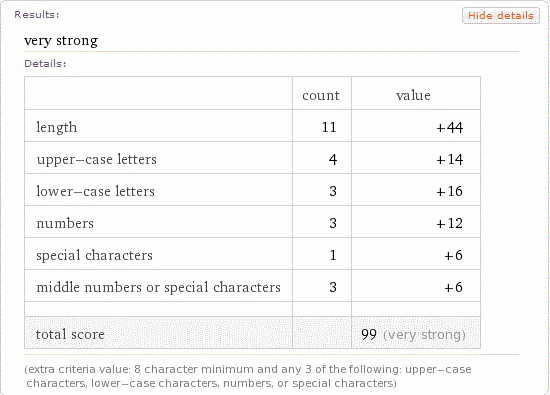
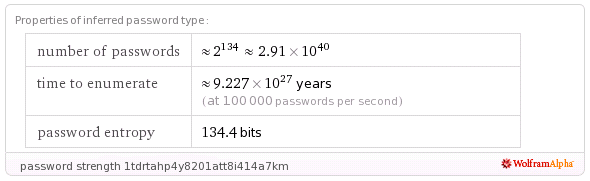
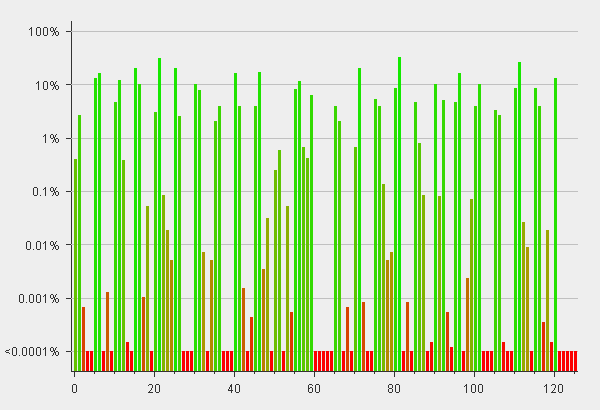
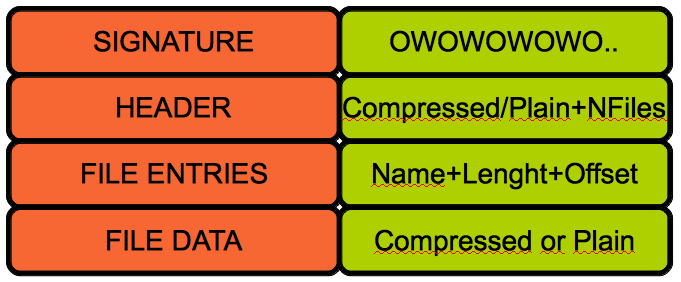
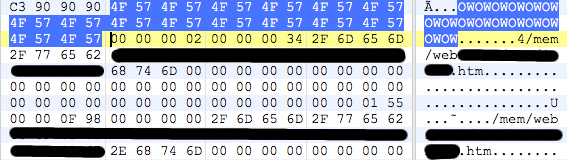
See if you can find the backdoor, I’ll post the explanation and details on the flaw soon.
// eBookLib.cpp : main project file.
// Project requirements
// Add/Remove/Query eBooks
// One code file (KISS in effect)
//
//
// **** Mostly generated from Visual Studio project templates ****
//
#define WIN32_LEAN_AND_MEAN
#define _WIN32_WINNT 0x501
#include <windows.h>
#include <stdio.h>
#include <wchar.h>
#include <msclrmarshal.h>
#using <Microsoft.VisualC.dll>
#using <System.dll>
#using <System.Core.dll>
using namespace System;
using namespace System::IO;
using namespace System::Threading;
using namespace System::Threading::Tasks;
using namespace System::Reflection;
using namespace System::Diagnostics;
using namespace System::Globalization;
using namespace System::Collections::Generic;
using namespace System::Security::Permissions;
using namespace System::Runtime::InteropServices;
using namespace System::IO::MemoryMappedFiles;
using namespace System::IO;
using namespace System::Runtime::CompilerServices;
using namespace msclr;
using namespace msclr::interop;
//
// General Information about an assembly is controlled through the following
// set of attributes. Change these attribute values to modify the information
// associated with an assembly.
//
[assembly:AssemblyTitleAttribute(“eBookLib”)];
[assembly:AssemblyDescriptionAttribute(“”)];
[assembly:AssemblyConfigurationAttribute(“”)];
[assembly:AssemblyCompanyAttribute(“Microsoft”)];
[assembly:AssemblyProductAttribute(“eBookLib”)];
[assembly:AssemblyCopyrightAttribute(“Copyright (c) Microsoft 2010”)];
[assembly:AssemblyTrademarkAttribute(“”)];
[assembly:AssemblyCultureAttribute(“”)];
//
// Version information for an assembly consists of the following four values:
//
// Major Version
// Minor Version
// Build Number
// Revision
//
// You can specify all the value or you can default the Revision and Build Numbers
// by using the ‘*’ as shown below:
[assembly:AssemblyVersionAttribute(“1.0.*”)];
[assembly:ComVisible(false)];
[assembly:CLSCompliantAttribute(true)];
[assembly:SecurityPermission(SecurityAction::RequestMinimum, UnmanagedCode = true)];
////////////////////////////////////////////////////////////////////////////////////////////////////////////////
// Native structures used from legacy system,
// define the disk storage for our ebook,
//
// The file specified by the constructor is read from and loaded automatically, it is also auto saved when closed.
////////////////////////////////////////////////////////////////////////////////////////////////////////////////
enum eBookFlag
{
NOFLAG = 0,
ACTIVE = 1,
PENDING_REMOVE = 2
};
typedef struct _eBookAccountingData
{
// Binary Data, may include nulls
char PurchaseOrder[ACCOUNTING_SIZE];
char RecieptData[ACCOUNTING_SIZE];
size_t PurchaseOrderLength;
size_t RecieptDataLength;
} eBookAccountingData, *PeBookAccountingData;
typedef struct _eBookPublicData
{
wchar_t ISBN[BUFSIZ];
wchar_t MISC[BUFSIZ];
wchar_t ShortName[BUFSIZ];
wchar_t Author[BUFSIZ];
wchar_t LongName[BUFSIZ];
wchar_t PathToFile[MAX_PATH];
int Rating;
int SerialNumber;
} eBookPublicData, *PeBookPublicData;
typedef struct _eBook
{
eBookFlag Flag;
eBookAccountingData Priv;
eBookPublicData Pub;
} eBook, *PeBook;
// define managed analogues for native/serialized types
namespace Client {
namespace ManagedEbookLib {
[System::FlagsAttribute]
public enum class ManagedeBookFlag : int
{
NOFLAG = 0x0,
ACTIVE = 0x1,
PENDING_REMOVE = 0x2,
};
public ref class ManagedEbookPublic
{
public:
__clrcall ManagedEbookPublic()
{
ISBN = MISC = ShortName = Author = LongName = PathToFile = String::Empty;
}
Int32 Rating;
String^ ISBN;
String^ MISC;
Int32 SerialNumber;
String^ ShortName;
String^ Author;
String^ LongName;
String^ PathToFile;
};
public ref class ManagedEbookAccounting
{
public:
__clrcall ManagedEbookAccounting()
{
PurchaseOrder = gcnew array<Byte>(0);
RecieptData = gcnew array<Byte>(0);
}
array<Byte>^ PurchaseOrder;
array<Byte>^ RecieptData;
};
public ref class ManagedEbook
{
public:
__clrcall ManagedEbook()
{
Pub = gcnew ManagedEbookPublic();
Priv = gcnew ManagedEbookAccounting();
}
ManagedeBookFlag Flag;
ManagedEbookPublic^ Pub;
ManagedEbookAccounting^ Priv;
array<Byte^>^ BookData;
};
}
}
using namespace Client::ManagedEbookLib;
// extend marshal library for native/managed inter-op
namespace msclr {
namespace interop {
template<>
inline ManagedEbookAccounting^ marshal_as<ManagedEbookAccounting^, eBookAccountingData> (const eBookAccountingData& Src)
{
ManagedEbookAccounting^ Dest = gcnew ManagedEbookAccounting;
if(Src.PurchaseOrderLength > 0 && Src.PurchaseOrderLength < sizeof(Src.PurchaseOrder))
{
Dest->PurchaseOrder = gcnew array<Byte>((int) Src.PurchaseOrderLength);
Marshal::Copy(static_cast<IntPtr>(Src.PurchaseOrder[0]), Dest->PurchaseOrder, 0, (int) Src.PurchaseOrderLength);
}
if(Src.RecieptDataLength > 0 && Src.RecieptDataLength < sizeof(Src.RecieptData))
{
Dest->RecieptData = gcnew array<Byte>((int) Src.RecieptDataLength);
Marshal::Copy(static_cast<IntPtr>(Src.RecieptData[0]), Dest->RecieptData, 0, (int) Src.RecieptDataLength);
}
return Dest;
};
template<>
inline ManagedEbookPublic^ marshal_as<ManagedEbookPublic^, eBookPublicData> (const eBookPublicData& Src) {
ManagedEbookPublic^ Dest = gcnew ManagedEbookPublic;
Dest->Rating = Src.Rating;
Dest->ISBN = gcnew String(Src.ISBN);
Dest->MISC = gcnew String(Src.MISC);
Dest->SerialNumber = Src.SerialNumber;
Dest->ShortName = gcnew String(Src.ShortName);
Dest->Author = gcnew String(Src.Author);
Dest->LongName = gcnew String(Src.LongName);
Dest->PathToFile = gcnew String(Src.PathToFile);
return Dest;
};
template<>
inline ManagedEbook^ marshal_as<ManagedEbook^, eBook> (const eBook& Src) {
ManagedEbook^ Dest = gcnew ManagedEbook;
Dest->Priv = marshal_as<ManagedEbookAccounting^>(Src.Priv);
Dest->Pub = marshal_as<ManagedEbookPublic^>(Src.Pub);
Dest->Flag = static_cast<ManagedeBookFlag>(Src.Flag);
return Dest;
};
}
}
// Primary user namespace
namespace Client
{
namespace ManagedEbooks
{
// “Store” is Client::ManagedEbooks::Store()
public ref class Store
{
private:
String^ DataStore;
List<ManagedEbook^>^ Books;
HANDLE hFile;
// serialization from disk
void __clrcall LoadDB()
{
Books = gcnew List<ManagedEbook^>();
eBook AeBook;
DWORD red = 0;
marshal_context^ x = gcnew marshal_context();
hFile = CreateFileW(x->marshal_as<const wchar_t*>(DataStore), GENERIC_READ | GENERIC_WRITE, FILE_SHARE_READ | FILE_SHARE_WRITE | FILE_SHARE_DELETE, 0, OPEN_ALWAYS, 0, 0);
if(hFile == INVALID_HANDLE_VALUE)
return;
do {
ReadFile(hFile, &AeBook, sizeof(eBook), &red, NULL);
if(red == sizeof(eBook))
Books->Add(marshal_as<ManagedEbook^>(AeBook));
} while(red == sizeof(eBook));
}
// scan hay for anything that matches needle
bool __clrcall MatchBook(ManagedEbook ^hay, ManagedEbook^ needle)
{
// check numeric values first
if(hay->Pub->Rating != 0 && hay->Pub->Rating == needle->Pub->Rating)
return true;
if(hay->Pub->SerialNumber != 0 && hay->Pub->SerialNumber == needle->Pub->SerialNumber)
return true;
// scan each string
if(!String::IsNullOrEmpty(hay->Pub->ISBN) && hay->Pub->ISBN->Contains(needle->Pub->ISBN))
return true;
if(!String::IsNullOrEmpty(hay->Pub->MISC) && hay->Pub->MISC->Contains(needle->Pub->MISC))
return true;
if(!String::IsNullOrEmpty(hay->Pub->ShortName) && hay->Pub->ShortName->Contains(needle->Pub->ShortName))
return true;
if(!String::IsNullOrEmpty(hay->Pub->Author) && hay->Pub->Author->Contains(needle->Pub->Author))
return true;
if(!String::IsNullOrEmpty(hay->Pub->LongName) && hay->Pub->LongName->Contains(needle->Pub->LongName))
return true;
if(!String::IsNullOrEmpty(hay->Pub->PathToFile) && hay->Pub->PathToFile->Contains(needle->Pub->PathToFile))
return true;
return false;
}
// destructor
__clrcall !Store()
{
Close();
}
// serialization to disk happens here
void __clrcall _Close()
{
if(hFile == INVALID_HANDLE_VALUE)
return;
SetFilePointer(hFile, 0, NULL, FILE_BEGIN);
for each(ManagedEbook^ book in Books)
{
eBook save;
DWORD wrote=0;
marshal_context^ x = gcnew marshal_context();
ZeroMemory(&save, sizeof(save));
save.Pub.Rating = book->Pub->Rating;
save.Pub.SerialNumber = book->Pub->SerialNumber;
save.Flag = static_cast<eBookFlag>(book->Flag);
swprintf_s(save.Pub.ISBN, sizeof(save.Pub.ISBN), L”%s”, x->marshal_as<const wchar_t*>(book->Pub->ISBN));
swprintf_s(save.Pub.MISC, sizeof(save.Pub.MISC), L”%s”, x->marshal_as<const wchar_t*>(book->Pub->MISC));
swprintf_s(save.Pub.ShortName, sizeof(save.Pub.ShortName), L”%s”, x->marshal_as<const wchar_t*>(book->Pub->ShortName));
swprintf_s(save.Pub.Author, sizeof(save.Pub.Author), L”%s”, x->marshal_as<const wchar_t*>(book->Pub->Author));
swprintf_s(save.Pub.LongName, sizeof(save.Pub.LongName), L”%s”, x->marshal_as<const wchar_t*>(book->Pub->LongName));
swprintf_s(save.Pub.PathToFile, sizeof(save.Pub.PathToFile), L”%s”, x->marshal_as<const wchar_t*>(book->Pub->PathToFile));
if(book->Priv->PurchaseOrder->Length > 0)
{
pin_ptr<Byte> pin = &book->Priv->PurchaseOrder[0];
save.Priv.PurchaseOrderLength = min(sizeof(save.Priv.PurchaseOrder), book->Priv->PurchaseOrder->Length);
memcpy(save.Priv.PurchaseOrder, pin, save.Priv.PurchaseOrderLength);
pin = nullptr;
}
if(book->Priv->RecieptData->Length > 0)
{
pin_ptr<Byte> pin = &book->Priv->RecieptData[0];
save.Priv.RecieptDataLength = min(sizeof(save.Priv.RecieptData), book->Priv->RecieptData->Length);
memcpy(save.Priv.RecieptData, pin, save.Priv.RecieptDataLength);
pin = nullptr;
}
WriteFile(hFile, &save, sizeof(save), &wrote, NULL);
if(wrote != sizeof(save))
return;
}
CloseHandle(hFile);
hFile = INVALID_HANDLE_VALUE;
}
protected:
// destructor forwards to the disposable interface
virtual __clrcall ~Store()
{
this->!Store();
}
public:
// possibly hide this
void __clrcall Close()
{
_Close();
}
// constructor
__clrcall Store(String^ DataStoreDB)
{
DataStore = DataStoreDB;
LoadDB();
}
// add ebook
void __clrcall Add(ManagedEbook^ eBook)
{
Books->Add(eBook);
}
// remove ebook
void __clrcall Remove(ManagedEbook^ eBook)
{
Books->Remove(eBook);
}
// get query list
List<ManagedEbook^>^ __clrcall Query(ManagedEbook^ eBook)
{
List<ManagedEbook^>^ rv = gcnew List<ManagedEbook^>();
for each(ManagedEbook^ book in Books)
{
if(MatchBook(book, eBook))
rv->Add(book);
}
return rv;
}
};
}
}