Missed Calls for SATCOM Cybersecurity: SATCOM Terminal Cyberattacks Open the War in Ukraine
By
John Sheehy
Unfortunately, IOActive was right. IOActive presciently foresaw the use of cyberattacks against commercial satellite communication (SATCOM) terminals and has worked tirelessly to warn the industry for the last nine years. There have been several credible reports of destructive exploitation of vulnerabilities in commercial SATCOM terminals during the opening hours of the War in Ukraine by Russian elements to prepare the battlefield.1,2,3
I’m disappointed that more industry members didn’t heed our warning, which provided ample time to act and mitigate the realization of these threats.
BACKGROUND
IOActive has sponsored several original cybersecurity research projects on commercial SATCOM over the last decade, and with the exception of our most recent work related to Wideye™ SATCOM terminals,4 all of the research has been done by Ruben Santamarta.
IOActive has distinguished itself with a commanding body of work related to SATCOM. Our first SATCOM cybersecurity project was completed in 2013, and after several months of coordinated disclosure with the affected vendors, we presented5 our findings in 2014 at Black Hat in a talk entitled “SATCOM Terminals Hacking by Air, Sea, and Land.”6 In conjunction with this presentation, we published a comprehensive whitepaper entitled “A Wake-up Call for SATCOM Security”7 exploring the vulnerabilities and issues in greater detail. As a testament to the ground-breaking nature of this work, Google Scholar shows this paper has been cited 37 times as of March 2022.8
For this research project we reviewed SATCOM terminals from five major vendors used on the INMARSAT9 and Iridium10 services and found that malicious actors could abuse all of the devices. The vulnerabilities included what would appear to be backdoors, hardcoded credentials, undocumented and/or insecure protocols, and weak encryption algorithms. In addition to design flaws, IOActive also uncovered a number of features in the devices that clearly pose security risks. We concluded that this research “should serve as an initial wake-up call for both the vendors and users of the current generation of SATCOM technology.” We did have one major user of these services engage with us to understand the risk it posed to their global operations. We wish we were able to help more organizations during this time period.
As the consequences of our findings were largely ignored within the industry and amongst those who rely upon such commercial SATCOM services, IOActive sponsored a follow-up research project called “Last Call for SATCOM Security,”11 which we presented12 at Black Hat in 2018.13 We discovered vulnerabilities that affect the aviation, maritime, and military industries including backdoors, insecure protocols, and network misconfigurations. We identified hundreds of vulnerable systems on aircraft, maritime vessels, and units used by the military in active conflict zones disclosing detailed geolocation data. The paper and talk’s title clearly challenged the industry to do something about these pervasive cybersecurity issues before it was too late.
Stakeholders were more open to the second body of research, even though some sectors pushed back on the conclusions despite the irrefutable, concrete code examples IOActive provided. Some small groups listened very thoughtfully and carefully before they began to take action to manage the risks they and their users faced. Unfortunately, this type of proactive approach was not a common response to our research.
In January 2022, a little more than three years after the publication of our second body of research, the U.S. National Security Agency (NSA) issued a rare public Cybersecurity Advisory14 urging operators to protect commercial Very Small Aperture Terminals (VSATs), since they are “increasingly used for remote communications in support of U.S. government missions.” In the Works Cited section of the advisory, the only vulnerability research cited was IOActive’s “Last Call for SATCOM Security” presentation. It is difficult to receive a higher accolade in the world of SATCOM for your cybersecurity research. Congratulations to the NSA for pushing this advisory out prior to the exploitation of SATCOM terminals in Ukraine.
Most recently, on 17 March 2022, the U.S. Federal Bureau of Investigation (FBI) and Cybersecurity and Infrastructure Security Agency (CISA) issued a joint advisory related to SATCOM security titled “Strengthening Cybersecurity of SATCOM Network Providers and Customers.”15 This document provides guidance on how to improve the security posture of SATCOM systems. We urge everyone to take this guidance very seriously.
RECENT SATCOM TERMINAL ATTACKS IN EUROPE
The Reuters piece does a good job of covering what’s publicly known about the attacks.16 Ruben has posted a great technical blog17 analyzing the likely technical attack vectors based upon currently available open-source information.
Unfortunately, our second piece of research was more controversial, since it challenged the widespread, sacrosanct belief held by most members of the aviation industry that they have identified and appropriately mitigated all risks to safety. Unquestionably, they have done an exceptional job for passive and natural threats; however, within aviation and aerospace industries, there is significantly more work to be done to properly manage active threats to safety from highly motivated, competent, and sophisticated threat actors such as the one who bricked thousands of SATCOM terminals on 24 February 2022.
Hypotheses on Threat Actor Identity
While there is no clear public evidence as to the identity of the threat actor responsible for the SATCOM terminal attack, informed analysis of open sources can provide a working hypothesis for potential threat actors. To strongly confirm the hypothesis, one would need to gather secret intelligence via human intelligence (HUMINT) sources such as a penetration or through active or passive signals intelligence (SIGINT). Forensic analysis of the malware used in the attack could yield technical evidence to tie the cyberattack to the responsible group through their operational infrastructure. Alternately, some years in the future, we may see the unit and even team members publicly recognized for their contribution to the ground-breaking cyberattack that opened the War in Ukraine. It was a bright spot in a campaign that has otherwise highlighted the inadequacies of the Russian armed forces.18
Prima facie, one would expect an element of Russian military intelligence to support the Russian armed forces through cyber operations. This is a very logical, reasonable starting position. This is the current theory floated by a source in the U.S. intelligence community to the Washington Post.19 However, there is no desire to make a high-confidence, public attribution at this time. Looking for additional evidence as to whether they have the capability and capacity to do this in the absence of specific evidence from the attack helps support this hypothesis. GRU cyber elements have a history of successful attacks on critical infrastructure in Ukraine, which demonstrates they have the capability and capacity to successfully target operational technology with consequential effects.20
An alternate Russian-government-affiliated advanced persistent threat (APT) group, Turla21 (affiliated with the FSB22), is another potential candidate. They have been linked to prior, sophisticated use of SATCOM in espionage activities.23,24 In addition, they have a track record of innovation, including adapting new TTPs, like living off the land, to improve their evasion capabilities and protect their operational security.25 In addition, their targets generally align with Russian strategic interests, and supporting the creation of a neutral buffer space in Ukraine between their border and NATO member states is among the most important interests of the Russian nation.
Finally, there’s a third hypothesis involving some sort of collaboration between different Russian special services. While there have been indications of toolchain sharing or joint operations between cyber elements of Russian special services in the SolarWinds incident,26 it is not clear from public information whether this was due to a formal joint operation or an admixture of personnel over time.
Interested parties should look for further confirmatory and contradictory evidence to prove or disprove these hypotheses.
Future Cyberattacks on SATCOM
Regrettably, we are in a new era with a significantly increased probability of additional SATCOM cyberattacks. Fortunately, we may not see another destructive cyberattack like we saw last month in Ukraine for some time, but clandestine exploitation in support of intelligence and espionage operations is more likely. Unfortunately, this very public example of a successful cyberattack on SATCOM will increase interest amongst those threat actors with the capability and capacity to develop weaponized SATCOM exploits and lower the inhibition for the use of those exploits amongst those threat actors who have them in inventory.
ACT NOW
While disappointing that it took real-world attacks for a wake-up call to be realized, it’s not too late for all members of the industry to take these threats to heart and finally address the underlying issues. We emphasize that if an organization offering or using SATCOM services hasn’t acted on these risks yet, they must do so quickly. We’ll share some general thoughts about on how to start.
SATCOM Providers
SATCOM providers can do the most to manage cybersecurity risk. The following is some general guidance:
Avoid groupthink and the problems of checking one’s own work. Engage a competent third party to perform independent validation and verification of your cybersecurity posture.
Ensure you are getting regular assessments of your cybersecurity posture, including:
Daily or weekly vulnerability scans
Quarterly penetration testing
Regular full-spectrum, Red Team engagements
Support your Security Operations Center (SOC) team members with additional training, including Purple Team engagements.
Ensure any devices used on your network or service have been tested by a competent third-party assessor with deep experience in embedded device security.
If you manufacture devices, ensure your developers have cybersecurity training to include threat modeling, secure coding, and embedded device security.
Develop an operational resiliency plan to respond to cyberattacks and minimize the impacts of such incidents.
Retain an incident response firm in preparation for any compromise.
SATCOM Users
Here’s a short action list for users:
Understand the details of the SATCOM services your organization uses.
Understand the business criticality and impact if these services are affected.
Ask your provider(s) to supply proof they are taking prudent steps to protect their service and their clients. (Service and terminal providers will likely be different entities.)
Ask for summary reports of their third-party network penetration testing.
Ask for summary reports of their third-party terminal device penetration testing.
Evaluate switching to a SATCOM provider who is able to demonstrate they are prudently addressing these concerns.
Develop plans for containment and operational resiliency should you experience an attack.
Retain an incident response firm in preparation for any compromise.
Finally, if you’re an organization offering or using SATCOM services, we are happy to have a confidential chat with you to help you develop a customized course of action appropriate to your specific circumstances.
THANKS
I would like to extend a thank you to those who took these issues seriously over the last nine years. I know some were unable to convince their senior leadership to act, but it was most certainly not due to a lack of effort.
Batteries Not Included: Reverse Engineering Obscure Architectures
By
Ethan Shackelford
Introduction
I recently encountered a device whose software I wanted to reverse engineer. After initial investigation, the device was determined to be using a processor based on Analog Devices’ Blackfin architecture. I had never heard of or worked with this architecture, nor with the executable format used by the system, and little to no support for it was present in existing reverse engineering tooling. This article will cover the two-week journey I took going from zero knowledge to full decompilation and advanced analysis, using Binary Ninja. The code discussed in this article can be found on my GitHub.
Special thanks to everyone on the Binary Ninja Slack. The Binary Ninja community is excellent and the generous help I received there was invaluable.
Overview
While the x86 architecture (and increasingly, ARM) may dominate the home PC and server market, there is in fact a huge variety of instruction set architectures (ISAs) available on the market today. Some other common general-purpose architectures include MIPS (often found in routers) and the Xtensa architecture, used by many WiFi-capable IoT devices. Furthermore many specialized architectures exist, such as PIC (commonly found in ICS equipment) and various Digital Signal Processing (DSP) focused architectures, including the Blackfin architecture from Analog Devices, which is the focus of this article.
This article, will explore various techniques and methodologies for understanding new, often more obscure architectures and the surrounding infrastructure which may be poorly documented and for which little to no tooling exists. This will include:
Identifying an unknown architecture for a given device
Taking the first steps from zero knowledge/tooling to some knowledge/tooling,
Refining that understanding and translating it to sophisticated tooling
An exploration of higher-level unknown constructs, including ABI and executable file formats (to be covered in Part 2)
The architecture in question will be Analog Devices’ Blackfin, but the methodologies outlined here should apply to any unknown or exotic architecture you run across.
Identifying Architecture
When attempting to understand an unknown device, say a router you bought from eBay, or a guitar pedal, or any number of other gadgets, a very useful first step is visual inspection. There is quite a lot to PCB analysis and component identification, but that is outside of the scope of this article. What we are interested in here is the main processor, which should be fairly easy to spot — It will likely be the largest component, be roughly square shaped, and have many of the traces on the PCB running to/from it. Some examples:
More specifically, we’re interested in the markings on the chip. Generally, these will include a brand insignia and model/part number, which can be used together to identify the chip.
Much like Rumpelstiltskin, knowing the name of a processor grants you great power over it. Unlike Rumpelstiltskin, rather than magic, the source behind the power of the name of a processor is the ability to locate it’s associated datasheets and reference manuals. Actually deriving a full processor name from chip markings can sometimes take some search-engine-fu, and further query gymnastics are often required to find the specific documentation you want, but generally it will be available. Reverse engineering completely undocumented custom processors is possible, but won’t be covered in this article.
Pictured below are the chip markings for our target device, with the contrast cranked up for visibility.
We see the following in this image:
Analog Devices logo, as well as a full company name
A likely part number, “ADSP-BF547M”
Several more lines of unknown meaning
A logo containing the word “Blackfin”
From this, we can surmise that this chip is produced by Analog Devices, has part number ADSP-BF547M, and is associated with something called Blackfin. With this part number, it is fairly easy to acquire a reference manual for this family of processors: the Analog Devices ADSP-BF54x. With access to the reference manual, we now have everything we need to understand this architecture, albeit in raw form. We can see from the manual that the Blackfin marking on the chip is in fact referring to a processor family, which all share an ISA, which itself is known also known as Blackfin. The the Blackfin Processor Programming Reference includes the instruction set, with a description of each operation the processor is capable of, and the associated machine code.
So that’s it, just dump the firmware of the device and hand-translate the machine code into assembly by referencing instructions in the manual one by one. Easy!
Just Kidding
Of course, translating machine code by hand is not a tenable strategy for making sense of a piece of software in any reasonable amount of time. In many cases, there are existing tools and software which can allow for the automation of this process, broadly referred to as “disassembly.” This is part of the function served by tools such as IDA and Binary Ninja, as well as the primary purpose of less complex utilities, such as the Unix command line tools “objdump.” However, as every ISA will encode machine instructions differently (by definition), someone, at some point, must do the initial work of automating translation between machine code and assembly the hard way for each ISA.
For popular architectures such as x86 and ARM, this work has already been done for us. These architectures are well supported by tools such as IDA and Binary Ninja by default, as well as the common executable file formats for these architectures, for example the Executable and Linkable Format (ELF) on linux and Portable Executable (PE) on Windows. In many cases, these architectures and formats will be plug-and-play, and you can begin reverse engineering your subject executable or firmware without any additional preperation or understanding of the underlying mechanisms.
But what do you do if your architecture and/or file format isn’t common, and is not supported out of the box by existing tools? This was a question I had to answer when working with the Blackfin processor referenced earlier. Not only was the architecture unfamiliar and uncommon, but the file format used by the operating system running on the processor was a fairly obscure one, binary FLAT (bFLT), sometimes used for embedded Linux systems without a Memory Management Unit (MMU). Additionally, as it turned out and will be discussed later, the version of bFLT used on Blackfin-based devices didn’t even conform to what little information is available on the format.
Working Smarter
The best option, when presented with an architecture not officially supported by existing tooling, is to use unofficial support. In some cases, some other poor soul may have been faced with the same challenge we are, and has done the work for us in the form a of a plugin. All major reverse engineering tools support some kind of plugin system, with which users of said software can develop and optionally share extra tooling or support for these tools, including support for additional architectures. In the case of Binary Ninja, the primary focus for this article, “Architecture” plugins provide this kind of functionality. However there is no guarantee that a plugin targeting your particular architecture will either exist, or work the way you expect. Such is open source development.
If such a convenient solution does not exist, the next step short of manually working from the reference manual requires getting our hands dirty and cannibalizing existing code. Enter the venerable libopcodes. This library, dating back at least to 1993, is the backbone that allows utilities such as objdump to function as they do. It boasts an impressive variety of supported architectures, including our target Blackfin. It is also almost entirely undocumented, and its design poses a number of issues for more extensive binary analysis, which will be covered later.
Using libopcodes directly from a custom disassembler written in C, we can begin to get some meaningful disassembly out of our example executable.
However, an issue should be immediately apparent: the output of this custom tool is simply text, and immutable text at that. No semantic analysis has or can take place, because of the way libopcodes was designed: it takes machine code supplied by the user, passes it through a black box, and returns a string which represents the assembly code that would have been written to produce the input. There is no structural information, no delineation of functions, no control flow information, nothing that could aid in analysis of binaries more complex than a simple “hello world.” This introduces an important distinction in disassembler design: the difference between disassembly and decomposition of machine code.
Disassembly
The custom software written above using libocpdes, and objdump, are disassemblers. They take an input, and return assembly code. There is no requirement for any additional information about a given instruction; to be a disassembler, a piece of software must only produce the correct assembly text for a given machine instruction input.
Decomposition
In order to produce correct assembly code output, a disassembler must first parse a given machine instruction for meaning. That is, an input sequence of ones and zeros must be broken up into its constituent parts, and the meaning of those parts must be codified by some structure which the disassembler can then translate into a series of strings representing the final assembly code. This process is known as decomposition, and for those familiar with compiler design, is something like tokenization in the other direction. For deeper analysis of a given set of machine instructions (for example a full executable containing functions) decomposition is much more powerful than simple disassembly.
Consider the following machine instruction for the Blackfin ISA:
Searching the reference manual for instructions which match this pattern, we find the JUMP.L instruction, which includes all 32 bit values from 0xE2000000 to 0xE2FFFFFF. We also see in this entry what each bit represents:
We see that the first 8 bits are constant – this is the opcode, a unique prefix which the processor interprets first to determine what to do with the rest of the bits in the instruction. Each instruction will have a unique opcode.
The next 8 bits are marked as the “most significant bits of” something identified as “pcrel25m2,” with the final 16 bits being “least significant bits of pcrel25m2 divided by 2.” The reference manual includes an explanation of this term, which is essentially an encoding of an immediate value.
Based on this, the machine instruction above can be broken up into two tokens: the opcode, and the immediate value. The immediate value, after decoding the above instruction’s bits [23:0] as described by the manual, is 0x2000 (0 + (0x1000 * 2)). But how can the opcode be represented? It varies by architecture, but in many cases an opcode can be translated to an associated assembly mnemonic, which is the case here. The E2 opcode corresponds to the JUMP.L mnemonic, as described by the manual.
So then our instruction, 0xE2001000 translates into the following set of tokens:
For a simple text disassembler, the processing of the instruction stops here, the assembly code JUMP.L 0x2000 can be output based on the tokenized instruction, and the disassembler can move on to the next instruction. However, for more useful analysis of the machine code, additional information can be added to our Instruction structure.
The JUMP.L instruction is fairly simple; the reference manual tells us that it is an unconditional jump to a PC-relative address. Thus, we can add a member to our Instruction structure indicating this: an “Operation” field. You can think of this like instruction metadata; information not explicitly written in the associated assembly, but implied by the mnemonic or other constituent parts. In this case, we can call the operation OP_JMP.
By assigning each instruction an Operation, we can craft a token parser which does more than simply display text. Because we are now encoding meaning in our Instruction structure, we can interpret each component token based on its associated meaning for that instruction specifically. Taking JUMP.L as an example, it is now possible to perform basic control flow analysis: when the analysis tool we are building sees a JUMP.L 0x2000, it can now determine that execution will continue at address PC + 0x2000, and continue analysis there.
Our Instruction structure can be refined further, encoding additional information specific to it’s instruction class. For example, in addition to the unconditional PC-relative jump (JUMP.L), Blackfin also offers conditional relative jumps, and both absolute and relative jumps to values stored in registers.
For conditionality and whether a jump is absolute or relative, we can add two more fields to our structure: a Condition field and a Relative field, as follows.
Conditional jumps appear more complex represented in assembly, but can still be represented with the same structure. CC is a general purpose condition flag for the Blackfin architecture, and is used in conditional jumps. The standard pattern for conditional jumps in Blackfin code looks like this:
We do not need tokens for the IF and CC strings, because they are encoded in the Condition field.
All instructions can be broken down this way. Our decomposer takes machine code as input, and parses each instruction according to the logic associated with its opcode, producing a structure with the appropriate Operation, tokens and any necessary metadata such as condition, relativity, or other special flags.
Our initial categorization of instruction based on opcode looks like this:
And a simple example of decomposing the machine instruction (for the unconditional relative jump):
For more complex instructions, the decomposition code can be much more involved, but will always produce an Instruction structure conforming to our definition above. For example, the PushPopMultiple instruction [--SP] = (R7:5, P5:1) uses a rather complicated encoding, and more processing is required, but still can be represented by the Instruction structure.
The process of implementing decomposition logic can be somewhat tedious, given the number of instructions in the average ISA. Implementing the entirety of the Blackfin ISA took about a week and a half of effort, referencing both the Blackfin reference manual and the existing libopcodes implementation. The libopcodes opcode parsing logic was lifted nearly verbatim, but the actual decomposition of each instruction had to be implemented from scratch due to the text-only nature of the libopcodes design.
Analysis
Now we have our decomposer, which takes in machine instructions and outputs Instruction objects containing tokens and metadata for the input. I’ve said before “this information is useful for analysis,” but what does this actually mean? One approach would be to write an analysis engine from scratch, but thankfully a powerful system already exists for this purpose: Binary Ninja and its plugin system. We’ll be exploring increasingly more sophisticated analysis techniques using Binary Ninja, starting with recreating the basic disassembler we saw before (with the added perks of the Binary Ninja UI) and ending up with full pseudo-C decompiled code.
We’ll be creating a Binary Ninja Architecture Plugin to accomplish our goal here. The precise details for doing so are outside the scope of this article, but additional information can be found in this excellent blog post from Vector35.
Basic Disassembly
First, we’ll recreate the text-only disassembler from earlier in the article, this time as a Binary Ninja plugin. This can be accomplished by defining a function called GetInstructionText in our plugin, which is responsible for translating raw machine code bytes to a series of tokens for Binary Ninja to display. Using our jump Instruction structure again, the process can be represented in pseudocode as follows:
for token in Instruction.TokenList {
switch (token.class) {
case mnemonic:
BinaryNinjaOutput.push(InstructionTextToken, token.value);
case immediate:
BinaryNinjaOutput.push(IntegerToken, token.value);
etc...
}
}
This step completely ignores the operation and metadata we assigned each object earlier; only the tokens are processed to produce the corresponding instruction text, in other words, the assembly. After implementing this, as well as the necessary Binary Ninja plugin boilerplate, the following output is produced:
Control Flow Analysis
This looks a bit nicer than the text disassembler, but is essentially serving the same function. The code is interpreted as one giant, several hundred kilobyte function with no control flow information to delineate functions, branches, loops, and various other standard software constructs. We need to explicitly tell Binary Ninja this information, but thankfully we designed our decomposer in such a way that it already supplies this information inside the Instruction structure. We can single out any Operation which affects control flow (such as jumps, calls, and returns) and hint to Binary Ninja about how control flow will be affected based on the constituent tokens of those instructions. This process is implemented in the GetInstructionInfo function, and is as follows:
With this implemented, the output is substantially improved:
We now have individual functions, and control flow is tracked within and between them. We can follow branches and loops, see where functions are called and where they call to, and are much better equipped to actually begin to make sense of the software we are attempting to analyze.
Now, we could stop here. This level of analysis combined with Binary Ninja’s built-in interactivity is more than enough to make reasonable progress with your executable (assuming you know the assembly language of your target executable, which you certainly will after writing a disassembler for it). However, the next step we’ll take is where Binary Ninja and its architecture plugins really shine.
Lifting and Intermediate Languages
At the time of its invention the concept of the assembler, which generates machine code based on human-readable symbolic text, was a huge improvement over manual entry of machine code by a programmer. It was made intuitive through the use of certain abstractions over manually selecting opcodes and allowed a programmer to use mnemonics and other constructs to more clearly dictate what the computer program should do. You could say that assembly is a higher level language than machine code, in that it abstracts away the more direct interactions with computer hardware in favor of ease of programming and program understanding.
So how might we improve the output of our plugin further? While certainly preferable to reading raw machine code, assembly language isn’t the easiest to follow way of representing code. The same kinds of abstractions that improved upon machine code can be applied again to assembly to produce a language at an even higher level, such as Fortran, C, and many others. It would be beneficial for our reverse engineering efforts to be able to read our code in a form similar to those languages.
One way to accomplish this is to design a piece of software which translates assembly to the equivalent C-like code from scratch. This would require a full reimplementation for every new architecture and is the approach taken by the Hexrays decompilers associated with IDA — the decompiler for each architecture is purchased and installed separately, and any architecture not explicitly implemented is entirely unsupported.
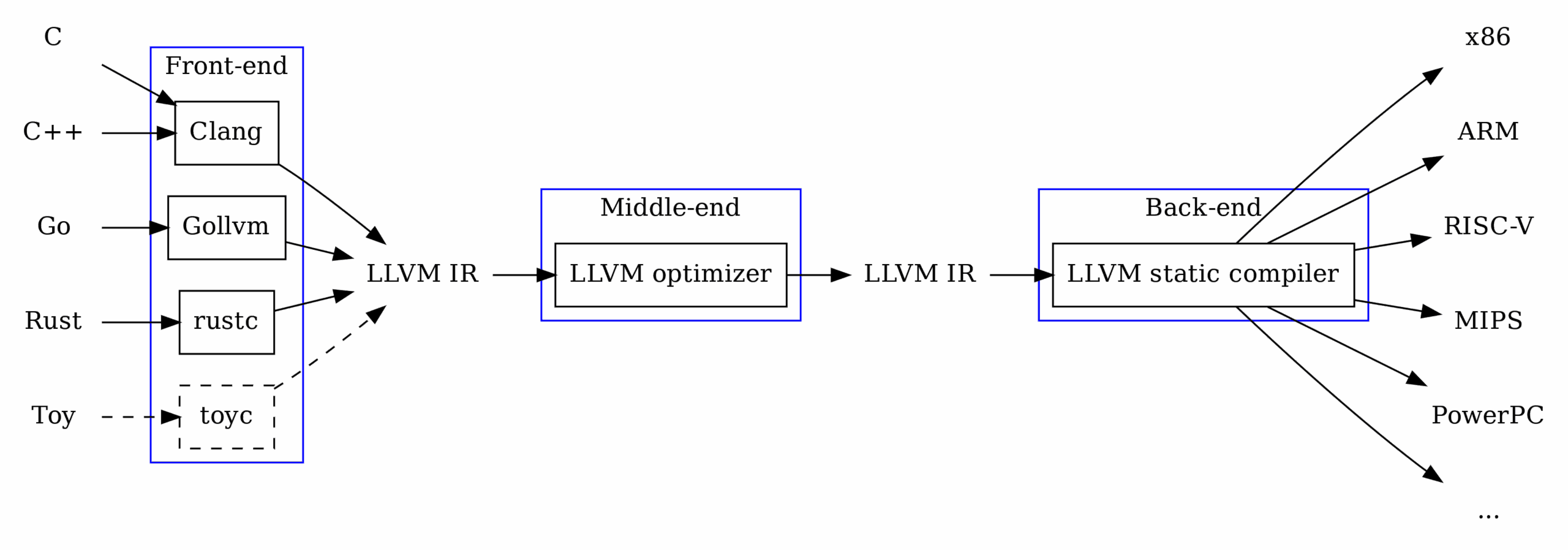
Another approach is available, and it once again takes its cue from compiler design (which I will be oversimplifying here). The LLVM compiler architecture uses something called an Intermediate Representation (IR) as part of the compilation process: essentially, it is the job of the compiler frontend (clang for example) to translate the incoming C, C++, or Objective-C code into LLVM IR. The compiler backend (LLVM) then translates this IR into machine code for the target architecture. Credit to Robin Eklind for the following image from this blog covering LLVM IR:
An important feature of this compiler architecture is its ability to unify many input languages into a single representational form (LLVM IR). This allows for modularity: an entire compiler need not be created for a new language and architecture pair, and instead only a frontend which translates that new language into LLVM IR must be implemented for full compilation capabilities for all architectures already supported by the LLVM backend.
You may already see how this could be turned around to become useful processing machine code in the other direction. If some system can be designed which allows for the unification of a variety of input architectures into a single IR, the heavy lifting for translating that representation into something more conducive to reverse engineering can be left to that system, and only the “front-end” must be implemented.
Allow me to introduce Binary Ninja’s incredibly powerful Binary Ninja Intermediate Languages, or BNIL. From the Binary Ninja documentation on BNIL:
The Binary Ninja Intermediate Language (BNIL) is a semantic representation of the assembly language instructions for a native architecture in Binary Ninja. BNIL is actually a family of intermediate languages that work together to provide functionality at different abstraction layers. BNIL is a tree-based, architecture-independent intermediate representation of machine code used throughout Binary Ninja. During each analysis step a number of optimizations and analysis passes occur, resulting in a higher and higher level of abstraction the further through the analysis binaries are processed.
Essentially, BNIL is something akin to LLVM IR. The following flow chart is a rough representation of how BNIL is used within Binary Ninja:
The portion of an Architecture plugin that produces the Lifted IL as described by that chart is known as the lifter. The lifter takes in the Instruction objects we defined and generated earlier as input, and based on the operation, metadata, and tokens of each instruction describes what operations are actually being performed by a given instruction to Binary Ninja. For example, let’s examine the process of lifting the add instruction for the ARMv7 architecture.
Based on the assembly itself, the ARM reference manual, and our generated Instruction object, we understand that the operation taking place when this instruction is executed is:
Add 1 to the value in register r1
Store the resulting value in register r0
Now we need some way of indicating this to Binary Ninja. Binary Ninja’s API offers a robust collection of functions and types which allow for the generation of lifted IL, which we can use to this end.
Relevant lifter pseudo-code (with simplified API calls):
The resulting API call reads “set the register dst_reg to the expression ‘register src_reg plus the constant value src2‘”, which matches the description in plain english above.
If after completing the disassembly portion of your architecture plugin you found yourself missing the abject tedium of writing an unending string of instruction decomposition implementations, fear not! The next step in creating our complete architecture plugin is implementing lifting logic for each distinct Operation that our decomposer is capable of assigning to an instruction. This is not quite as strenuous as the decomposition implementation, since many instructions are likely to have been condensed into a single Operation (for example, Blackfin features 10 or so instructions for moving values into registers; these are all assigned the OP_MV Operation, and a single block of lifter logic covers all of them).
Once the lifter has been implemented, the full power of Binary Ninja is available to us. In the Binary Ninja UI, we can see the lifted IL (on the right) our plugin now generates alongside the disassembly (on the left):
You’re forgiven for thinking that it is a bit underwhelming for all the work we’ve put in to get here. However, take another look at the Binary Ninja analysis flow chart above. Now that our plugin is generating lifted IL, Binary NInja can analyze it to produce the higher-level IL representations. For reference, we’ll be looking at the analysis of a Blackfin executable compiled from the following code:
int
add4(int x, int y, int z, int j)
{
return x + y + z + j;
}
int
main()
{
int x, y, z, j;
x = 1;
y = 2;
z = 3;
j = 0x12345678;
return add4(x, y, z, j);
}
Finally, let’s take a look at the high-level IL output in the Binary Ninja UI (right), alongside the disassembly:
As you might guess, reverse engineering the code on the right can be done in a fraction of the time it would take to reverse engineer pure assembly code. This is especially true for an obscure architecture that might require frequent trips to the manual (what does the link instruction do again? Does call push the return address on the stack or into a register?). Furthermore this isn’t taking into account all of the extremely useful features available within Binary Ninja once the full analysis engine is running, which increase efficiency substantially.
So, there you have it. From zero knowledge of a given architecture to easily analyzable pseudo-C in about two weeks, using just some elbow grease and Binary Ninja’s excellent BNIL.
…
Keen readers may have noticed I carefully avoided discussing a few important details — while we do now have the capabilities to produce pseudo-C from raw machine code for the Blackfin architecture, we can’t just toss an arbitrary executable in and expect complete analysis. A few questions that still need to be answered:
What is the function calling convention for this platform?
Are there syscalls for this platform? How are they handled?
What is the executable file format? How are the segments loaded into memory? Are they compressed?
Where does execution start?
Is dynamic linking taking place? If so, how should linkage be resolved?
Are there relocations? How are they handled?
Since this article is already a mile long, I’ll save exploration and eventual answering of these questions for an upcoming Part 2. As a preview though, here’s some fun information: Exactly none of those questions have officially documented answers, and the unofficial documentation for the various pieces involved, if it existed in the first place, was often outright incorrect. Don’t put away that elbow grease just yet!
References
arch-blackfin – The architecture plugin built and discussed in this article, including standalone decomposer/disassembler.
Responding to a Changing Threatscape: Sharing More
By
John Sheehy
The War in Ukraine has caused a sea change in the threatscape, where a highly capable group of threat actors now has a much stronger incentive to use cyber actions to achieve their objectives and support their interests. At IOActive we are adjusting our course of action in response to this change in several areas: in addition to our groundbreaking cybersecurity research, another element to arrive in the upcoming months will see us sharing more and different types of content on our blogs.
Some of this new content will be items we normally share discreetly with our clients in small, verbal briefings or through Information Sharing and Analysis Centers (ISACs). However, we have decided to judiciously publicize more of this information due to the more intense risks the community is facing today.
Original Cybersecurity Research
In accordance with our Responsible Disclosure Policy1, we’ll be sharing previously unpublished, original cybersecurity research to which product manufacturers were non-responsive after our disclosure steps or where we’re seeing similar vulnerabilities exploited in the wild. For example, due to the exploitation of vulnerabilities in commercial satellite communications (SATCOM) terminals2 as presciently foreseen by Ruben Santamarta in two research projects from 20143 and 20184, as well as by the US National Security Agency (NSA) in a January 2022 Cybersecurity Advisory5, we’ll be sharing vulnerabilities in a two-phase approach that we originally reported to a terminal manufacturer more than 3 years ago. You can find that initial post here.6
Analytical Threat Intelligence
IOActive normally chooses not to publicly share the products of our threat intelligence analytics, wherein we explore the operational and cybersecurity consequences of our original research findings or assess which threat actors may have the capability and interest to perform or operationalize attacks similar to those found in our research. Given the changed threatscape, however, we feel it’s important to share a retrospective look at the revealed SATCOM vulnerabilities and their utilization in the War in Ukraine; likewise, we will be sharing more analytical perspectives on cybersecurity threats to transportation, as briefly covered in a recent FleetOwner article specific to trucking fleet operations.7 While these analytical products are often informal, they can be extremely valuable to organizations of all types.
Strategies and Potential Courses of Action
In addition to providing threat intelligence products from an attacker’s viewpoint, we also advise our clients and share with ISACs strategies to manage their cybersecurity and operational risks, as well as potential courses of action based on our detailed understanding of how attackers operate and succeed. Often these suggestions and advice are made in response to our original cybersecurity research and its corresponding analytical threat.
Wideye Security Advisory and Current Concerns on SATCOM Security
By
Ethan Shackelford
In accordance with our Responsible Disclosure Policy1, we are sharing this previously unpublished, original cybersecurity research, since the manufacturer of the affected products in the Wideye brand, Addvalue Technologies Ltd., has been non-responsive for more than 3-years after our initial disclosure and we have seen similar vulnerabilities exploited in the wild during the War in Ukraine.2 IOActive disclosed the results of the research back in 2019 and successfully connected with AddValue Technologies Ltd, the vulnerable vendor. Unfortunately, we have not received any feedback from the manufacturer after providing the coordinated, responsible disclosure of the report in 2019.
Depending on where in the world you live or work, you may be familiar with satellite internet. A variety of equipment and services exist in this field, ranging from large-scale static installations to smaller, portable equipment for use in the field or where larger installations are not possible. Satellite internet systems also make connectivity and communication possible under circumstances where traditional communication infrastructure is unavailable due to natural disaster, isolation, or deliberate disruption. In such situations, maintaining availability and ensuring these systems are well secured is of vital importance.
IOActive and others have done work on commercial satellite communication (SATCOM) terminals. Unfortunately, we have yet to see a significant improvement in this industry’s security posture. Back in 2014,3 Ruben Santamarta presented the findings documented in a whitepaper titled “A Wake-Up call for SATCOM Security.” In 20184 he presented another whitepaper, “Last Call for SATCOM Security,” where he shared a plethora of vulnerabilities and real-world attack scenarios against multiple SATCOM terminals across different sectors. These dense, extensively referenced whitepapers, include an introduction to SATCOM architecture and threat scenarios, as well as definitions of some key technical terms.
The iSavi5 and SABRE Ranger 50006 Satellite Terminals, produced by Wideye7, were included in IOActive’s SATCOM research. iSavi is an affordable, personal satellite terminal developed for Inmarsat’s8 IsatHub service. It is lightweight, highly portable, and quick and easy to set up with no technical expertise or training needed. iSavi is intended as a personal device and may not have a publicly accessible IP address. The SABRE Ranger 5000 is a compact machine-to-machine (M2M) satellite terminal. It is intended to be connected 24/7, provides remote access to equipment, and is used in SCADA applications.
IOActive conducted a black-box security assessment of these two devices in order to identify their attack surfaces and determine their overall security posture. This included dynamic penetration testing using both industry-standard techniques as well as tools and techniques developed by IOActive. Dynamic testing included network and physical interfaces. Additionally, we performed static analysis of device firmware, consisting of binary reverse engineering and review.
IOActive identified numerous security issues, spanning multiple domains and vulnerability classes. Several the identified vulnerabilities have the potential to lead to full or partial device and communication compromise, as well as leak information about components of the system, including GPS location coordinates, to unauthorized parties. The issues can be grouped in the following broad categories:
Authentication and Credential Management
Data Parsing
Networking
Firmware Security
Information Disclosure
IOActive found the overall security posture of the Wideye iSavi and Ranger systems to be poor. In some areas, attempts were made to secure the devices, but these attempts proved inadequate. In other areas, no attempts were made at all, even in areas where specific threats are well established in the realm of device security.
IOActive provided coordinated, responsible disclosure to the manufacturer in 2019, but have not received any feedback after numerous attempts.
As it has been more than three years and there is clear, public information that vulnerabilities in SATCOM terminals are actively being exploited by nation-state threat actors,9 we believe it is in the best interests for us to disclose this information so that all stakeholders can make informed risk decisions and respond to these threats.
As of the posting of this blog entry, IOActive has confirmed that all the initially disclosed vulnerabilities are still present in the most current, publicly available firmware images from the Wideye website.
Due to these heightened risks, IOActive will be releasing the full details of the vulnerabilities in both the iSavi and Ranger 5000 satellite terminals in approximately 14-days.
We are offering the additional two-week window to allow impacted stakeholders to assess their risks and put compensating controls in place.
You can read additional details about our decision to publicly disclose this research in the blog post here.
In our Biometric Testing Facility, we have conducted a large number of security assessment of both 2D and 3D-IR Based face authentication algorithms.
In this post, we introduce our Face Recognition Research whitepaper where we analyzed a number 2D-based algorithms used in commercially available mobiles phones. We successfully bypassed the facial authentication security mechanism on all tested devices for at least one of the participating subjects.
If you want to have a better understanding of the environment and type of tests performed to achieve these results, please refer to the following document: Face Recognition Research
Tested Devices
The devices used in this research were a Samsung Galaxy S10+, OnePlus 7 Pro, VIVO V15 Pro, Xiaomi Mi 9, and Nokia 9 Pure View with the characteristics shown below.
Device Model
OS Version
Build Number
Resolution
Focal Length
Aperture
Samsung S10(+)
Android 10/One UI 2.1
6975FXXU7CTF1
10MP
35mm
f/1.9
OnePlus 7 Pro
Android 10/Oxygen OS
10.0.7.GM21BA
16MP
25mm
f/2.0
Nokia 9 Pure View
Android 10
00WW_5_13D_SP01
20MP
1.0µm
f/2.0
Xiaomi Mi 9
Android 10/MIUI 11.0.6
QKQ1.190825.002
20MP
0.9μm
f/2.2
Vivo V15 Pro
Android 10/Funtouch OS_10
PD1832F_EX_A_6.19.9
32MP
X
f/2.0
Test Parameters
Subjects
We used subjects of various ethnicities: two Asian (male and woman), two African American (male and female), and one Caucasian (male).
Note that while we have subjects of three different ethnicities, the sample size is not sufficiently large enough to conclusively identify a statistically significant causal relationship between ethnicity and success rate.
Black-Box 2D Test Results
The following table illustrates the unlock probability observed during black-box testing using the following color code (red: reliable unlock, orange: occasional unlock, green: no unlock)
Again, while this sample size is insufficient to produce a statistically significant link between ethnicity and unlock success rate, it does indicate additional investigation is warranted.
Case Study: OnePlus 7 Pro
In addition to the above results, further analysis was conducted on the OnePlus 7 Pro, for the sake of understanding how the different subsystems are glued together. More information can be found in the Face Recognition Research whitepaper.
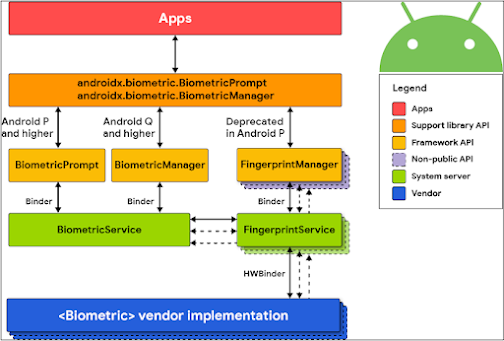
The basic Architecture implements the following basic components:
There are three interesting components that are useful for our goals:
1. App: Each vendor has its own Android application whose main function is to collect images, extract the facial features they consider interesting, and manage all the lock/unlock logic based on an IA model
2. BiometricManager: This is a private interface that maintains a connection with BiometricService.
3. Biometric vendor implementation: This must use secure hardware to ensure the integrity of the stored face data and the authentication comparison.
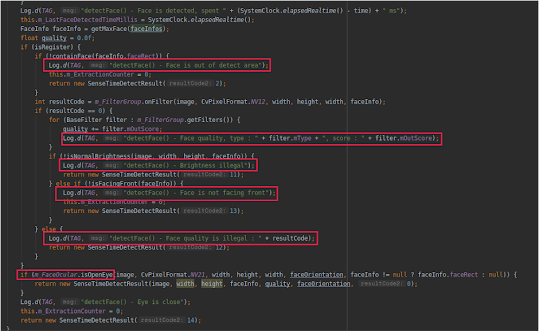
Looking into the application, we can spot the basis for face detection (full face in the image, quality, brightness, front facing, and opened eyes):
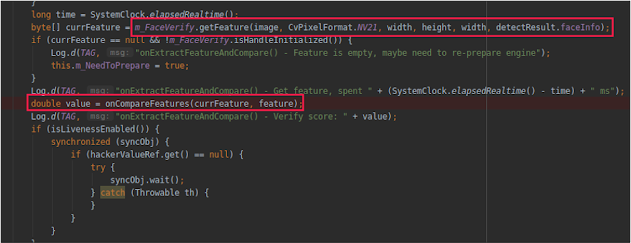
The following excerpt shows the most important part, extracting image features and comparing them to enrolled subject’s facial data.
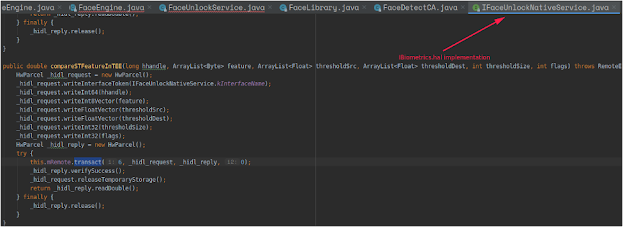
Continuing our analysis, we find IFaceUnlockNativeService (BiometricManager) which is the interface that will talk to the TEE hardware environment.
Once the match score is received, if it is a positive match and hackerValue is less than 0.95, the check process is completed, and the phone will be unlocked.
Additional Observations
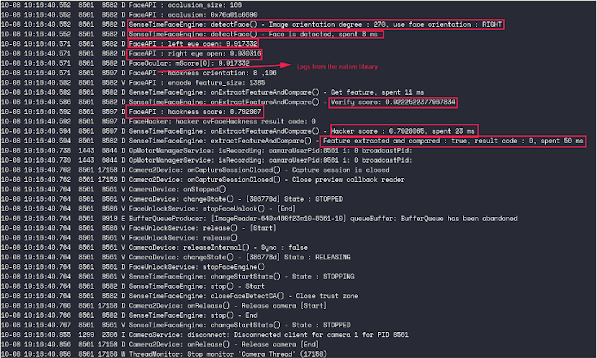
We observed that the code contains numerous log calls. This makes our task easier by disclosing useful information in real time while the phone is evaluating a face, which weren’t use during the results shown above.
The use of facial recognition systems has become pervasive on mobile phones and is making inroads in other sectors as the primary method to authenticate the end user of a system. These technologies rely on models created from an image or facial scan and selecting specific features that will be checked in a live environment against the actual user or an attacker. The algorithms need be accurate enough to detect a spoofing attempt, but flexible enough to make the technology useful under different lighting conditions and accommodate normal physical changes in the legitimate users.
As has been shown in this blog post, the technologies behind facial recognition have room for improvement. A number of techniques have been used to successfully bypass these algorithms and there is plenty of room for additional creative attack methods. System architects should carefully consider the risks of employing facial recognition systems for authentication in their systems and evaluate using more robust authentication methods until this technology matures.
WHITEPAPER | February 7, 2022
Facial Recognition Security Research
By
Gabriel Gonzalez
& Alejo Moles
IOActive, Inc. (IOActive) has conducted extensive research and testing of facial recognition systems on commercial mobile devices. Our testing lab includes testing setups for 2D- and 3D-based algorithms, including technologies using stereo IR cameras.
For each of the different technologies, we first try to understand the underlying algorithms and then come up with creative and innovative setups to bypass them. Once an unlock is achieved, we calculate the Spoof Acceptance Rate (SAR), as described in the Measuring Biometric Unlock Security” section of the Android Compatibility Definition Document.1 This metric allows us to compare different solutions and evaluate the strength of each solution.
This document describes IOActive’s results for commercially available mobile phones implementing face authentication mechanisms to unlock the device. All them relied on the “selfie-camera,” a single lens producing 2D RGB images. IOActive used 2D and 3D masks when attempting to bypass the security features.
Our comparison was based on a set of objectives bundled into five categories: Below the OS, Platform Update, Trusted Execution, Advanced Threat Protection, and Crypto Extension. Based on IOActive research, we conclude that AMD offers no corresponding technologies those categories while Intel offers features; Intel and AMD have equivalent capabilities in the Trusted Execution category.
How we hacked your billion-dollar company for forty-two bucks
By
Jamie Riden
subvert (v) : 3. To cause to serve a purpose other than the original or established one; commandeer or redirect: – freedictionary.com
Why did one straw break the camel’s back? Here’s the secret The million other straws underneath it – Mos Def, Mathematics
The basic idea of this blog post is that most organizations’ Internet perimeters are permeable. Weaknesses in outward-facing services are rarely independent of one another, and leveraging several together can often result in some sort of user-level access to internal systems.
A lot of traffic goes in and out of a normal company’s Internet perimeter: email comes in and goes out, web traffic from customers or potential customers comes in, web traffic for internal users goes out, and lots of necessary services create traffic, such as Citrix remote desktop, web authentication (especially password resets), helpdesk services, file exchange and more. The question is, can we make use of combinations of seemingly minor problems to access internal systems? The answer is mostly, yes.
To substantiate the admittedly clickbait-y title (it was delivered as a talk at B-Sides London), we spent eight dollars a month on a Linux VPS and occasionally bought a .com domain for 10 bucks. In fact, the biggest single expenditure was on coffee.All domain names have been anonymized below; if the ones I have given exist, they are not the entity I am describing. Obviously, all of this was done at the request of the particular entity, in order to find weaknesses so they could be fixed.
Definitions
‘Username enumeration’ is the term used when a function confirms whether a username is valid or not. For example, password reset processes that tell you a username doesn’t exist. A difference in response time will also do, if consistent enough—it doesn’t have to be explicit. However, office.com logins tell you clearly: “This username may be incorrect … “
‘Password spraying’ refers to checking one password against lots and lots of users, so that by the time you come back to a user to try a new password, any account lockout counters have been reset. For example, trying “Spring2022!” against jeff@example.com and dave@example.com, etc. Of course, there may be rate limits on guesses, as well as account lockout policies, and if so, we will need to deal with that.
Tahi.com
Initially, we used an OSINT tool called FOCA (https://www.elevenpaths.com/innovation-labs/technologies/foca) to find any metadata in published documents. FOCA will search and download files like PDFs and Word docs, and look for properties like ‘author’ or ‘operating system’ or anything that may be of interest to an attacker. This didn’t result in much, apart from a few things that might be user IDs of the form ‘ID01234567’.
On the perimeter, we noticed the helpdesk web page allowed user enumeration, but this was pretty slow and would need special scripting to exploit in bulk. It helped confirm that the information we’d found were user IDs, but it wasn’t ideal for large-scale harvesting.
As the target exposed OWA, we used MailSniper (https://github.com/dafthack/MailSniper), and in particular, Invoke-UsernameHarvestOWA to confirm valid user IDs in a large block surrounding the IDs we had found with FOCA. This resulted in a couple of thousand users in the particular range, and from there, we moved on to using Invoke-PasswordSprayOWA from the same package.
We started using MailSniper to enumerate on 16th of the month, kept it running pretty much continuously doing one thing or another, and by the 22nd we had obtained passwords for two users.
OWA did not have two-factor authentication (2FA) enabled, so we had access to two email accounts, and internal mail filtering is a lot less restrictive than for mail coming in from outside. That means we can do something like send a custom implant in reply to a real email and ask the victim to run it.
In this case, the problems were: having guessable usernames and guessable passwords at the same time and not enforcing 2FA for all services.
Rua.com
Again, we used FOCA to establish a few examples, in this case, some combination of first and last name, like “jsmith.” We downloaded common US surnames (https://americansurnames.us/top-surnames) and made a list of likely candidates with common first initials and last names. This can be done with a simple bash one-liner.
MSOLSpray.py (https://github.com/MartinIngesen/MSOLSpray) is a Python implementation of a tool called MSOLSpray (https://github.com/dafthack/MSOLSpray) implemented in PowerShell. As I prefer using Python tooling, I picked this one to try out the various candidate usernames against the Microsoft Online login—the same thing you authenticate to when logging in to office.com, for example. In this case, we also used a tool called Fireprox (https://github.com/ustayready/fireprox) to rotate the source IP address and evade any rate-limiting controls based on source IP.
Some manual checks of the initial results showed that it was not a straightforward login once a username had been correctly guessed; there was then a web redirect to an on-premise Identity Provider (IdP). In this case, MSOLSpray.py (and I think the original MSOLSpray) determines the existence correctly but does not confirm the correct password. So we needed to figure out how to fix that.
People who do any sort of work testing websites may have come across a tool called Selenium (https://selenium-python.readthedocs.io/)–this enables a script written in Python, for example, to drive the browser through a set process and allows the script to query information back from the web pages. After some hours of scripting, it was possible to get Selenium/Python/Chrome to walk through the login process from start to finish and distinguish between valid users with the correct password, valid users with the wrong password, and users that do not exist. The whole thing took maybe 30 seconds per try on average, so while not quick, it was eminently feasible—and remember, MSOLSpray.py had at least confirmed which usernames existed.
Figure 1 – using Selenium’s WebDriver to enter information into web pages
Using Selenium, we got correct passwords for around 10 users. 2FA had been enabled with registration on first login, but the nature of business meant a lot of staff had never logged in and thus had not registered their own 2FA tokens.
We registered our own 2FA token against some of these accounts and logged in to a Citrix desktop. From there, we could deploy a custom implant directly, as well as query AD for configuration weaknesses with tools such as BloodHound.
Again, having guessable passwords combined with not having fully configured 2FA for everyone allowed us to gain access.
Toru.com
We had already guessed two sets of credentials for toru.com but needed more privileges.
Exploring the perimeter led to the discovery of a website where people book time off from work, which seemed to have an open URL redirect; that is, it did not validate the url parameter correctly for redirecting after a successful login.
We hosted a cloned page, but with a “wrong password” error already on it. The phishing email we sent gave a legitimate page address but with ?url=<phishing site>:
Users would get “[EXTERNAL]” in the subject line, but the link was obviously to their own site.
The real site took the username and password and would redirect to the cloned page on successful login. The cloned site reported “wrong creds, please retry”, and then redirected back to the original, valid logged-in session that had been established.
No one even noticed they’d been phished.
Despite the fact that IT had blocked the URL on the corporate proxy (thanks to a service that looked out for domain typo-squatting), we still got 10 or so sets of credentials from people using their own devices at home.
Again, toru.com did not use 2FA for OWA, so we could access more email accounts and find a good reason for someone to execute our implant, attached to an internal only email.
Users would get “[EXTERNAL]” in the subject line, but the link was obviously to their own site.
The real site took the username and password and would redirect to the cloned page on successful login. The cloned site reported “wrong creds, please retry”, and then redirected back to the original, valid logged-in session that had been established.
No one even noticed they’d been phished.
Despite the fact that IT had blocked the URL on the corporate proxy (thanks to a service that looked out for domain typo-squatting), we still got 10 or so sets of credentials from people using their own devices at home.
Again, toru.com did not use 2FA for OWA, so we could access more email accounts and find a good reason for someone to execute our implant, attached to an internal only email.
Rima.com
Rima.com used hybrid AD, so again we could do password spraying against Microsoft Online with MSOLSpray.py and Fireprox.
User IDs were also numeric (i.e. “A01234567”).
We found a few passwords (in the form MonthYear or SeasonYear!), but it initially looked like everything required 2FA; however, the very useful MFASweep tool (https://github.com/dafthack/MFASweep) discovered the ActiveSync mail protocol was an exception.
Once we knew this, we could use Windows 10 Mail to send emails from a compromised user to another user – including executable attachments.
Key Takeaways
In all four cases, we managed to get some way of executing code inside the perimeter – and then could proceed to the “normal” red team activities of dropping Cobalt Strike implants and exploring inside the organisation.A combination of “minor” issues can be very serious indeed. Remember that CVSS2 does not consider interactions between different issues, so a CVSS “medium” like open URL redirect might need an urgent fix.
User enumeration exists in a lot of different places on most perimeters; any instance of it will do for an attacker.
Red Team
Password spraying is a numbers game; aim for a thousand usernames if you can, but the more the better.
Bigger and/or older companies can actually be easier targets because they have larger attack surfaces.
Although a red team is by no means an audit, such an exercise is certainly a worthwhile avenue of attack, and at worst, it’s something to leave running in the background while you do the cool Cobalt Strike implant stuff.
Blue Team
Log everything. Monitor everything. It will come in useful at some point.
Weak passwords need to be changed proactively.
Aim to use 2FA across all services. No exceptions.
Keeping an inventory of all hosts and turning off obsolete services is a really good idea.
While I don’t normally recommend expiring passwords, it can help if you are strengthening your password policy, as weaker passwords will age out. Obviously, just the standard Windows policy of ‘at least 3 of 4 character classes’ will not do, because “Summer2022!” meets it; try to stop people setting passwords based on dictionary words and keyboard patterns.
“Honeypots” can be quite useful. For example, you can create a VM which has RDP privileges for everyone—BloodHound will pick this up. You know any logins to that VM are, at best, unnecessary and, at worst, an attacker probing for AD weaknesses. Equally, you can create a service account with an SPN so that the password hash can be recovered via kerberoasting. If no one should be using it, any time anyone logs in to the account, it is likely bad news.