Key Takeaways:
- The UK Government published their Energy Sector Cyber Security Strategy on 28 May 2026, setting out a four-year roadmap to 2030
- Jointly authored by DESNZ, Ofgem, NCSC and NESO, the strategy signals an unprecedented level of coordinated regulatory intent
- Clean Power 2030 ambitions are expanding the attack surface at pace, introducing new vulnerabilities alongside new technologies
- Regulatory scope is widening well beyond current NIS-regulated operators, with Cyber Essentials proposed as a baseline for all Ofgem licensees
- Supply chain security, OT resilience, and board-level accountability sit at the heart of the strategy’s expectations
- Organisations that move ahead of compliance deadlines will be better positioned for both security resilience and commercial credibility
A Strategy for a Critical Moment
Energy infrastructure has always been a target. What has changed is the scale, the sophistication, and the geopolitical intent behind those who are seeking to compromise it.
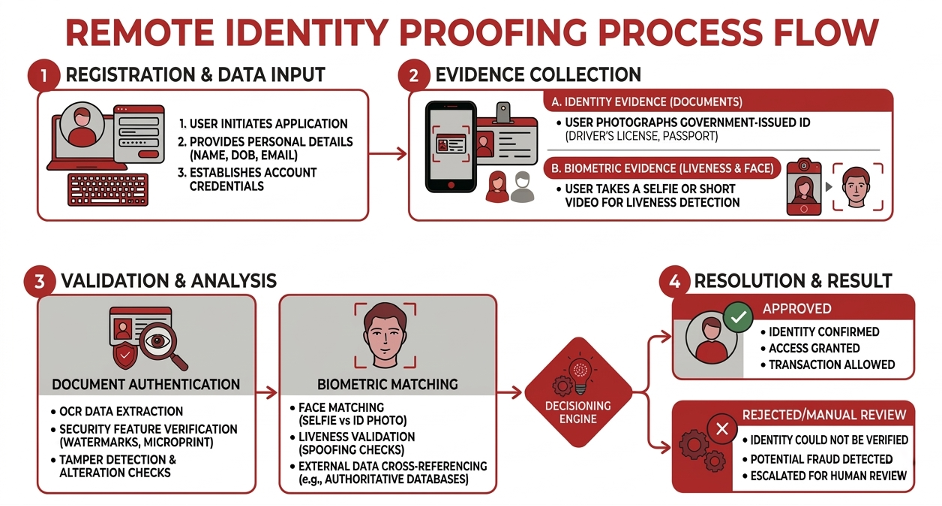
Published on 28 May 2026, the UK Government’s Energy Sector Cyber Security Strategy[1] arrives at a moment of acute tension. A national drive toward Clean Power 2030 is accelerating the transformation and digitalisation of the energy system faster than many organisations can embed the security controls needed to protect it. Adversaries have taken notice.
The NCSC has reported a stark increase in threats to Critical National Infrastructure. In January 2026, CERT Polska attributed a cyberattack on Polish renewable energy infrastructure directly to Russian actors, an incident that caused physical damage to industrial equipment alongside IT disruption.[4, 5] A month earlier, in December 2025, threat actors targeted distributed energy resources in a separate Polish incident designed to destabilise grid operations.[4] In 2024, the NCSC and international partners issued a joint advisory on China state-sponsored actors observed compromising US energy, transport, and water systems, assessed as pre-positioning for future disruptive or destructive attacks.[2, 3]
The message for UK energy sector leaders is unambiguous. This threat is real, escalating, and targeting precisely the kinds of assets the sector is now deploying at pace.
What Does the Energy Sector Cyber Security Strategy Set Out?
Developed jointly by the Department for Energy Security and Net Zero (DESNZ), Ofgem, the National Cyber Security Centre (NCSC), and the National Energy System Operator (NESO), (collectively referred to as the ‘Quad partners’) the strategy is built around five strategic outcomes to be delivered between now and 2030.[1]
- Understanding Threat, Vulnerability, and Risk. Building a whole-system picture of the energy sector, including supply chain interdependencies, critical failure points, and areas of risk concentration.
- Prevention Through Enhanced Resilience. Accelerating cyber maturity across operators, expanding regulatory scope beyond current NIS-regulated entities, and embedding security by design in new infrastructure.
- Preparedness, Response, and Recovery. Developing detection capabilities, testing cross-sector response plans, and building access to advanced adversary simulation schemes.
- Monitoring, Regulation, and Enforcement. Strengthening oversight through the forthcoming Cyber Security and Resilience Bill (CSRB), introduced to Parliament in November 2025,[6] and leveraging Ofgem licensing powers more actively.
- Fostering Partnership, Culture, and Skills. Addressing structural skills shortages, expanding security clearance access, and embedding a risk-driven security culture from the boardroom downward.
Two shifts stand out above others. The first is the explicit intention to expand regulatory reach, with the strategy proposing Cyber Essentials as a baseline requirement for all Ofgem licensees, not merely those currently in scope of the NIS regulations.[1, 7] The second sees supply chain security elevated from a good-practice consideration to a formal, time-bound regulatory objective, with critical supplier designation expected by 2030.
Who is Affected by the Energy Sector Cyber Security Strategy?
Energy Operators and Utilities
For NIS-regulated Operators of Essential Services, the clock is already running. Accelerated maturity targets for the most critical systems are due by 2027 for downstream gas and electricity, and 2028 for oil and upstream gas.[1] Critically, the Quad partners are explicit that operators should move ahead of ministerial deadlines wherever operationally feasible. Boards and executives are called out directly, with cyber risk expected to be governed with the same rigour as safety and physical resilience.
Smaller Operators and New Market Entrants
The strategy’s most commercially significant expansion is its reach toward organisations historically outside formal regulatory scope. Distributed energy resources, battery storage providers, demand flexibility aggregators, and new digital market participants all carry system-level risk. The proposal to extend Cyber Essentials requirements to all Ofgem licensees means no corner of the licensed energy market should expect to remain unaffected.[1]
Supply Chain Vendors and Technology Providers
Preliminary supply chain security principles are due by end 2026. A framework for designating and directly regulating critical suppliers follows by 2030.[1] Vendors and technology providers serving the energy sector need to begin assessing and evidencing their security posture now, well ahead of formal requirements.
What are the Key Challenges Organisations Will Face?
Translating the strategy’s objectives into operational reality will require organisations to navigate several persistent and interconnected challenges.
Legacy OT and ICS Infrastructure
Much of the sector’s OT predates modern cybersecurity practice. Integrating new digital systems with ageing industrial control environments creates complex interdependencies that are difficult to monitor, segment, or patch without operational risk.
The Cyber-Engineering Skills Gap
The UK faces a structural shortage of professionals combining deep cybersecurity knowledge with OT and engineering expertise.[1] Without sustained investment in building this dual capability, regulatory ambitions will outpace the delivery capacity available to meet them.
Supply Chain Visibility
Many operators have limited transparency into the security posture of their Tier 2 and Tier 3 suppliers. Without a comprehensive view of supply chain interdependencies, systemic risk cannot be managed, only tolerated.
Expanding Attack Surface from Clean Energy Technologies
Wind, solar, battery storage, and smart grid assets each introduce new attack vectors, many built and operated by new market entrants with limited security maturity. The pace of Clean Power 2030 deployment risks creating security debt at scale.
IOActive’s own research in this area is instructive. Our Principal Consultant Colin Cassidy, presenting at BSides OT UK in April 2026,[9] drew on direct wind farm security assessments to illustrate a recurring and concerning pattern. An over-reliance on security product solutions has left basic hygiene critically lacking, with systems discovered to have been installed insecurely from the outset and left unpatched for years. His research also challenges a common assumption in OT security circles, namely that cutting off power supply represents the ceiling of attacker ambition. In practice, the more technically sophisticated threat involves cyber-physical attacks capable of causing actual physical damage to turbine infrastructure. This is not a theoretical scenario. The 2019 GB power outage, in which wind farm behaviour during the incident complicated system restoration, demonstrated the real-world consequences of how micro-generation is modelled and controlled within energy management systems.[8]
Board-Level Cyber Literacy
The strategy repeatedly calls for board-level ownership of cyber risk.[1] Many boards still lack the literacy to interrogate it meaningfully, creating a governance gap between technical teams and strategic leadership at precisely the moment when that gap is most dangerous.
How IOActive Can Help?
IOActive’s work at the intersection of OT/ICS security, adversarial simulation, and critical infrastructure advisory positions us directly to support the energy sector in responding to this strategy. Testing is the thread that runs through everything we do, not compliance checkbox exercises, but technically credible, operationally grounded assessments designed to find what adversaries would find before they do.
OT/ICS Full Stack Security Assessments
Our specialist teams conduct rigorous assessments of OT environments, from generation and transmission through to distribution, renewables, and emerging clean energy assets. We examine the full stack, covering field devices, communication protocols, engineering workstations, historian systems, and the IT/OT interfaces where risk is often most concentrated. Our wind farm assessment experience, including the research presented by Colin Cassidy at BSides OT UK,[9] gives us direct, practitioner-level insight into the vulnerabilities specific to renewable energy infrastructure. Findings are delivered as risk-prioritised remediation roadmaps grounded in operational reality, not generic frameworks.
Red Team and Purple Team Services
The strategy’s call for advanced capability testing, aligned to schemes such as the NCSC’s Cyber Adversary Simulation (CyAS) scheme,[1] reflects a recognition that compliance assessments alone cannot validate resilience against determined, capable threat actors. IOActive’s Red Team operations emulate the specific tactics and techniques of the nation-state actors most likely to target UK energy infrastructure, including the IT-to-OT lateral movement paths and cyber-physical attack chains that standard penetration testing does not reach. Our Purple Team engagements bring offensive findings directly into structured collaboration with defensive teams, accelerating the translation of assessment outcomes into measurable improvements in detection and response capability.
Supply Chain Integrity
With supply chain security set to become a formally regulated requirement,[1] IOActive’s Supply Chain Integrity service helps both operators and their vendors identify and address risks before they become compliance findings or, more consequentially, incident vectors. We assess the security posture of technology providers, software vendors, and critical third parties, reviewing firmware, embedded systems, and procurement processes for vulnerabilities that organisations may be unknowingly inheriting. For operators preparing for the Quad partners’ forthcoming supply chain security principles, this work provides the evidential baseline that regulators will increasingly expect to see.
Threat Modelling and Advisory
Our threat modelling and risk assessment engagements provide the analytical foundation the strategy’s first objective demands. Working from a structured, evidence-based understanding of the threat landscape, we translate findings into prioritised investment decisions that boards and executive teams can act on with confidence. We work with CISOs, risk directors, and senior leadership to align security investment with the specific risk profile of their assets, sector role, and regulatory obligations.
Preparedness and Resilience Testing
Preparedness is a capability, and like any capability, it must be tested to be trusted. IOActive designs and facilitates structured tabletop exercises and crisis simulation scenarios that stress-test the cross-cutting response plans the strategy mandates,[1] without the risk of a live incident. We help organisations identify gaps in their detection, escalation, and recovery processes and develop the internal muscle memory needed when a real incident demands fast, coordinated action. This work directly supports the board-level governance expectations embedded throughout the strategy.
What are the Recommended Next Steps for Energy Sector Cyber Security Strategy Application?
The strategy is clear that urgency is required.[1] Waiting for regulatory deadlines is not a viable risk management posture. We recommend the following immediate actions.
- Assess current maturity against the NIS Cyber Assessment Framework[7] and identify gaps relative to the strategy’s resilience expectations.[1]
- Map your supply chain to understand critical dependencies and begin engaging key suppliers on their security posture.
- Prioritise OT visibility by deploying monitoring capabilities across industrial control environments before scope expansion regulations take effect.
- Engage your board with a structured cyber risk briefing that translates technical findings into business, reputational, and regulatory risk terms.
- Test your defences through a red team or adversary simulation engagement that probes your most critical operational systems against real-world threat actor TTPs.
- Evaluate Cyber Essentials readiness across your asset and licensee portfolio, ahead of proposed baseline requirements.[1]
Conclusion
The Energy Sector Cyber Security Strategy is the clearest signal the UK government has sent to the energy industry in years. It reflects both the escalating reality of the threat and the recognition that the clean energy transition cannot succeed if it creates vulnerabilities faster than the industry can address them.
The four-year roadmap to 2030 provides structure, but the expectation embedded throughout the strategy is that the strongest organisations will not wait for deadlines. They will assess their position now, invest in the capabilities that matter, and treat cyber resilience as the strategic enabler it has become.
The clean energy transition will only deliver on its promise if it is secured from the outset. The window to act ahead of the regulatory curve, and ahead of the next significant incident, remains open, but is narrowing.
If you would like to discuss how your organisation measures up against the strategy’s objectives, or how IOActive can support your cyber resilience programme, we welcome the conversation.
References
[1] Department for Energy Security and Net Zero, Ofgem, National Cyber Security Centre, National Energy System Operator. Energy Sector Cyber Security Strategy. 28 May 2026. https://www.gov.uk/government/publications/energy-sector-cyber-security-strategy/energy-sector-cyber-security-strategy
[2] National Cyber Security Centre. NCSC and Partners Issue Warning About State-Sponsored Cyber Attackers Hiding on Critical Infrastructure Networks. 7 February 2024. https://www.ncsc.gov.uk/news/ncsc-and-partners-issue-warning-about-state-sponsored-cyber-attackers-hiding-on-critical-infrastructure-networks
[3] CISA, NSA, FBI and international partners incl. NCSC. PRC State-Sponsored Actors Compromise and Maintain Persistent Access to U.S. Critical Infrastructure (Advisory AA24-038A). 7 February 2024. https://www.cisa.gov/news-events/cybersecurity-advisories/aa24-038a
[4] CERT Polska. Energy Sector Incident Report: Coordinated Cyberattacks on Polish Renewable Energy Infrastructure, 29 December 2025. Published 30 January 2026. Reported in: The Hacker News. https://thehackernews.com/2026/01/poland-attributes-december-cyber.html
[5] Notes from Poland. Poland Suffers Major Cyberattack on Power Grid, Says Russia Likely Responsible. 14 January 2026. https://notesfrompoland.com/2026/01/14/poland-suffers-major-cyberattack-on-power-grid-says-russia-likely-responsible/
[6] UK Parliament. Cyber Security and Resilience (Network and Information Systems) Bill 2024-26. Introduced to the House of Commons 12 November 2025. https://bills.parliament.uk/bills/4035
[7] UK Government. The Network and Information Systems (NIS) Regulations 2018 (SI 2018/506). Came into force 10 May 2018. https://www.legislation.gov.uk/uksi/2018/506/contents/made
[8] Ofgem. Investigation into 9 August 2019 Power Outage. Published 3 January 2020. https://www.ofgem.gov.uk/publications/investigation-9-august-2019-power-outage
[9] IOActive. BSides OT UK: Acme Windpharm – Colin Cassidy, Bristol, UK. 10 April 2026. https://www.ioactive.com/event/bsides-ot-uk-april-10-acme-windpharm-colin-cassidy-bristol-uk/