis.


The most severe risk comes from database and KYC leaks, which may expose high‑resolution IDs, enrollment selfies, and voice samples.

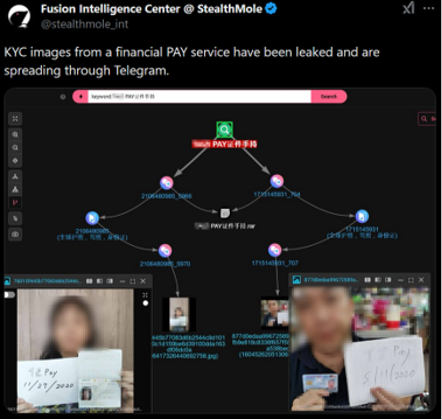
This level of biometric exposure fundamentally reshapes the RIDP threat model. Biometric data can no longer be treated as a protected secret. Instead, trust must shift toward verifiable capture integrity, proving that data was generated by a real sensor on a real device at a specific moment. Without strong capture‑time guarantees and device‑level assurance, even advanced liveness detection remains vulnerable to high‑fidelity impersonation attacks.
As biometric data becomes easier to obtain, the threat shifts from “Can attackers get the data?” to “Can systems reliably prove how and when the data was captured?” Addressing this shift is essential to defending modern RIDP deployments against scalable impersonation attacks.
Recommendations
To mitigate these risks, organizations should adopt a layered defense strategy, such as:
- Identifying virtual devices through metadata, hardware identifiers, and supported capabilities.
- Detecting emulated environments using hardware characteristics, sensor availability, performance profiles, and interaction patterns.
- Ensuring authenticity and fidelity through remote image attestation, cryptographic signing, timestamping, and challenge‑response mechanisms.
- Analyzing input data and session metadata for anomalies, mismatches, or missing sensor signals that indicate virtual sources.
- Switching to mobile‑only RIDP by taking advantage of mobile security features like Trusted Execution Environments and sensor telemetry.
- Combining multimodal verification and human review for high‑risk use cases, supported by logging and analysis of failed attempts.
Conclusion
Remote Identity Proofing is essential to modern digital ecosystems, but it operates in a constantly evolving adversarial environment. As replay attacks lose effectiveness, injection attacks pose a more serious challenge to liveness detection. RIDP systems should assume that the capture device itself may be untrusted and design controls accordingly.
Ultimately, securing remote identity verification remains a cat‑and‑mouse game, and defending them against threats requires more than a single control; it demands continuous improvement, layered defenses, and an in-depth understanding of both attacker capabilities and system limitations.
