
Disclaimer: I am not a statistician.
A particular style of telephone company directory allows callers to “dial by name” to reach a person, after playing the matching contacts’ names. In the example used here, input must be given as surname + given name with a minimum of three digits using the telephone keypad (e.g. Smith = 764). To cover all possible combinations, you’d calculate 8^3, or 512 combinations. With a directory that allowed repeated searches in the same call, it would take about seven hours of dialing to cover all possible combinations.


Let’s use available data to try and reduce the complexity of the problem while increasing the return on effort – like the giant nerds we are.
The 2000 U.S. Census provided raw data[1] on over 150,000 surnames occurring 100 or more times in the population. This puts the lowest occurrence of a surname in the data at 1 in 2,500,000. The uncounted surnames[2] represent 10.25% of people counted in the 2000 Census. This means our data only cover 89.75%* of the U.S. population, but we can safely assume† that the remaining names closely follow the patterns established in the data we do have available.
In this analysis, the first three characters of each surname in the Census data were converted into a three-digit combination using a telephone keypad conversion function. The resulting data were manipulated using an Excel pivot table to group matching combinations and sum the percentage of occurrence. This resulted in a table that ranked each combination. To facilitate the creation of interactive charts, this data was then imported into a Google Spreadsheet[3].
Results Summary
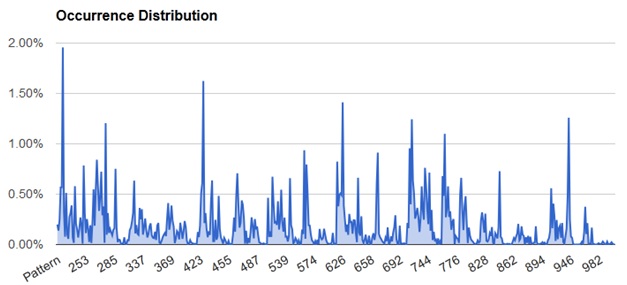
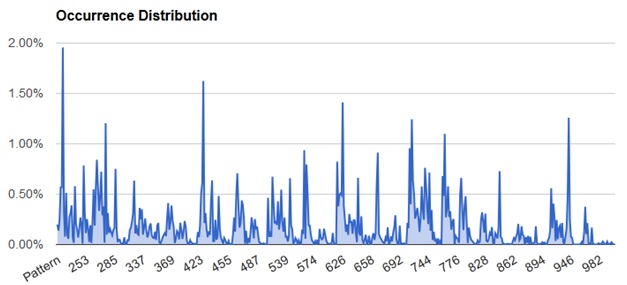
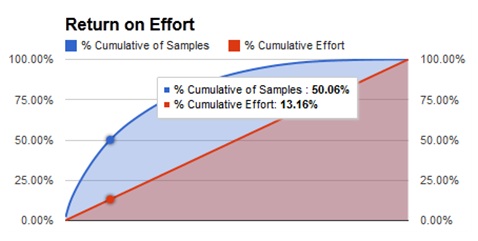
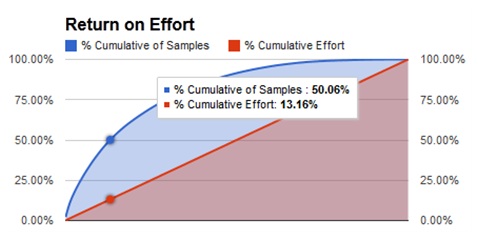
Unsurprisingly, the distribution of surnames for the patterns is non-uniform, with favorable spikes. Sorting by rank, we find the best pattern – 227 – should return 2% of the surnames for the average U.S. company. What’s more exciting is that we can use a smaller amount of effort to achieve a larger than expected amount of results. Searching by ascending rank to return 50% of the surnames, you only need to search 67 patterns, which is 13% of all possible combinations. To return 90% of the surnames you only need to search 241 patterns, which is 47% of all possible combinations. Some milestones are listed in the chart below.
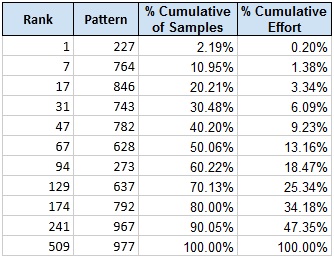
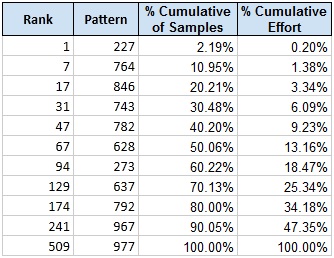
The following chart shows the curvilinear relationship of the expected returns versus the effort expended.
Test Case
A test case was performed against an actual U.S. company phone directory, with a medium-sized population that happened to be highly biased to Polish surnames. Approximately 120 names were “randomly” selected based on a known list of employees and the patterns for each were searched. In spite of the bias, the test case correlated well with the expected results.
The highest number of surnames (6) was returned by pattern 627 (3rd Rank), the second highest number of surnames (5) was returned by pattern 227 (1st Rank) and the fourth highest number of surnames (3) was returned by pattern 726 (5th Rank). These three data points average to estimate a total population of 300, which is close to the expected size of the company.
The U.S. Census includes racial data, which may be helpful in tailoring to certain populations, but surnames by state would be more helpful, which do not appear to be available. A geographic breakdown could improve results in the test case.
Notable Facts
· Three patterns do not appear in this data: 577, 957, 959.
· Sorted by rank, the last 10% of surnames require 53% of the effort.
· Surname data from the 2010 Census was not compiled and is not available.
· Unlike the U.S., Canada has a large population of 2-letter surnames[4].
· Canada’s government does not release surname data.
Get The Full List
Thanks to Nick Roberts of Foundstone for supplying a Canadian point of view on the subject.
References
* Two-letter surnames were excluded. This reduces the coverage of the analysis by 0.25% to 89.50% of the total population, a negligible change. Since entering these surnames would require the first letter of the given name, these should be analyzed separately for the distribution of given names, with some consideration to the biases of ethnicity. The U.S. Census does not consider surnames with one character valid.
† Some references in this document extrapolate the Census data to include 100% of the population for clarity. The spreadsheet[4] available lists percentages of both the sample data and the population as a whole for accuracy.
http://www.census.gov/genealogy/www/data/2000surnames/index.html
http://www.cbc.ca/news/background/name-change/common-surnames.html