X509TrustManager local1 = new X509TrustManager()
{
public void checkClientTrusted(X509Certificate[]
paramAnonymousArrayOfX509Certificate,
String paramAnonymousString)
throws CertificateException { }
public void checkServerTrusted(X509Certificate[]
paramAnonymousArrayOfX509Certificate,
String paramAnonymousString)
throws CertificateException { }
public X509Certificate[] getAcceptedIssuers()
{
return null;
}
}
Similarly, the following python code using urllib2 disables SSL verification:
import urllib2
import ssl
ctx = ssl.create_default_context()
ctx.check_hostname = False
ctx.verify_mode = ssl.CERT_NONE
urllib2.urlopen(“https://www.ioactive.com”, context=ctx)
These issues are not hard to spot while reading code, but what about a complete black box approach? Here is where Certslayer comes to the rescue.
How does it work?
Proxy Mode
Certslayer starts a proxy server and monitors for specified domains. Whenever a client makes a request to a targeted domain, the proxy redirects the request to an internal web server, presenting a special certificate as a test-case. If the internal web server receives the request, it means the client accepted the test certificate, and the connection was successful at the TLS level. On the other hand, if the internal web server doesn’t receive a request, it means the client rejected the presented certificate and aborted the connection.
For testing mobile applications, the proxy mode is very useful. All a tester needs to do is install the certificate authority (Certslayer CA) in the phone as trusted and configure the system proxy before running the tool. Simply by using the application, generates requests to its server’s backend which are trapped by the proxy monitor and redirected accordingly to the internal web server. This approach also reveals if there is any sort of certificate pinning in place, as the request will not succeed when a valid certificate signed by the CA gets presented.
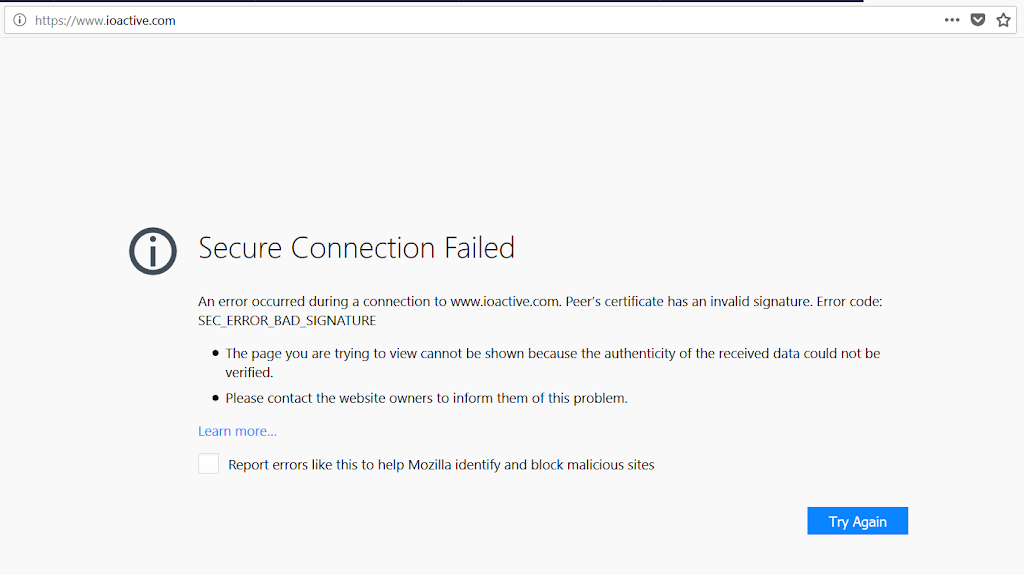
A simple way to test in this mode is to configure the browser proxy and navigate to a target domain. For example, the next command will start the proxy mode on port 9090 and will monitor requests to www.ioactive.com:
C:\CertSlayerCertSlayer>python CertSlayer.py -d www.ioactive.com -m proxy -p 9090
Currently, the following certificate test-cases are available (and will run in order):
- CertificateInvalidCASignature
- CertificateUnknownCA
- CertificateSignedWithCA
- CertificateSelfSigned
- CertificateWrongCN
- CertificateSignWithMD5
- CertificateSignWithMD4
- CertificateExpired
- CertificateNotYetValid
The error code explains the problem: SEC_ERROR_BAD_SIGNATURE, which matches the first test-case in the list. At this point, Certslayer has already prepared the next test-case in the list. By reloading the page with F5, we get the next result.
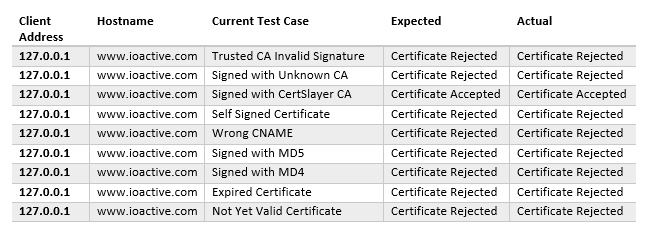
At the end, a csv file will generate containing the results of each test-case. The following table summarizes them for this example:
Stand-alone Mode
Proxy mode is not useful when testing a web application or web service that allows fetching resources from a specified endpoint. In most instances, there won’t be a way to install a root CA at the application backend for doing these tests. However, there are applications that include this feature in their design, like, for instance, cloud applications that allow interacting with third party services.
In these scenarios, besides checking for SSRF vulnerabilities, we also need to check if the requester is actually verifying the presented certificate. We do this using Certslayer standalone mode. Standalone mode binds a web server configured with a test-certificate to all network interfaces and waits for connections.
I recently tested a cloud application that allowed installing a root CA to enable interaction with custom SOAP services served over HTTPS. Using the standalone mode, I found the library in use wasn’t correctly checking the certificate common name (CN). To run the test-suite, I registered a temporary DNS name (http://ipq.co/) to my public IP address and ran Certslayer with the following command:
C:CertSlayerCertSlayer>python CertSlayer.py -m standalone -p 4444 -i j22d1i.ipq.co
+ Setting up WebServer with Test: Trusted CA Invalid Signature
>> Hit enter for setting the next TestCase
The command initialized standalone mode listening on port 4444. The test certificates then used j22d1i.ipq.co as the CN.
After this, I instructed the application to perform the request to my server:
POST /tools/soapconnector HTTP/1.1
Host: foo.com
Content-Type: application/json; charset=utf-8
X-Requested-With: XMLHttpRequest
Content-Length: 55
Cookie: –
Connection: close
{“version”:”1.0″,”wsdl”:”https://j22d1i.ipq.co:4444/”}
Server response:
{“status”:500,”title”:”Problem accessing WSDL description”,”detail”:”We couldn’t open a connection to the service (Describe URL: https://j22d1i.ipq.co:4444/). Reason: Signature does not match. Check the availability of the service and try again”}
The connection was refused. The server error described the reason why: the CA signature didn’t match. Hitting enter in the python console made the tool prepare the next test case:
+ Killing previous server
j22d1i.ipq.co,Trusted CA Invalid Signature,Certificate Rejected,Certificate Rejected
+ Setting up WebServer with Test: Signed with CertSlayer CA
>> Hit enter for setting the next TestCase
Here, the connection succeeded because the tool presented a valid certificate signed with Certslayer CA:
Server Response:
{“status”:500,”detail”: “We couldn’t process the WSDL https://j22d1i.ipq.co:4444/. Verify the validity of the WSDL file and that it’s available in the specified location.”}
Certslayer output:
j22d1i.ipq.co,Signed with CertSlayer CA,Certificate Accepted,Certificate Accepted
xxx.yyy.zzz.www – – [14/Dec/2017 18:35:04] “GET / HTTP/1.1” 200 –
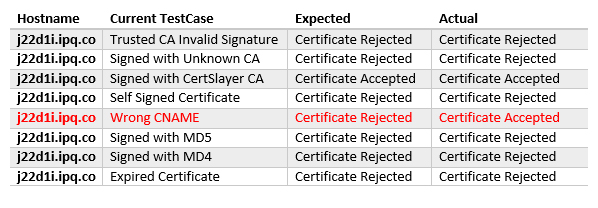
When the web server is configured with a certificate with a wrong CN, the expected result is that the client will abort the connection. However, this particular application accepted the certificate anyway:
+ Setting up WebServer with Test: Wrong CNAME
>> Hit enter for setting the next TestCase
xxx.yyy.zzz.www – – [14/Dec/2017 18:35:54] “GET / HTTP/1.1” 200 –
j22d1i.ipq.co,Wrong CNAME,Certificate Rejected,Certificate Accepted
As before, a csv file was generated containing all the test cases with the actual and expected results. For this particular engagement, the result was:
A similar tool exists called tslpretense, the main difference is that, instead of using a proxy to intercept requests to targeted domains, it requires configuring the test runner as a gateway so that all traffic the client generates goes through it. Configuring a gateway host this way is tedious, which is the primary reason Certslayer was created.