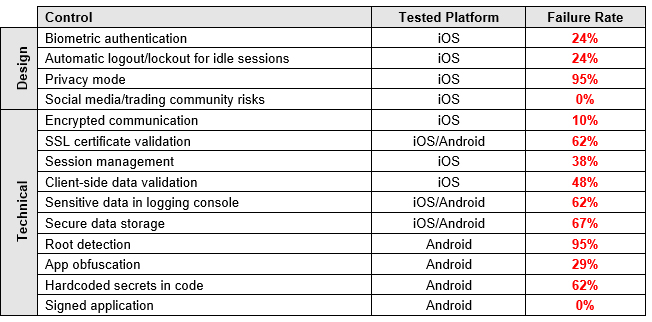
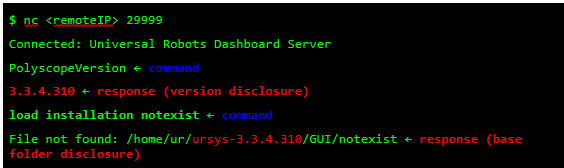
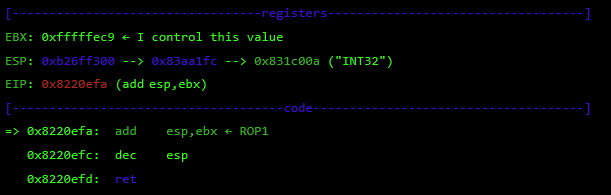
I tested the following 14 security controls, which represent just the tip of the iceberg when compared to an exhaustive list of security checks for mobile apps. This may give you a better picture of the current state of these apps’ security. It’s worth noting that I could not test all of the controls in some of the apps either because a feature was not implemented (e.g. social chats) or it was not technically feasible (e.g. SSL pinning that wouldn’t allow data manipulation), or simply because I could not open an account.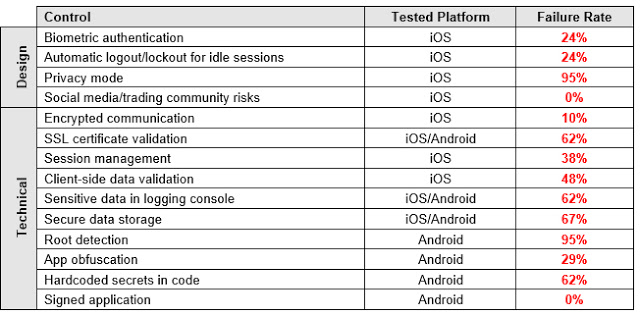
Results
Unfortunately, the results proved to be much worse than those for personal banking apps in 2013 and 2015.[4] [5] Cybersecurity has not been on the radar of the FinTech space in charge of developing trading apps. Security researchers have disregarded these apps as well, probably because of a lack of understanding of money markets.
The issues I found in the tested controls are grouped in the following sections. Logos and technical details that mention the name of brokerage institutions were removed from the screenshots, logs, and reverse engineered code to prevent any negative impacts to their customers or reputation.
Cleartext Passwords Exposed
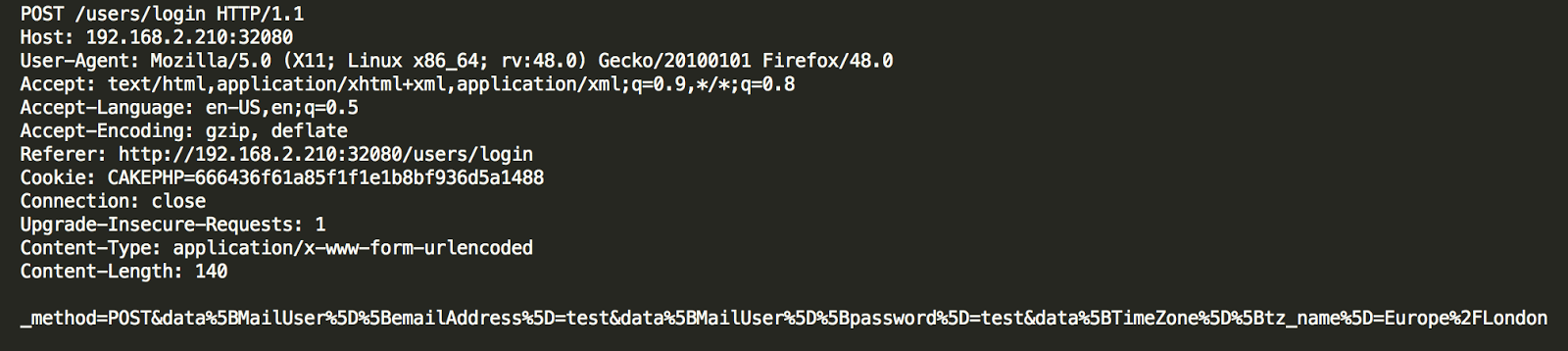
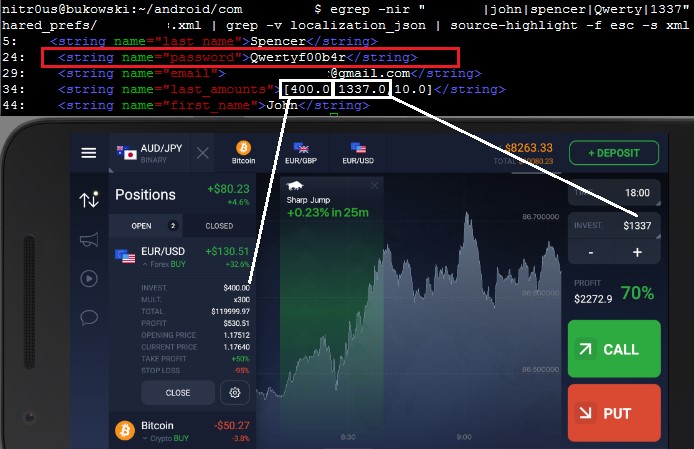
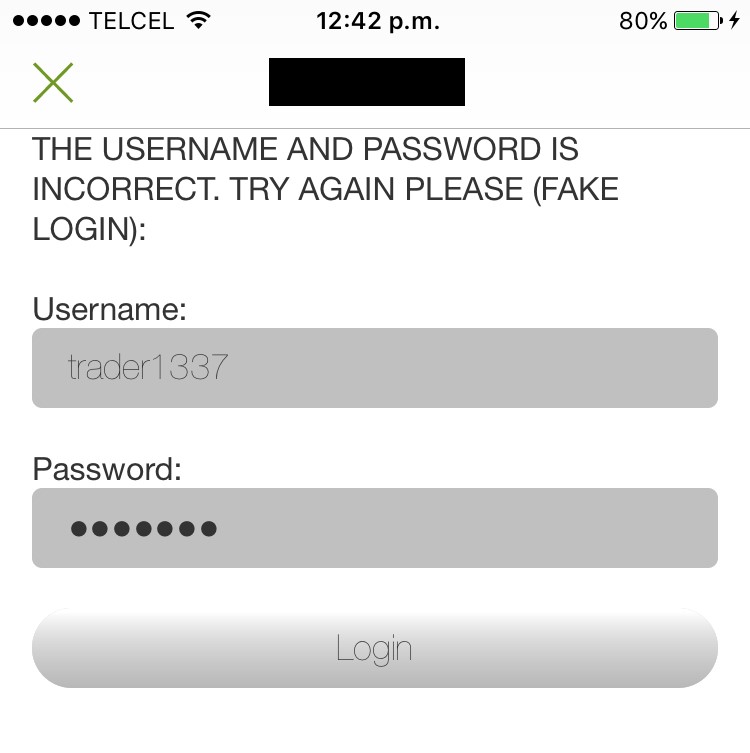
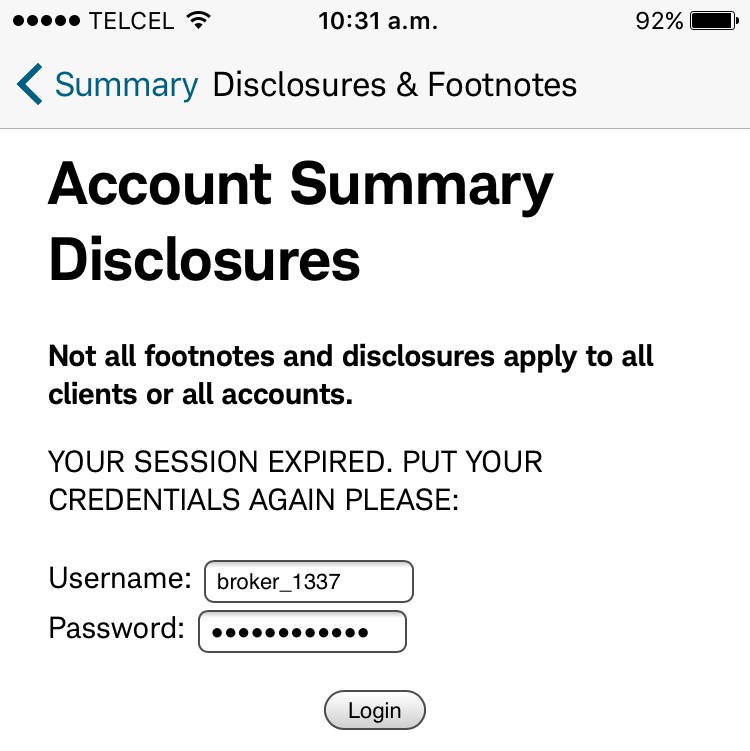
In four apps (19%), the user’s password was sent in cleartext either to an unencrypted XML configuration file or to the logging console. Physical access to the device is required to extract them, though.
In a hypothetical attack scenario, a malicious user could extract a password from the file system or the logging functionality without any in-deptfh know-how (it’s relatively easily), log in through any other trading platform from the brokerage firm, and perform unauthorized actions. They could sell stocks, transfer the money to a newly added bank account, and delete this bank account after the transfer is complete. During testing, I noticed that most of the apps require only the current password to link banking accounts and do not have two-factor authentication (2FA) implemented, therefore, no authorization one-time-password (OTP) is sent to the user’s phone or email.
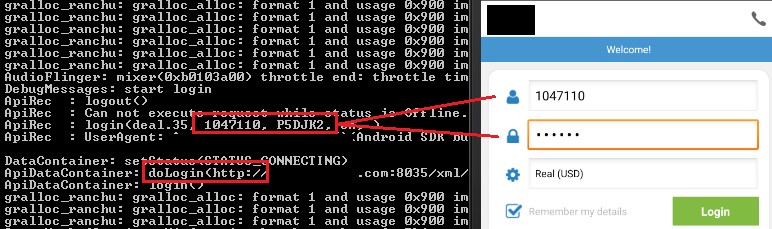
In two apps, like the following one, in addition to logging the username and password, authentication takes place through an unencrypted HTTP channel:
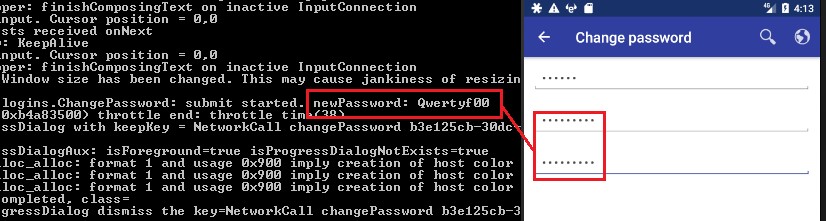
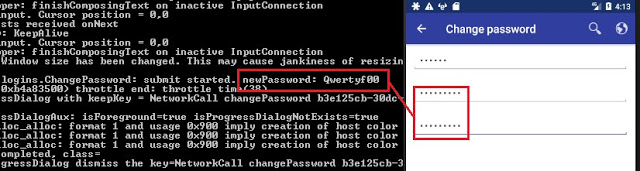
In another app, the new password was exposed in the logging console when a user changes the password:
Trading and Account Information Exposed
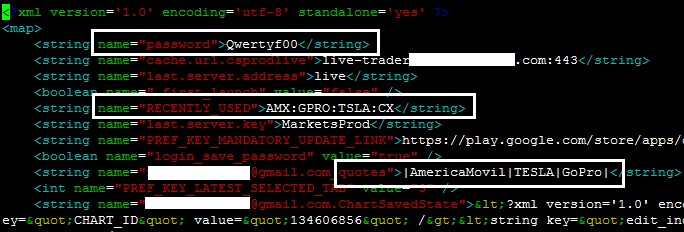
In the trading context, operational or strategic data must not be sent unencrypted to the logging console nor any log file. This sensitive data encompasses values such as personal data, general balances, cash balance, margin balance, net worth, net liquidity, the number of positions, recently quoted symbols, watchlists, buy/sell orders, alerts, equity, buying power, and deposits. Additionally, sensitive technical values such as username, password, session ID, URLs, and cryptographic tokens should not be exposed either.
62% of the apps sent sensitive data to log files, and 67% stored it unencrypted. Physical access to the device is required to extract this data.
If these values are somehow leaked, a malicious user could gain insight into users’ net worth and investing strategy by knowing which instruments users have been looking for recently, as well as their balances, positions, watchlists, buying power, etc.
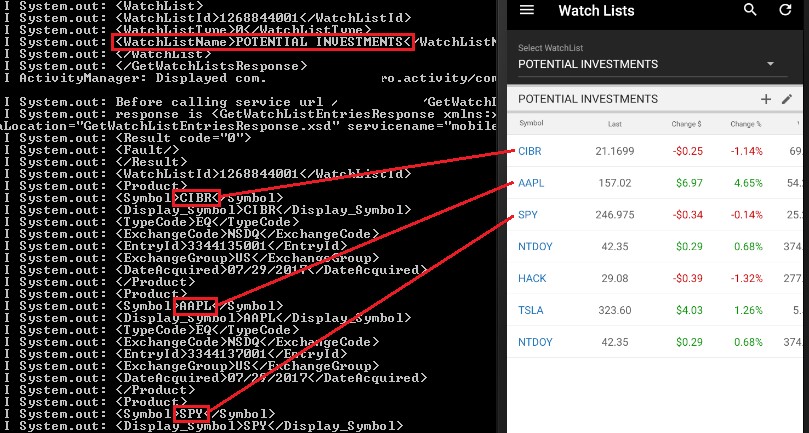
Imagine a hypothetical scenario where a high-profile, sophisticated investor loses his phone and the trading app he has been using stores his “Potential Investments” watchlist in cleartext. If the extracted watchlist ends up in the hands of someone who wants to mimic this investor’s strategy, they could buy stocks prior to a price increase. In the worst case, imagine a “Net Worth” figure landing in the wrong hands, say kidnappers, who now know how generous ransom could be.
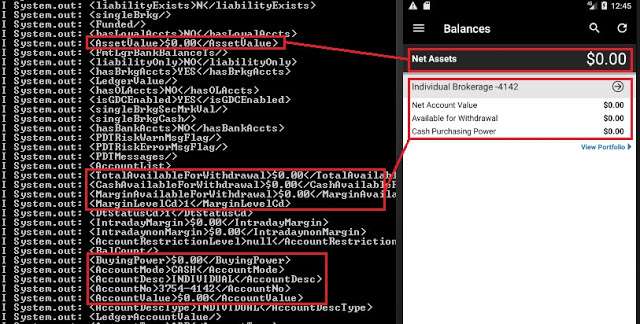
Balances and investment portfolio leaked in logs:
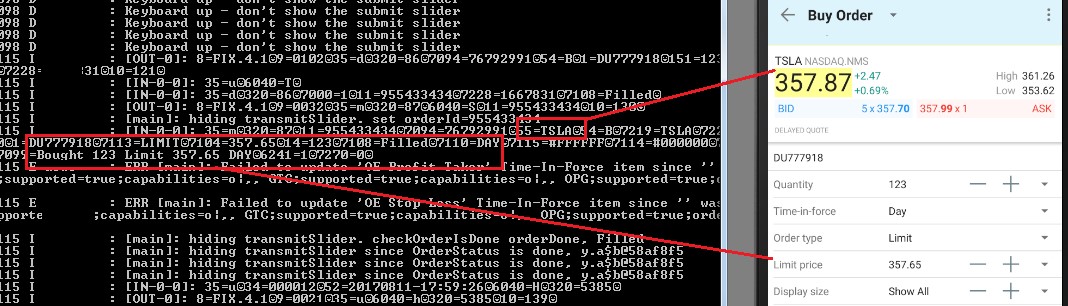
Buy and sell orders leaked in detail in the logging console:
Personal information stored in configuration files:
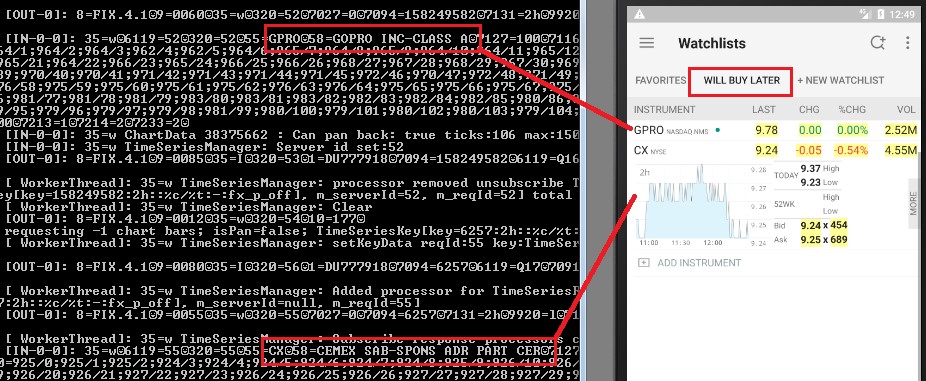
“Potential Investments” and “Will Buy Later” watchlists leaked in the logs console:
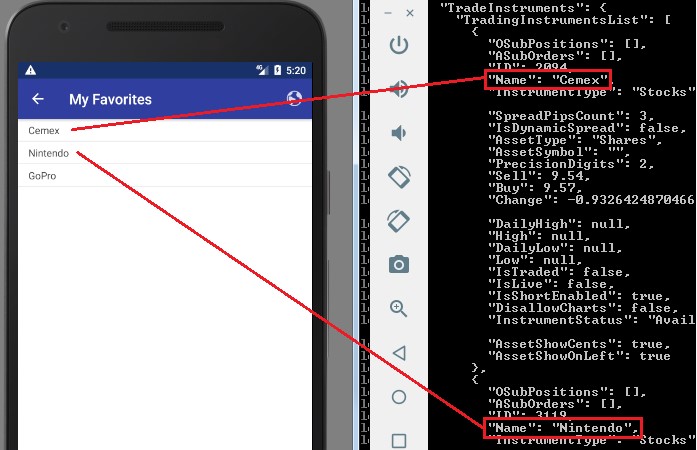
“Favorites” watchlists leaked in the logs too:
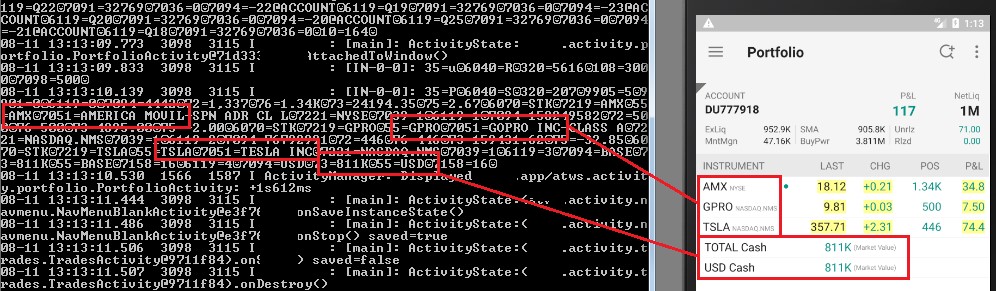
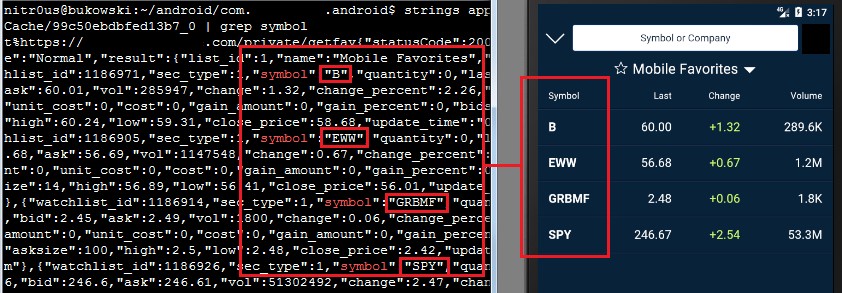
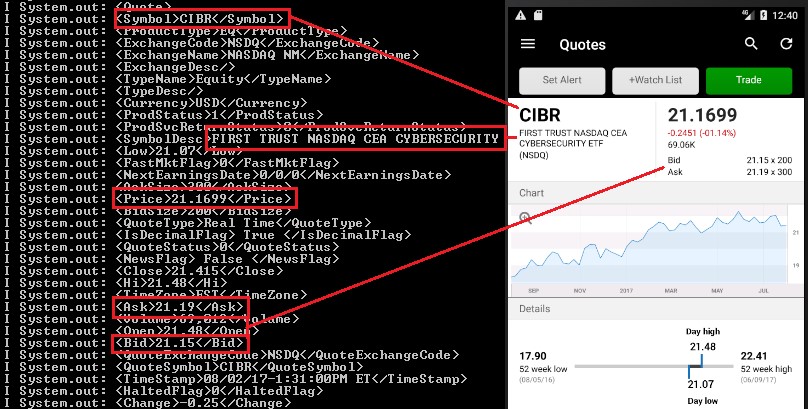
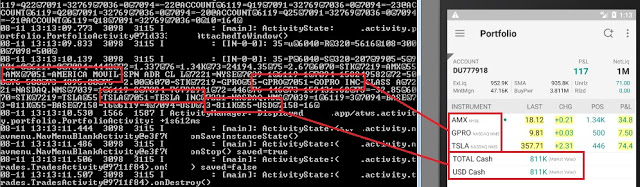
Quoted tickers leaked:
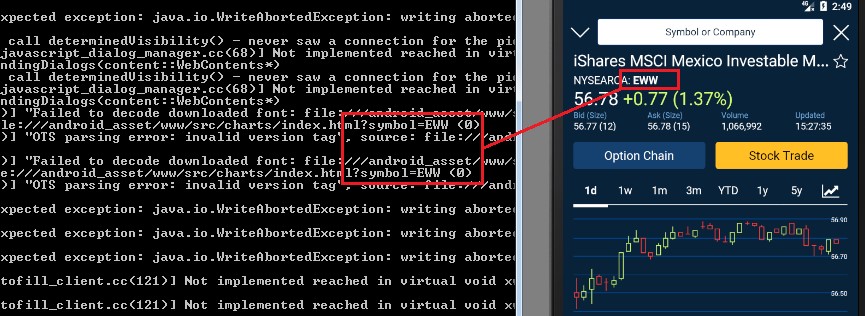
Symbol quoted dumped in detail in the console:
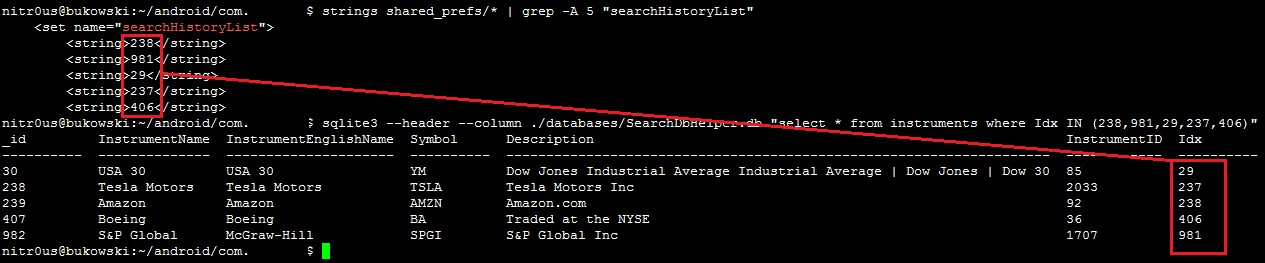
Quoted instruments saved in a local SQLite database:
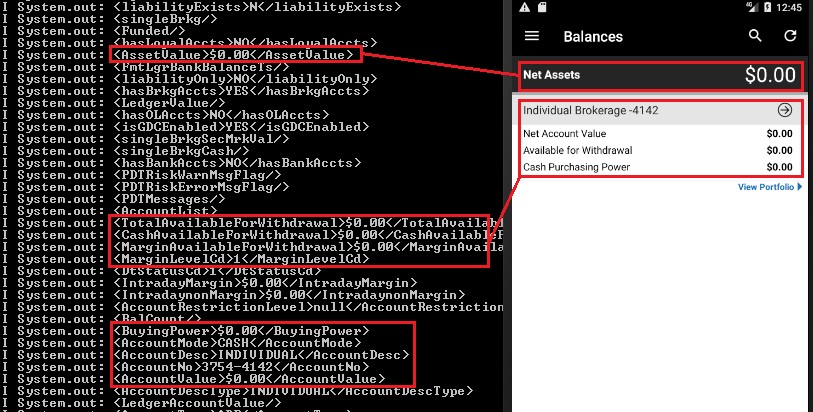
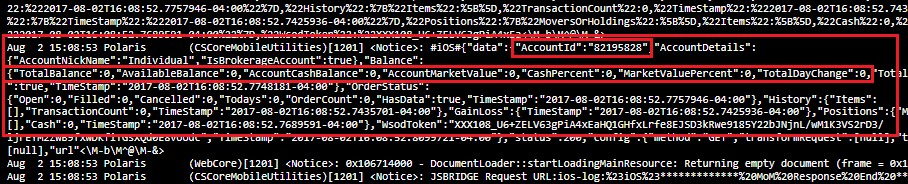
Account number and balances leaked:
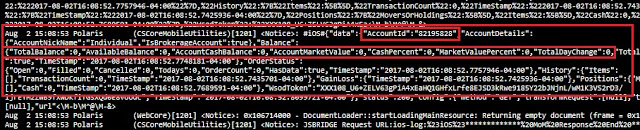
Insecure Communication
Two apps use unencrypted HTTP channels to transmit and receive all data, and 13 of 19 apps that use HTTPS do not check the authenticity of the remote endpoint by verifying its SSL certificate (SSL pinning); therefore, it’s feasible to perform Man-in-the-Middle (MiTM) attacks to eavesdrop on and tamper with data. Some MiTM attacks require to trick the user into installing a malicious certificate on the mobile device.
Under certain circumstances, an attacker with access to some part of the network, such as the router in a public Wi-Fi, could see and modify information transmitted to and from the mobile app. In the trading context, a malicious actor could intercept and alter values, such as the bid or ask prices of an instrument, and cause a user to buy or sell securities based on misleading information.
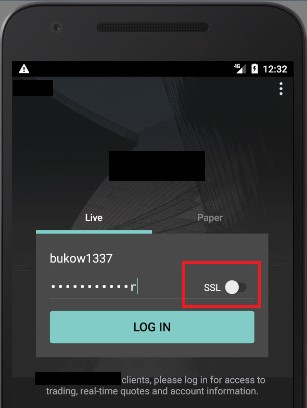
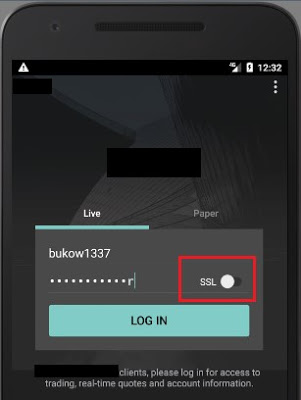
For instance, the following app uses an insecure channel for communication by default; an inexperienced user who does not know the meaning of “SSL” (Secure Socket Layer) won’t enable it on the login screen and all sensitive data will be sent and received in cleartext, without encryption:
One single app was found to send a log file with sensitive trading data to the server on a scheduled basis over an unencrypted HTTP channel.
Some apps transmit non-sensitive data (e.g. public news or live financial TV broadcastings) through insecure channels, which does not seem to represent a risk to the user.
Authentication and Session Management
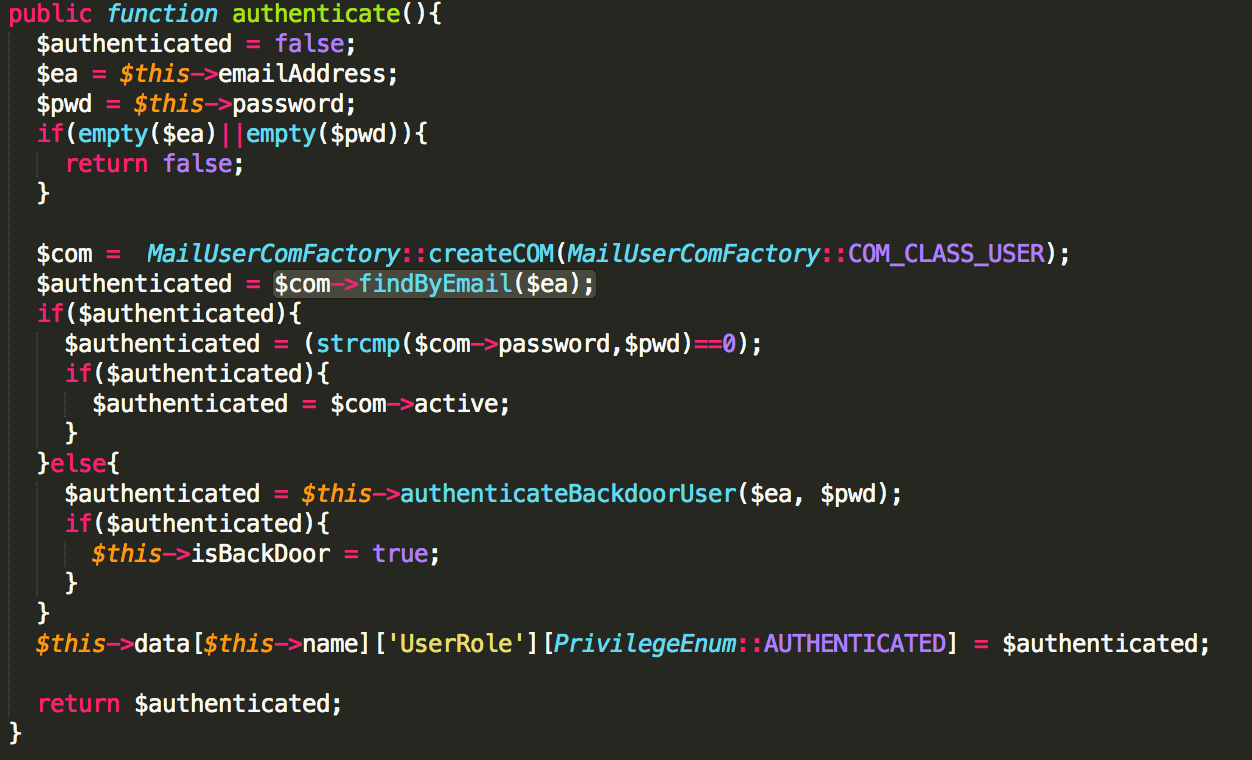
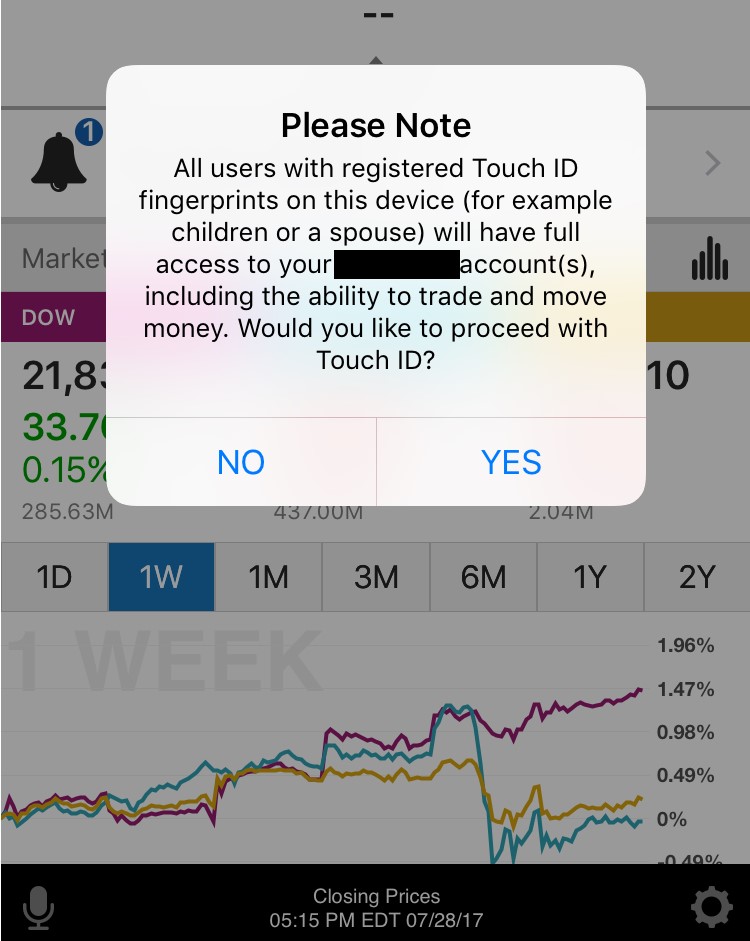
Nowadays, most modern smartphones support fingerprint-reading, and most trading apps use it to authenticate their customers. Only five apps (24%) do not implement this feature.
Unfortunately, using the fingerprint database in the phone has a downside:
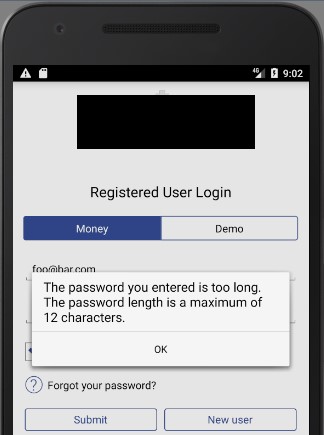
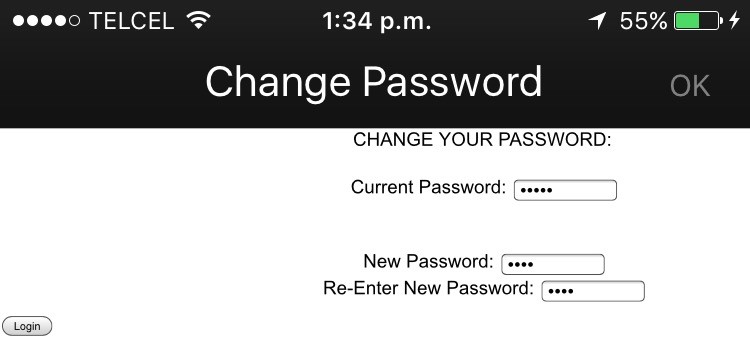
Moreover, after clicking the logout button, sessions were still valid on the server side in two apps. Also, another couple of apps enforced lax password policies:
Privacy Mode
One single trading app (look for “the moral of the story” earlier in this article) supports “Privacy Mode,” which protects the customers’ private information displayed on the screen in public areas where shoulder-surfing[6] attacks are feasible. The rest of the apps do not implement this useful and important feature.
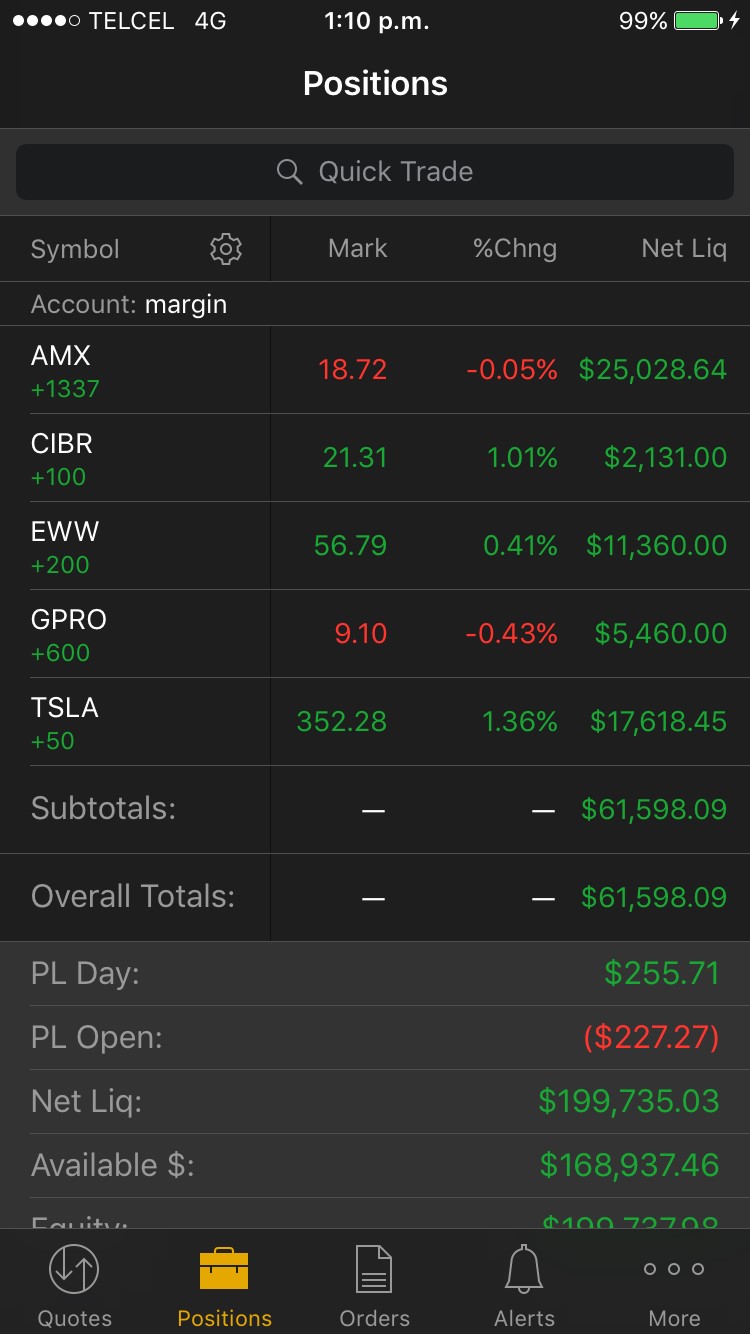
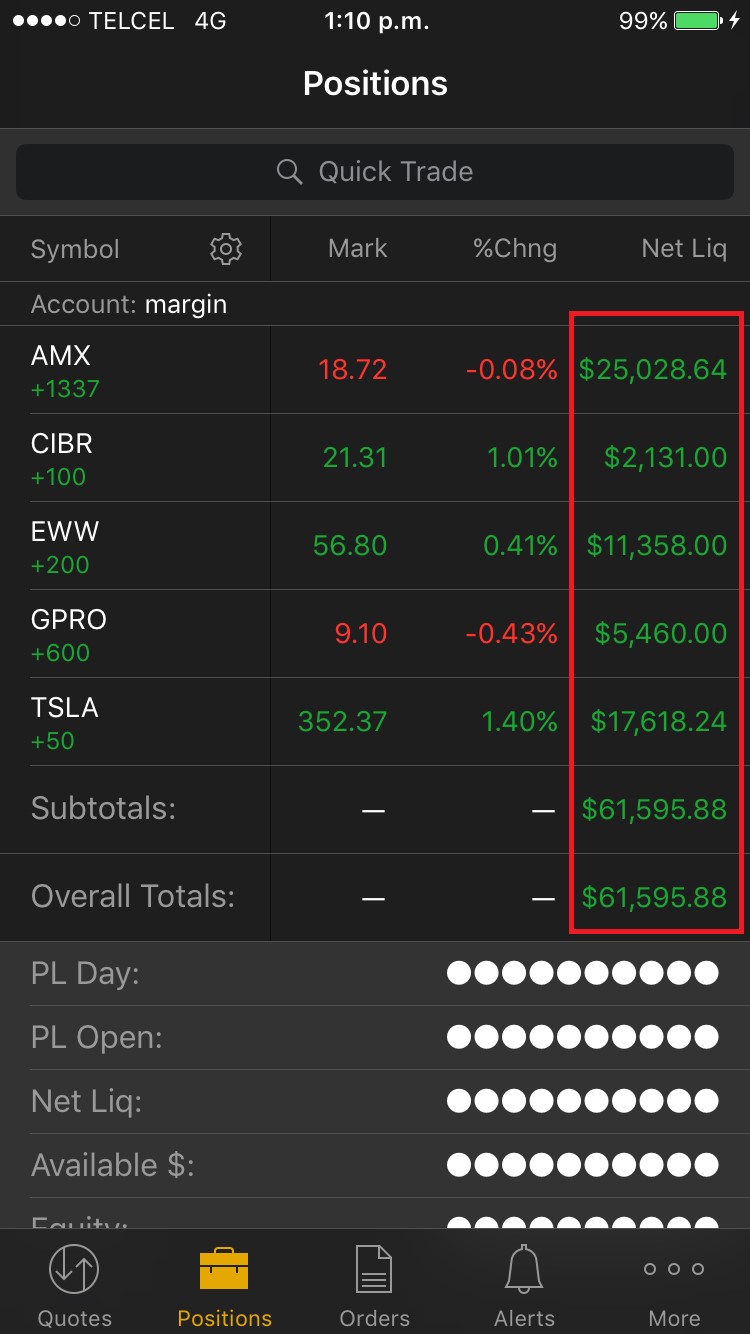
However, there’s a small bug in this unique implementation: every sensitive figure is masked except in the “Positions” tab where the “Net Liquidity” column and the “Overall Totals” are fully visible:
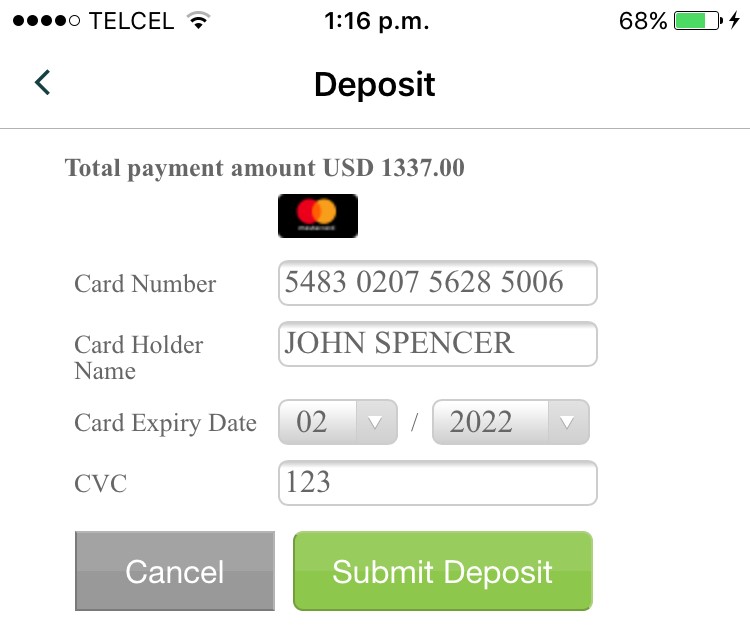
It’s worth noting that not only balances, positions, and other sensitive values in the trading context should be masked, but also credit card information when entered to fund the account:
Client-side Data Validation
In most, but not all, of the apps that don’t check SSL certificates, it’s possible to perform MiTM attacks and inject malicious JavaScript or HTML code in the server responses. Since the Web Views in ten apps are configured to execute JavaScript code, it’s possible to trigger common Cross-site Scripting (XSS) attacks.
XSS triggered in two different apps (<script>alert(document.cookie);</script>):
Fake HTML forms injected to deceive the user and steal credentials:
Root Detection
Many Android apps do not run on rooted devices for security reasons. On a rooted phone or emulator, the user has full control of the system, thus, access to files, databases, and logs is complete. Once a user has full access to these elements, it’s easy to extract valuable information.
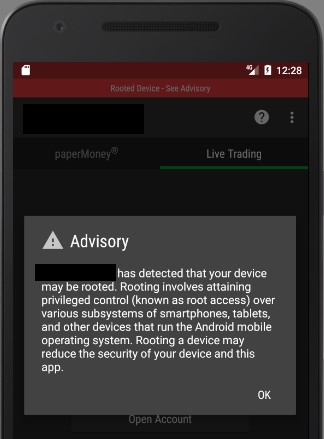
20 of the apps (95%) do not detect rooted environments. The single app (look for “the moral of the story” earlier in this article) that does detect it simply shows a warning message; it allows the user to keep using the platform normally:
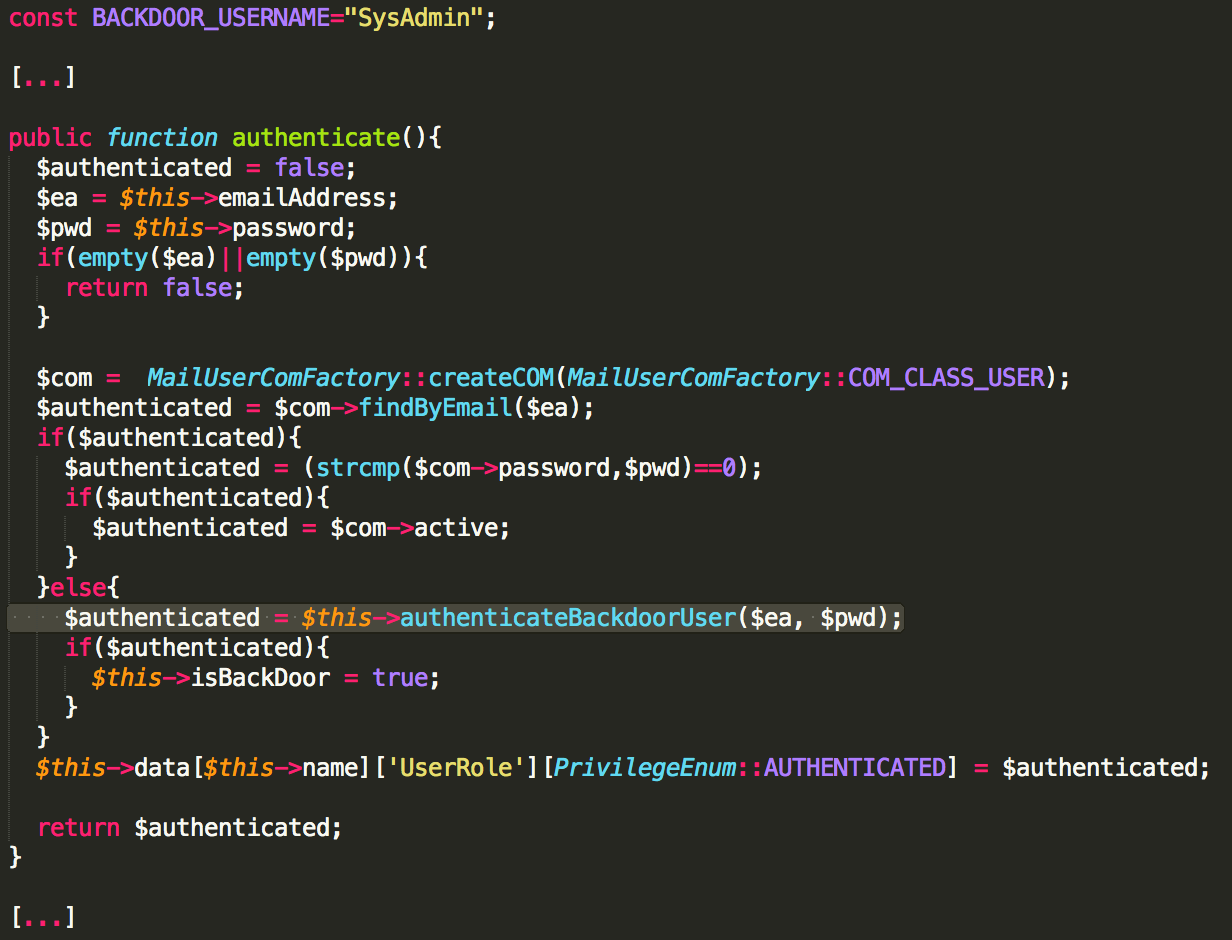
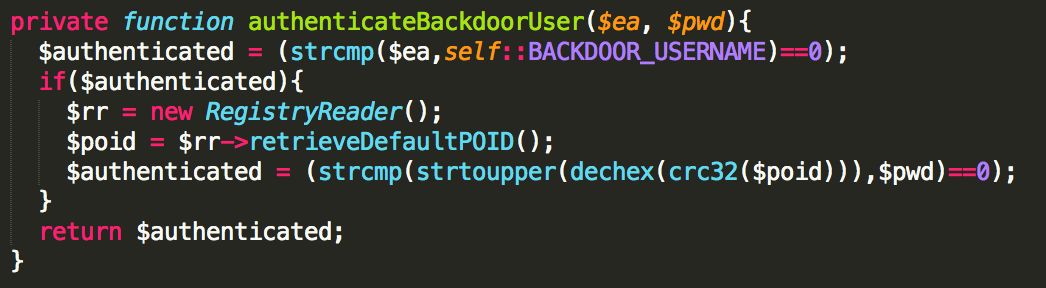
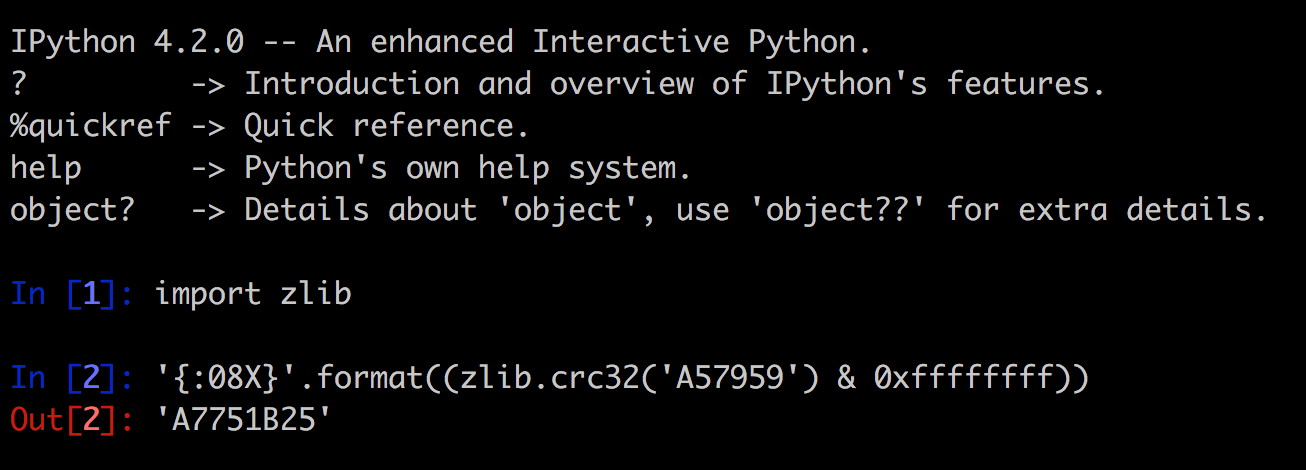
Hardcoded Secrets in Code and App Obfuscation
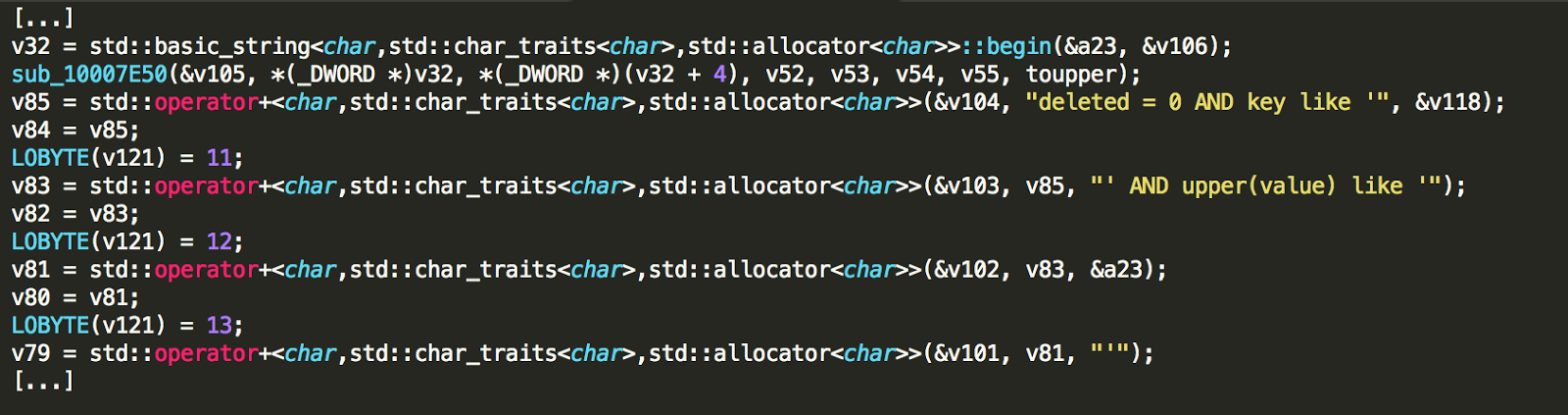
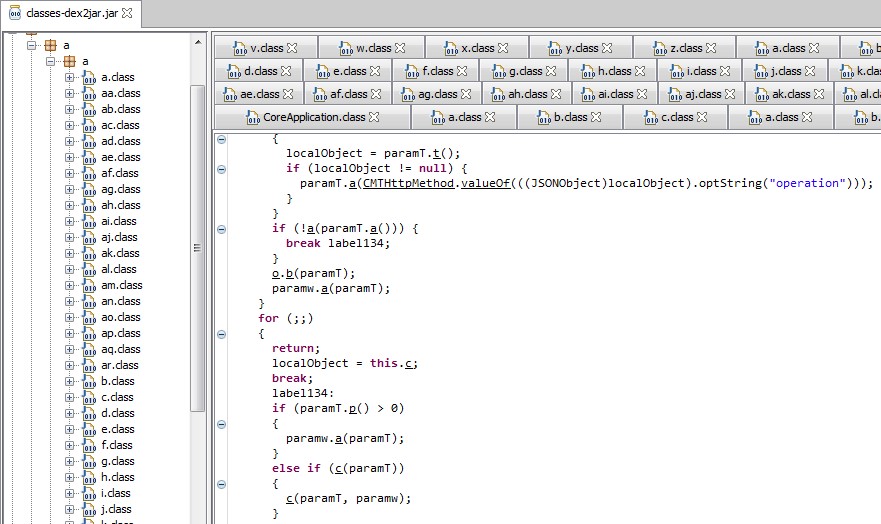
Six Android app installers (.apk files) were easily reverse engineered to human-readable code. The rest had medium to high levels of obfuscation, as the one shown below. The goal of obfuscation is to conceal the applications purpose (security through obscurity) and logic in order to deter reverse engineering and to make it more difficult.
In the non-obfuscated apps, I found secrets such as cryptographic keys and third-party service partner passwords. This could allow unauthorized access to other systems that are not under the control of the brokerage houses. For example, a Morningstar.com account (investment research) hardcoded in a Java class:
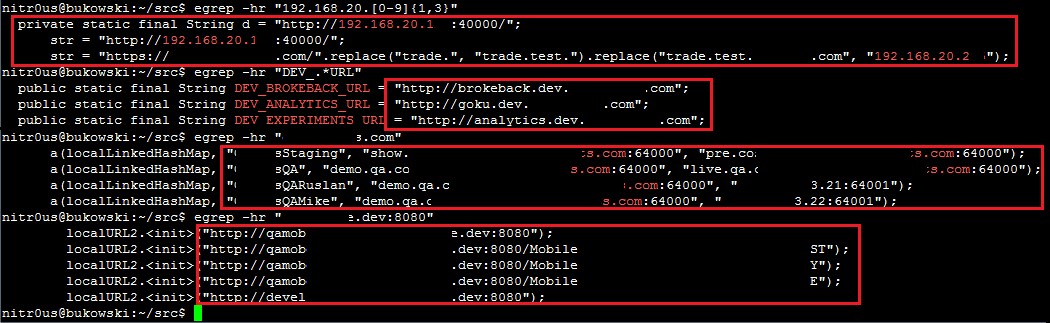
Interestingly, ten of the apps (47%) have traces (internal hostnames and IPs) about the internal development and testing environments where they were made or tested:
Other Weaknesses
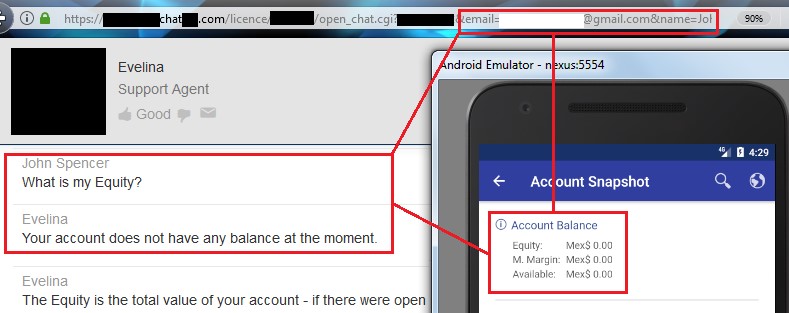
The following trust issue grabbed my attention: a URL with my username (email) and first name passed as parameters was leaked to the logging console. This URL is opened to talk with, apparently, a chatbot inside the mobile app, but if you grab this URL and open it in a common web browser, the chatbot takes your identity from the supplied parameters and trusts you as a logged in user. From there, you can ask details about your account. As you can see, all you need to retrieve someone else’s private data is to know his/her email only and his/her name:
I haven’t had enough time to fully test this feature, but so far, I was able to extract balances and personal information.
Statistics
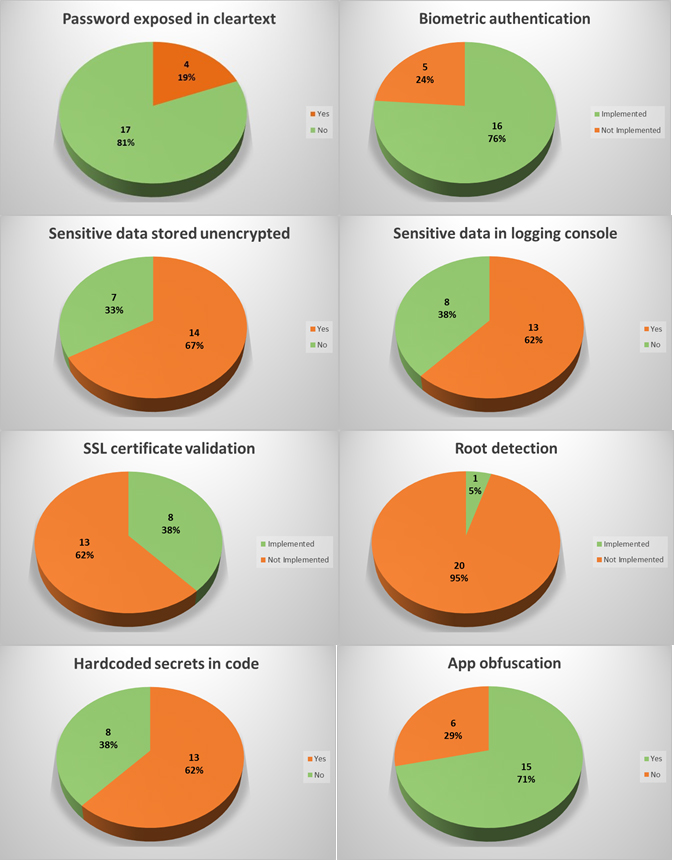
Since a picture is worth a thousand words, consider the following graphs:
Responsible Disclosure
One of IOActive’s missions is to act responsibly when it comes to vulnerability disclosure, thus, between September 6th and 8th, we sent a detailed report to 13 of the brokerage firms whose trading apps presented some of the higher risks vulnerabilities discussed in this article.
To the date, only two brokerage firms replied our email.
Regulators and Rating Organizations
Digging in some US regulators’ websites,[7] [8] [9] I noticed that they are already aware of the cybersecurity threats that might negatively impact financial markets and stakeholders. Most of the published content focuses on general threats that could impact end-users or institutions such as phishing, identity theft, antivirus software, social media risks, privacy, and procedures to follow in case of cybersecurity incidents, such as data breaches or disruptive attacks.
Nevertheless, I did not find any documentation related to the security risks of electronic trading nor any recommended guidance for secure software development to educate brokers and FinTech companies on how to create quality products.

Picture taken from http://www.reuters.com/article/net-us-internet-lending/for-online-lenders-wall-street-cash-brings-growth-and-risk-idUSBRE96204I20130703
In addition, there are rating organizations that score online brokers on a scale of 1 to 5 stars. I glimpsed at two recent reports [10] [11] and didn’t find anything related to security or privacy in their reviews. Nowadays, with the frequent cyberattacks in the financial industry, I think these organizations should give accolades or at least mention the security mechanisms the evaluated trading platforms implement in their reviews. Security controls should equal a competitive advantage.
Conclusions and Recommendations
- There’s still a long way to go to improve the maturity level of security in mobile trading apps.
- Desktop and web platforms should also be tested and improved.
- Regulators should encourage brokers to implement safeguards for a better trading environment.
- In addition to the generic IT best practices for secure software development, regulators should develop trading-specific guidelines to be followed by the brokerage firms and FinTech companies in charge of creating trading software.
- Brokerage firms should perform regular internal audits to continuously improve the security posture of their trading platforms.
- Developers should analyze their apps to determine if they suffer from the vulnerabilities I have described in this post, and if so, fix them.
- Developers should design new, more secure financial software following secure coding practices.
- End users should enable all of the security mechanisms their apps offer.

Side Thought
Remember: the stock market is not a casino where you magically get rich overnight. If you lack an understanding of how stocks or other financial instruments work, there is a high risk of losing money quickly. You must understand the market and its purpose before investing.
With nothing left to say, I wish you happy and secure trading!
Thanks for reading,
Alejandro
References
[1] Ponzi scheme
[2] “Pump-and-Dumps” and Market Manipulations
[3] Practical Examples Of How Blockchains Are Used In Banking And The Financial Services Sector
[4] Personal banking apps leak info through phone
[5] (In)secure iOS Mobile Banking Apps – 2015 Edition
[6] Shoulder surfing (computer security)
[7] Financial Industry Regulatory Authority: Cybersecurity
[8] Securities Industry and Financial Markets Association: Cybersecurity
[9] U.S. Securities and Exchange Commission: Cybersecurity, the SEC and You
[10] NerdWallet: Best Online Brokers for Stock Trading 2017
[11] StockBrockers: 2017 Online Broker Rankings