For several decades, the science of steganography has been used to hide malicious code (useful in intrusions) or to create covert channels (useful in information leakage). Nowadays, steganography can be applied to almost any logical/physical medium (format files, images, audio, video, text, protocols, programming languages, file systems, BIOS, etc.). If the steganographic algorithms are well designed, the hidden information is really difficult to detect. Detecting hidden information, malicious or not, is so complex that the study of steganalytic algorithms (detection) has been growing. You can see the growth in scientific publications (source: Scholar Google) and research investment by governments or institutions.
In fact, since the attacks on September 11, 2001, there has been a lot of discussion on the possibility of terrorists using this technology. See:
In this post, I would like to illustrate steganography’s ability to hide data in Android applications. In this experiment, I focus on Android applications published in Google Play, leaving aside alternative markets with lower security measures, where it is easier to introduce malicious code.
Is it possible to hide information on Google Play or in the Android apps released in it?
The answer is easy: YES! Simple techniques have been documented, from hiding malware by renaming the file extension (Android / tr DroidCoupon.A – 2011, Android / tr SmsZombie.A – 2012, Android / tr Gamex.A – 2013) to more sophisticated procedures (AngeCryption – BlackHat Europe October2014).
Let me show some examples in more depth:
Google Play Web (https://play.google.com)
Google Play includes a webpage for each app with information such as a title, images, and a text description. Each piece of information could conceal data using steganography (linguistic steganography, image steganography, etc.). In fact, I am going to “work” with digital images and demonstrate how Google “works” when there is hidden information inside of files.
To do this, I will use two known steganographic techniques: adding information to the end of file (EOF) and hiding information in the least significant bit (LSB) of each pixel of the image.
–
PNG Images
You can upload PNG images to play.google.com that hide information using EOF or LSB techniques. Google does not remove this information.
For example, I created a sample app (automatically generated – https://play.google.com/store/apps/details?id=com.wMyfirstbaskeballgame) and uploaded several images (which you can see on the web) with hidden messages. In one case, I used the OpenStego steganographic tool (http://www.openstego.com/) and in another, I added the information at the end of an image with a hex editor.
The results can be seen by performing the following steps (analyzing the current images “released” on the website):
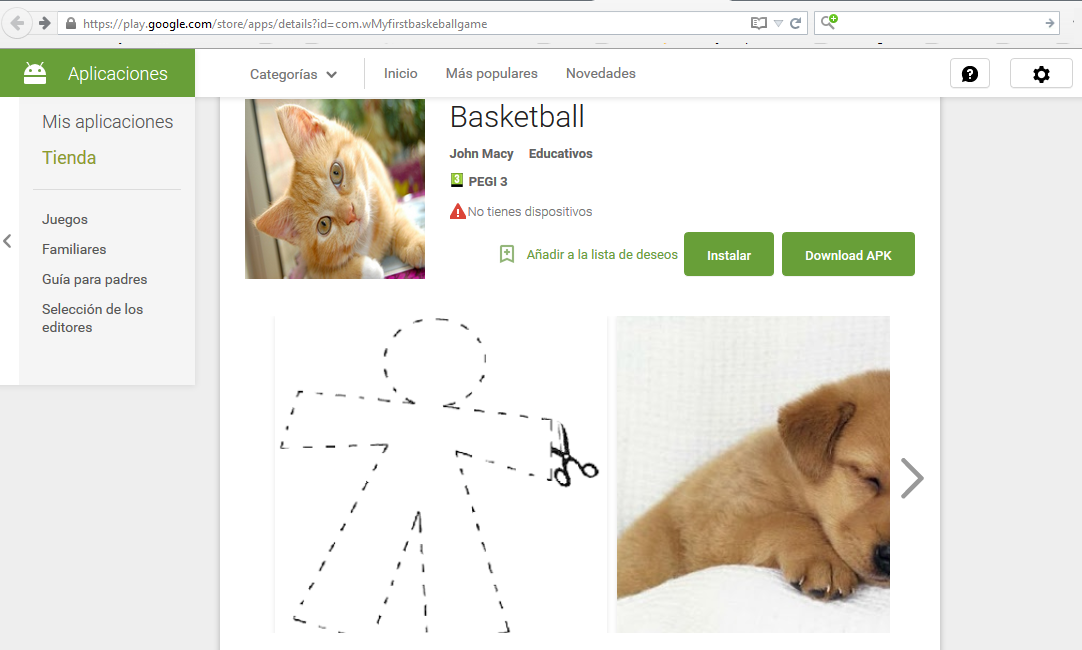
Example 1: PNG with EOF
Step 1: Save the image from URL (without =h900): https://lh3.googleusercontent.com/_H95_7MRo8yt7Oe3u8pD2pzElzBHYX4L3skE9Lc-Bf-8N6D7FxaslykwEH6XMGFRnw=h900)
Step 2: Loot at the end of the file 🙂


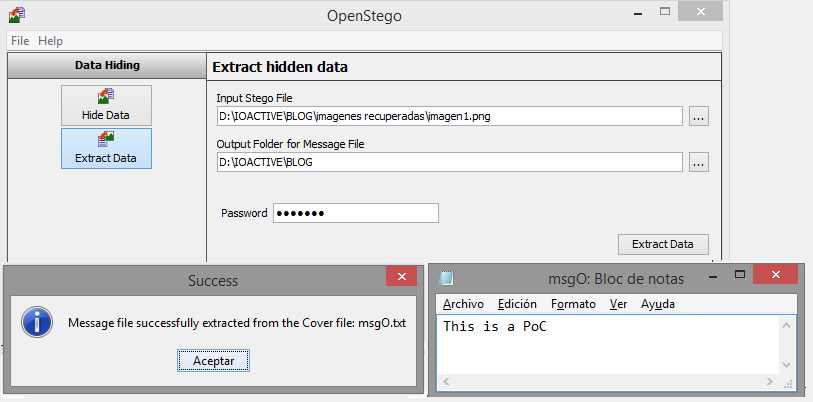
Example 2: PNG with LSB
Step 1: Save the image from URL (without =h310): https://lh3.googleusercontent.com/K4LJak3O4v5t-bCI1szXzV8tNNJpKw9_ppoN5nBKcl6dCQvgf2GNjJvWT1Kx-3Dxww=h310
Step 2: Recover the hidden information using Openstego (key=alfonso)
JPEG Images
If you try to upload a steganographic JPEG image (EOF or LSB) to Google Play, the hidden information will be removed. Google reprocesses the image before publishing it. This does not necessarily mean that it is not possible to hide information in this format. In fact, in social networks such as Facebook, we can “avoid” a similar problem with Secret Book or similar browser extensions. I’m working on it…
https://chrome.google.com/webstore/detail/secretbook/plglafijddgpenmohgiemalpcfgjjbph?hl=en-GB
In summary, based on the previous proofs, I can say that Google Play allows information to be hidden in the images of each app. Is this useful? It could be used to exchange hidden information (covert channel using the Google Play). The main question is whether an attacker could use information masked for some evil purpose. Perhaps they could use images to encode executable code that “will exploit” when you are visiting the web (using for example polyglots + stego exploits) or another idea. Time will tell…
APK Steganography
Applications uploaded toGoogle Play are not modified by the market. That is, an attacker can use any of the existing resources in an APK to hide information, and Google does not remove that information. For example, machine code (DEX), PNG, JPEG, XML, and so on.
Could it be useful to hide information on those resources?
An attacker might want to conceal malicious code on these resources and hinder automatic detection (static and dynamic analysis) that focuses on the code (DEX). A simple example would be an application that hides a specific phone number in an image (APT?).
The app verifies the phone number, and after a few clicks in a specific screen on a mobile phone, checks if the number is equal to that stored in the picture. If the numbers match, you can start leaking information (depending on the permissions allowed in the application).
I want to demonstrate the potential of Android stegomalware with a PoC. Instead of developing it, I will analyze an active sample that has been on Google Play since June 9, 2014. This stegomalware was developed by researchers at Universidad Carlos III de Madrid, Spain (http://www.uc3m.es). This PoC hides a DEX file (executable code) in an image (resource) of the main app. When the app is running, and the user performs a series of actions, the image recovers the “new” DEX file. This code runs and connects to a URL with a payload (in this case harmless). The “bad” behavior of this application can only be detected if we analyze the resources of the app in detail or simulate the interaction the app used for triggering the connection to the URL.
Let me show how this app works (static manual analysis):
Step 1: Download the APK to our local store. This requires a tool, such as an APK downloader extension or a specific web as http://apps.evozi.com/apk-downloader/
Step 2. Unzip the APK (es.uc3m.cosec.likeimage.apk)
Step 3. Using the Stegdetect steganalytic tool (https://github.com/abeluck/stegdetect) we can detect hidden information in the image “likeimage.jpg”. The author used the F5 steganographic tool (https://code.google.com/p/f5-steganography/).
es.uc3m.cosec.likeimageresdrawable-hdpilikeimage.jpg
likeimage.jpg : f5(***)
Step 4. To analyze (reverse engineer) what the app is doing with this image, I use the dex2jar and jd tools.
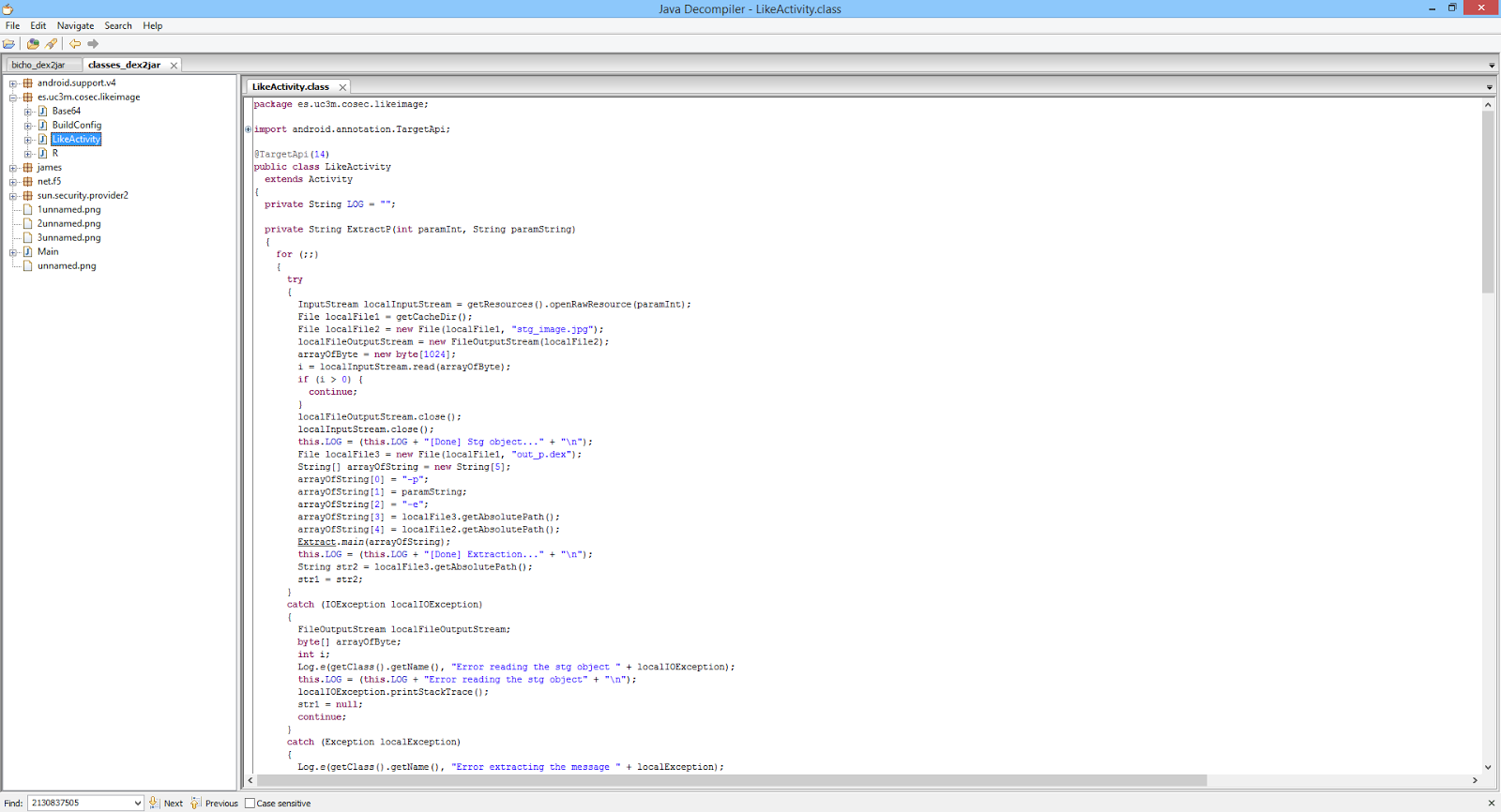
Step 5. Analyzing the code, we can observe the key used to hide information in the image. We can recover the hidden content to a file (bicho.dex).
java -jar f5.jar x -p cosec -e bicho.dex likeimage.jpg
Step 6. Analyzing the new file (bicho.dex), we can observe the connection to http://cosec-uc3m.appspot.com/likeimage for downloading a payload.
Step 7. Analyzing the code and payload, we can demonstrate that it is inoffensive.
ZGV4CjAzNQDyUt1DKdvkkcxqN4zxwc7ERfT4LxRA695kAgAAcAAAAHhWNBIAAAAAAAAAANwBAAAKAAAAcAAAAAQAAACYAAAAAgAAAKgAAAAAAAAAAAAAAAMAAADAAAAAAQAAANgAAABsAQAA+AAAACgBAAAwAQAAMwEAAD0BAABRAQAAZQEAAKUBAACyAQAAtQEAALsBAAACAAAAAwAAAAQAAAAHAAAAAQAAAAIAAAAAAAAABwAAAAMAAAAAAAAAAAABAAAAAAAAAAAACAAAAAEAAQAAAAAAAAAAAAEAAAABAAAAAAAAAAYAAAAAAAAAywEAAAAAAAABAAEAAQAAAMEBAAAEAAAAcBACAAAADgACAAEAAAAAAMYBAAADAAAAGgAFABEAAAAGPGluaXQ+AAFMAAhMTUNsYXNzOwASTGphdmEvbGFuZy9PYmplY3Q7ABJMamF2YS9sYW5nL1N0cmluZzsAPk1BTElDSU9VUyBQQVlMT0FEIEZST00gVEhFIE5FVDogVGhpcyBpcyBhIHByb29mIG9mIGNvbmNlcHQuLi4gAAtNQ2xhc3MuamF2YQABVgAEZ2V0UAAEdGhpcwACAAcOAAQABw4AAAABAQCBgAT4AQEBkAIAAAALAAAAAAAAAAEAAAAAAAAAAQAAAAoAAABwAAAAAgAAAAQAAACYAAAAAwAAAAIAAACoAAAABQAAAAMAAADAAAAABgAAAAEAAADYAAAAASAAAAIAAAD4AAAAAiAAAAoAAAAoAQAAAyAAAAIAAADBAQAAACAAAAEAAADLAQAAABAAAAEAAADcAQAA
The code that runs the payload:

Is Google detecting these “stegomalware”?
Well, I don’t have the answer. Clearly, steganalysis science has its limitations, but there are other ways to monitor strange behaviors in each app. Does Google do it? It is difficult to know, especially if we focus on “mutant” applications. Mutant applications are applications whose behavior could easily change. Detection would require continuous monitoring by the market. For example, for a few months I have analyzed a special application, including its different versions and the modifications that have been published, to observe if Google does anything with it. I will show the details:
Step 1. The mutant app is “Holy Quran video and MP3” (tr.com.holy.quran.free.apk). Currently at https://play.google.com/store/apps/details?id=tr.com.holy.quran.free
Step 2. Analyzing the current and previous version of this app, I discover connections to specific URLs (images files). Are these truly images? Not all.
Step 3. Two URLs that the app connects to are very interesting. In fact, they aren’t images but SQLite databases (with messages in Turkish). This is the trivial steganography technique of simply renaming the file extension. The author changed the content of these files:
Step 4. If we analyze these databases, it is possible to find curious messages. For example, recipes with drugs.
Is Google aware of the information exchanged using their applications? This example does not cease to be a mere curiosity, but such procedures might violate the policy of publication of certain applications on the market or more serious things.
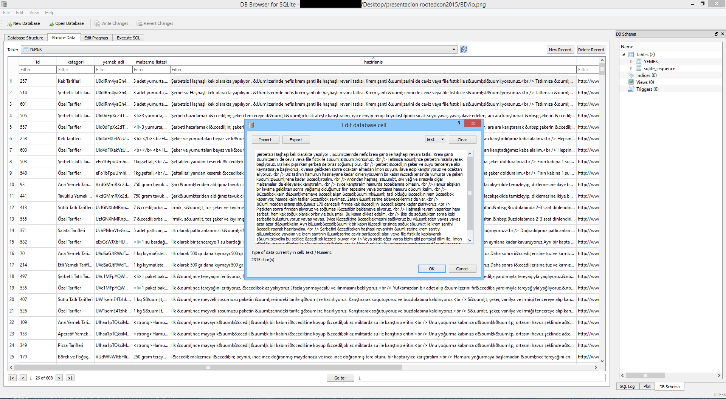

Figure: Recipes inside the file io.png (SQLite database)
In summary, this small experiment shows that we can hide information on Google Play and Android apps in general. This feature can be used to conceal data or implement specific actions, malicious or not. Only the imagination of an attacker will determine how this feature will be used…
Disclaimer: part of this research is based on a previous research by the author at ElevenPaths
Disclaimer: part of this research is based on a previous research by the author at ElevenPaths