iOS devices are everywhere now. It seems that pretty much every other person has one…an iPhone, iPad or iPod touch – and they’re rivaled in popularity only by Android devices.
If you do secure code review, chances are that with the explosion in the number of iOS apps, you may well have done a source code review of an iOS app, or at least played around with some Objective-C code. Objective-C can be a little strange at first for those of us who are used to plain C and C++ (i.e. all the square brackets!), and even stranger for Java coders, but after a while most of us realise that the standard iOS programming environment is packed with some pretty powerful Cocoa APIs, and Objective-C itself actually has some cool features as well. The runtime supports a number of quirky features as well, which people tend to learn shortly after the standard “Hello, World!” stuff…
Objective-C brings a few of its own concepts and terminology into the mix as well. Using Objective-C syntax, we might call a simple method taking one integer parameter like this:
returnVal = [someObject myMethod:1234];
In other object-oriented languages like C++ and Java we’d normally just refer to this as “calling a member function” or “calling a method”, or even “calling a method on an object”. However, Objective-C differs slightly in this respect and as such, you do not call methods – instead, you “send a message to an object”. This concept as a whole is known as ‘message passing’.
The net result is the same – the ‘myMethod’ method associated with someObject’s class is called, but the semantics in how the runtime calls the method is somewhat different to how a C++ runtime might.
Whenever the ObjC compiler sees a line of code such as “[someObject myMethod]”, it inserts a call to one of the objc_msgSend(_XXX) APIs with the “receiver” (someObject) and the “selector” (“myMethod:”) as parameters to the function. This family of functions will, at runtime, figure out which piece of code needs to be executed bearing in mind the object’s class, and then eventually JMPs to it. This might seem a bit long-winded, but since the correct method to call is determined at runtime, this is part of how Objective-C gets its dynamism from.
The call above may end up looking something roughly like this, after the compiler has dealt with it:
objc_msgSend(someObject, “myMethod:”, 1234);
The version of objc_msgSend that is actually called into depends on the return type of the method being called, so accordingly there are a few versions of the interface in the objc_msgSend family.
For example, objc_msgSend() (for most return types), objc_msgSend_fpret() (for floating point return values), and objc_msgSend_stret(), for when the called method returns a struct type.
But what happens if you attempt to message a nil object pointer? Everyone who plays around with Objective-C code long enough soon realises that calling a method on a nil object pointer – or, more correctly, “messaging” a nil object pointer – is perfectly valid. So for example:
someObject = nil;
[someObject myMethod];
is absolutely fine. No segmentation fault – nothing. This is a very deliberate feature of the runtime, and many ObjC developers in fact use this feature to their advantage. You may end up with a nil object pointer due to an object allocation failure (out of memory), or some failure to find a substring inside a larger string, for example…
i.e.
MyClass myObj = [[MyClass alloc] init]; // out-of-memory conditions give myObj == nil
In any case, however an object pointer got to be nil, there are certain coding styles that allow a developer to use this feature perfectly harmlessly, and even for profit. However, there are also ways that too-liberal use of the feature can lead to bugs – both functionally and security-wise.
One thing that needs to be considered is, what do objc_msgSend variants return if the object pointer was indeed found to be nil? That is, we have have
myObj = nil;
someVariable = [myObj someMethod];
What will someVariable be equal to? Many developers assume it will always be some form of zero – and often they would be correct – but the true answer actually depends on the type of value that someMethod is defined to return. Quoting from Apple’s API documentation:
“””
– If the method returns any pointer type, any integer scalar of size less than or equal to sizeof(void*), a float, a double, a long double, or a long long, then a message sent to nil returns 0.
– If the method returns a struct, as defined by the OS X ABI Function Call Guide to be returned in registers, then a message sent to nil returns 0.0 for every field in the struct. Other struct data types will not be filled with zeros.
– If the method returns anything other than the aforementioned value types, the return value of a message sent to nil is undefined.
“””
The second line above looks interesting. The rule on the second line deals with methods that return struct types, for which the objc_msgSend() variant called in these cases will be the objc_msgSend_stret() interface.. What the above description is basically saying is, if the struct return type is larger than the width of the architecture’s registers (i.e. must be returned via the stack), if we call a struct-returning method on a nil object pointer, the ObjC runtime does NOT guarantee that our structure will be zeroed out after the call. Instead, the contents of the struct are undefined!
When structures to be “returned” are larger than the width of a register, objc_msgSend_stret() works by writing the return value into the memory area specified by the pointer passed to objc_msgSend_stret(). If we take a look in Apple’s ARM implementation of objc_msgSend_stret() in the runtime[1], which is coded in pure assembly, we can see how it is indeed true that the API does nothing to guarantee us a nicely 0-initialized struct return value:
/********************************************************************
* struct_type objc_msgSend_stret(id self,
* SEL op,
* …);
*
* objc_msgSend_stret is the struct-return form of msgSend.
* The ABI calls for a1 to be used as the address of the structure
* being returned, with the parameters in the succeeding registers.
*
* On entry: a1 is the address where the structure is returned,
* a2 is the message receiver,
* a3 is the selector
********************************************************************/
ENTRY objc_msgSend_stret
# check whether receiver is nil
teq a2, #0
bxeq lr
If the object pointer was nil, the function just exits…no memset()’ing to zero – nothing, and the “return value” of objc_msgSend_stret() in this case will effectively be whatever was already there in that place on the stack i.e. uninitialized data.
Although I’ll expand more later on the possible security consequences of getting
undefined struct contents back, most security people are aware that undefined/uninitialized data can lead to some interesting security bugs (uninitialized pointer dereferences, information leaks, etc).
So, let’s suppose that we have a method ‘myMethod’ in MyClass, and an object pointer of type MyClass that is equal to nil, and we accidentally attempt to call
the myMethod method on the nil pointer (i.e. some earlier operation failed), we have:
struct myStruct {
int myInt;
int otherInt;
float myFloat;
char myBuf[20];
}
[ … ]
struct myStruct returnStruct;
myObj = nil;
returnStruct = [myObj myMethod];
Does that mean we should definitely expect returnStruct, if we’re running on our ARM-based iPhone, to be full of uninitialized junk?
Not always. That depends on what compiler you’re using, and therefore, in pragmatic terms, what version of Xcode the iOS app was compiled in.
If the iOS app was compiled in Xcode 4.0 or earlier, where the default compiler is GCC 4.2[2], messaging nil with struct return methods does indeed result in undefined structure contents, since there is nothing in the runtime nor the compiler-generated assembly code to zero out the structure in the nil case.
However, if the app was compiled with LLVM-GCC 4.2 (Xcode 4.1) or Apple LLVM (circa Xcode 4.2), the compiler inserts assembly code that does a nil check followed by a memset(myStruct, 0x00, sizeof(*myStruct)) if the object pointer was indeed nil, adjacent to all objc_msgSend_stret() calls.
Therefore, if the app was compiled in Xcode 4.1 or later (LLVM-GCC 4.2 or Apple LLVM), messaging nil is *guaranteed* to *always* result in zeroed out structures upon return – so long as the default compiler for that Xcode release is used.. Otherwise, i.e. Xcode 4.0, the struct contents are completely undefined.
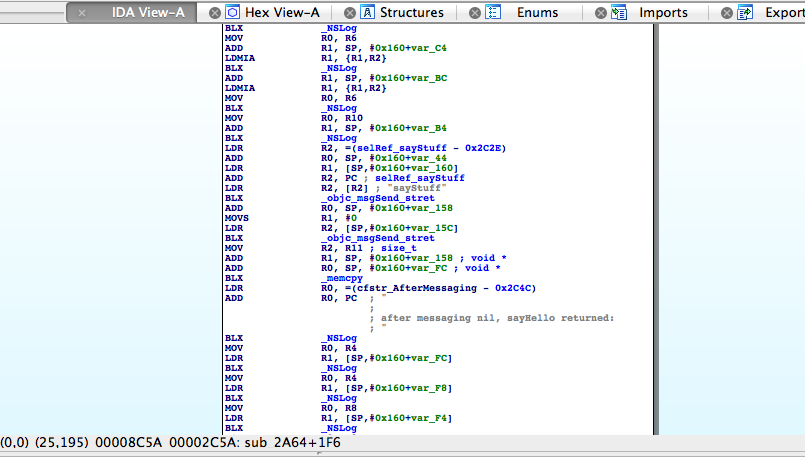
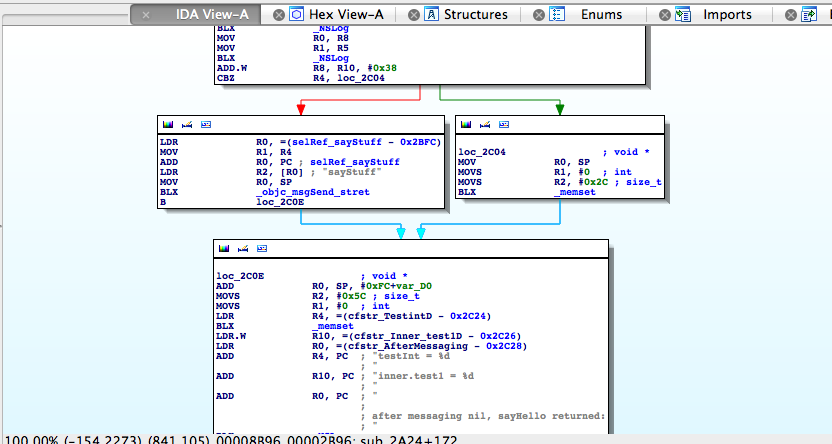
These two cases become apparent by comparing the disassemblies for calls to objc_msgSend_stret() as generated by 1) GCC 4.2, and 2) Apple LLVM. See the IDA Pro screen dumps below.
Figure 1 – objc_msgSend_stret() with GCC 4.2
Figure 2 – objc_msgSend_stret() with Apple LLVM
Figure 1 clearly shows objc_msgSend_stret() being called whether the object pointer is nil or not, and upon return from the function memcpy() is used to copy the “returned” struct data into the place we asked the structure to be returned to, i.e. our struct on stack. If the object pointer was nil, objc_msgSend_stret() just exits and ultimately this memcpy() ends up filling our structure with whatever happened to be there on the stack at the time…
In Figure 2, on the other hand, we see that the ARM ‘CBZ’ instruction is used to test the object pointer against 0 (nil) before the objc_msgSend_stret() call, with the memset()-to-0 code path instead being taken if the pointer was indeed nil. This guarantees that in the case of the objective pointer being nil, the structure will be completely zeroed.
Thus, summed up, any iOS applications released before July 2011 are extremely likely to be vulnerable, since they were almost certainly compiled with GCC. Apps built with Xcode 4.1 and up are most likely not vulnerable. But we have to bear in mind that a great deal of developers in real-world jobs do not necessarily update their IDE straightaway, regularly, or even at all (ever heard of corporate policy?). By all accounts, it’s probable that vulnerable apps (i.e. Xcode 4.0) are still being released on the App Store today.
It’s quite easy to experiment with this yourself with a bit of test code. Let’s write some code that demonstrates the entire issue. We can define a class called HelloWorld, and the class contains one method that returns a ‘struct teststruct’ value; and the method it simply puts a ton of recognisable data into an instance of ‘teststruct’, before returning it. The files in the class definition look like this:
hello.m
#import “hello.h”
@implementation HelloWorld
– (struct teststruct)sayHello
{
// NSLog(@”Hello, world!!nn”);
struct teststruct testy;
testy.testInt = 1337;
testy.testInt2 = 1338;
testy.inner.test1 = 1337;
testy.inner.test2 = 1337;
testy.testInt3 = 1339;
testy.testInt4 = 1340;
testy.testInt5 = 1341;
testy.testInt6 = 1341;
testy.testInt7 = 1341;
testy.testInt8 = 1341;
testy.testInt9 = 1341;
testy.testInt10 = 1341;
testy.testFloat = 1337.0;
testy.testFloat1 = 1338.1;
testy.testLong1 = 1337;
testy.testLong2 = 1338;
strcpy((char *)&testy.testBuf, “hello worldn”);
return testy;
}
@end
hello.h
#import <Foundation/Foundation.h>
@interface HelloWorld : NSObject {
// no instance variables
}
// methods
– (struct teststruct)sayHello;
@end
struct teststruct {
int testInt;
int testInt2;
struct {
int test1;
int test2;
} inner;
int testInt3;
int testInt4;
int testInt5;
int testInt6;
int testInt7;
int testInt8;
int testInt9;
int testInt10;
float testFloat;
float testFloat1;
long long testLong1;
long long testLong2;
char testBuf[20];
};
We can then write a bit of code in main() that allocates and initializes an object of class HelloWorld, calls sayHello, and prints the values it received back. Then, let’s set the object pointer to nil, attempt to call sayHello on the object pointer again, and then print out the values in the structure that we received that time around. We’ll use the following code:
#import <UIKit/UIKit.h>
#import <malloc/malloc.h>
#import “AppDelegate.h”
#import “hello.h”
#import “test.h”
#include <stdio.h>
#include <stdlib.h>
int main(int argc, char *argv[])
{
struct teststruct testStructure1;
struct teststruct testStructure2;
struct teststruct testStructure3;
struct otherstruct otherStructure;
HelloWorld *hw = [[HelloWorld alloc] init];
TestObj *otherObj = [[TestObj alloc] init];
testStructure1 = [hw sayHello];
/* what did sayHello return? */
NSLog(@”nsayHello returned:n”);
NSLog(@”testInt = %dn”, testStructure1.testInt);
NSLog(@”testInt = %dn”, testStructure1.testInt2);
NSLog(@”testInt = %dn”, testStructure1.testInt3);
NSLog(@”testInt = %dn”, testStructure1.testInt4);
NSLog(@”testInt = %dn”, testStructure1.testInt5);
NSLog(@”testInt = %dn”, testStructure1.testInt6);
NSLog(@”testInt = %dn”, testStructure1.testInt7);
NSLog(@”testInt = %dn”, testStructure1.testInt8);
NSLog(@”testInt = %dn”, testStructure1.testInt9);
NSLog(@”testInt = %dn”, testStructure1.testInt10);
NSLog(@”testInt = %5.3fn”, testStructure1.testFloat);
NSLog(@”testInt = %5.3fn”, testStructure1.testFloat1);
NSLog(@”testInt = %dn”, testStructure1.testLong1);
NSLog(@”testInt = %dn”, testStructure1.testLong2);
NSLog(@”testBuf = %sn”, testStructure1.testBuf);
/* clear the struct again */
memset((void *)&testStructure1, 0x00, sizeof(struct teststruct));
hw = nil; // nil object ptr
testStructure1 = [hw sayHello]; // message nil
/* what are the contents of the struct after messaging nil? */
NSLog(@”nnafter messaging nil, sayHello returned:n”);
NSLog(@”testInt = %dn”, testStructure1.testInt);
NSLog(@”testInt = %dn”, testStructure1.testInt2);
NSLog(@”testInt = %dn”, testStructure1.testInt3);
NSLog(@”testInt = %dn”, testStructure1.testInt4);
NSLog(@”testInt = %dn”, testStructure1.testInt5);
NSLog(@”testInt = %dn”, testStructure1.testInt6);
NSLog(@”testInt = %dn”, testStructure1.testInt7);
NSLog(@”testInt = %dn”, testStructure1.testInt8);
NSLog(@”testInt = %dn”, testStructure1.testInt9);
NSLog(@”testInt = %dn”, testStructure1.testInt10);
NSLog(@”testInt = %5.3fn”, testStructure1.testFloat);
NSLog(@”testInt = %5.3fn”, testStructure1.testFloat1);
NSLog(@”testInt = %dn”, testStructure1.testLong1);
NSLog(@”testInt = %dn”, testStructure1.testLong2);
NSLog(@”testBuf = %sn”, testStructure1.testBuf);
}
OK – let’s first test it on my developer provisioned iPhone 4S, by compiling it in Xcode 4.0 – i.e. with GCC 4.2 – since that is Xcode 4.0’s default iOS compiler. What do we get?
2012-11-01 21:12:36.235 sqli[65340:b303]
sayHello returned:
2012-11-01 21:12:36.237 sqli[65340:b303] testInt = 1337
2012-11-01 21:12:36.238 sqli[65340:b303] testInt = 1338
2012-11-01 21:12:36.238 sqli[65340:b303] testInt = 1339
2012-11-01 21:12:36.239 sqli[65340:b303] testInt = 1340
2012-11-01 21:12:36.239 sqli[65340:b303] testInt = 1341
2012-11-01 21:12:36.240 sqli[65340:b303] testInt = 1341
2012-11-01 21:12:36.241 sqli[65340:b303] testInt = 1341
2012-11-01 21:12:36.241 sqli[65340:b303] testInt = 1341
2012-11-01 21:12:36.242 sqli[65340:b303] testInt = 1341
2012-11-01 21:12:36.243 sqli[65340:b303] testInt = 1341
2012-11-01 21:12:36.244 sqli[65340:b303] testInt = 1337.000
2012-11-01 21:12:36.244 sqli[65340:b303] testInt = 1338.100
2012-11-01 21:12:36.245 sqli[65340:b303] testInt = 1337
2012-11-01 21:12:36.245 sqli[65340:b303] testInt = 1338
2012-11-01 21:12:36.246 sqli[65340:b303] testBuf = hello world
2012-11-01 21:12:36.246 sqli[65340:b303]
after messaging nil, sayHello returned:
2012-11-01 21:12:36.247 sqli[65340:b303] testInt = 1337
2012-11-01 21:12:36.247 sqli[65340:b303] testInt = 1338
2012-11-01 21:12:36.248 sqli[65340:b303] testInt = 1339
2012-11-01 21:12:36.249 sqli[65340:b303] testInt = 1340
2012-11-01 21:12:36.249 sqli[65340:b303] testInt = 1341
2012-11-01 21:12:36.250 sqli[65340:b303] testInt = 1341
2012-11-01 21:12:36.250 sqli[65340:b303] testInt = 1341
2012-11-01 21:12:36.251 sqli[65340:b303] testInt = 1341
2012-11-01 21:12:36.252 sqli[65340:b303] testInt = 1341
2012-11-01 21:12:36.252 sqli[65340:b303] testInt = 1341
2012-11-01 21:12:36.253 sqli[65340:b303] testInt = 1337.000
2012-11-01 21:12:36.253 sqli[65340:b303] testInt = 1338.100
2012-11-01 21:12:36.254 sqli[65340:b303] testInt = 1337
2012-11-01 21:12:36.255 sqli[65340:b303] testInt = 1338
2012-11-01 21:12:36.256 sqli[65340:b303] testBuf = hello world
Quite as we expected, we end up with a struct full of what was already there in the return position on the stack – and this just happened to be the return value from the last call to sayHello. In a complex app, the value would be somewhat unpredictable.
And now let’s compile and run it on my iPhone using Xcode 4.5, where I’m using its respective default compiler – Apple LLVM. The output:
2012-11-01 21:23:59.561 sqli[65866:b303]
sayHello returned:
2012-11-01 21:23:59.565 sqli[65866:b303] testInt = 1337
2012-11-01 21:23:59.566 sqli[65866:b303] testInt = 1338
2012-11-01 21:23:59.566 sqli[65866:b303] testInt = 1339
2012-11-01 21:23:59.567 sqli[65866:b303] testInt = 1340
2012-11-01 21:23:59.568 sqli[65866:b303] testInt = 1341
2012-11-01 21:23:59.569 sqli[65866:b303] testInt = 1341
2012-11-01 21:23:59.569 sqli[65866:b303] testInt = 1341
2012-11-01 21:23:59.570 sqli[65866:b303] testInt = 1341
2012-11-01 21:23:59.571 sqli[65866:b303] testInt = 1341
2012-11-01 21:23:59.572 sqli[65866:b303] testInt = 1341
2012-11-01 21:23:59.572 sqli[65866:b303] testInt = 1337.000
2012-11-01 21:23:59.573 sqli[65866:b303] testInt = 1338.100
2012-11-01 21:23:59.574 sqli[65866:b303] testInt = 1337
2012-11-01 21:23:59.574 sqli[65866:b303] testInt = 1338
2012-11-01 21:23:59.575 sqli[65866:b303] testBuf = hello world
2012-11-01 21:23:59.576 sqli[65866:b303]
after messaging nil, sayHello returned:
2012-11-01 21:23:59.577 sqli[65866:b303] testInt = 0
2012-11-01 21:23:59.577 sqli[65866:b303] testInt = 0
2012-11-01 21:23:59.578 sqli[65866:b303] testInt = 0
2012-11-01 21:23:59.578 sqli[65866:b303] testInt = 0
2012-11-01 21:23:59.579 sqli[65866:b303] testInt = 0
2012-11-01 21:23:59.579 sqli[65866:b303] testInt = 0
2012-11-01 21:23:59.580 sqli[65866:b303] testInt = 0
2012-11-01 21:23:59.581 sqli[65866:b303] testInt = 0
2012-11-01 21:23:59.581 sqli[65866:b303] testInt = 0
2012-11-01 21:23:59.582 sqli[65866:b303] testInt = 0
2012-11-01 21:23:59.582 sqli[65866:b303] testInt = 0.000
2012-11-01 21:23:59.673 sqli[65866:b303] testInt = 0.000
2012-11-01 21:23:59.673 sqli[65866:b303] testInt = 0
2012-11-01 21:23:59.674 sqli[65866:b303] testInt = 0
2012-11-01 21:23:59.675 sqli[65866:b303] testBuf =
Also just as we expected; the Apple LLVM built version gives us all zeroed struct fields, as the compiler-inserted memset() call guarantees us a zeroed struct when we message nil.
Now, to be pragmatic, what are some potential security consequences of us getting junk, uninitialized data back, in real-world applications?
One possible scenario is to consider if we had a method, say, returnDataEntry, that, for example, returns a struct containing some data and a pointer. We could make the scenario more detailed, but for argument’s sake let’s just assume the structure holds some data and a pointer to some more data.
Consider the following code fragment, in which the developer knows they’ll receive a zeroed structure from returnDataEntry if the someFunctionThatCanFail()
call fails:
struct someData {
int someInt;
char someData[50];
void *myPointer;
}
[ … ]
– (struct someData)returnDataEntry
{
struct someData myData;
memset((void *)&myData, 0x00, sizeof(struct someData)); /* zero it out */
if(!someFunctionThatCanFail()) { /* can fail! */
/* something went wrong, return the zeroed struct */
return myData;
}
/* otherwise do something useful */
myData = someUsefulDataFunction();
return myData;
}
In the error case, the developer knows that they can check the contents of the struct against 0 and therefore know if returnDataEntry ran successfully.
i.e.
myData = [myObj returnDataEntry];
if(myData.myPointer == NULL) {
/* the method failed */
}
/* otherwise, use the data and pointer */
However, if we suppose that the ‘myObj’ pointer was nil at the time of the returnDataEntry call, and our app was built with a vulnerable version of Xcode, the returned structure will be uninitialized, and myData.myPointer could be absolutely anything, so at this point, we have a dangling pointer and, therefore, a security bug.
Equally, what if some method is declared to return a structure, and that data is later sent to a remote server over the network? A scenario like this could easily result in information leaks, and it’s easy to see how that’s bad.
Lastly, which is also quite interesting, let’s consider some Cocoa APIs that take structs and process them. We’ll take a bog standard structure – NSDecimal, for example. The NSDecimal structure is defined as:
typedef struct {
signed int _exponent:8;
unsigned int _length:4; // length == 0 && isNegative -> NaN
unsigned int _isNegative:1;
unsigned int _isCompact:1;
unsigned int _reserved:18;
unsigned short _mantissa[NSDecimalMaxSize];
} NSDecimal;
It’s pretty obvious by those underscores that all fields in NSDecimal are ‘private’ – that is, they should not be directly used or modified, and their semantics are subject to change if Apple sees fit. As such, NSDecimal structures should only be used and manipulated using official NSDecimal APIs. There’s even a length field, which could be interesting.
The fact that all fields in NSDecimal are documented as being private[3] starts to make me wonder whether the NSDecimal APIs are actually safe to call on malformed NSDecimal structs. Let’s test that theory out.
Let’s assume we got a garbage NSDecimal structure back from messaging a nil object at some earlier point in the app, and then we pass this NSDecimal struct to Cocoa’s NSDecimalString() API. We could simulate the situation with a bit of code like this:
NSDecimal myDecimal;
/* fill the two structures with bad data */
memset(&myDecimal, 0x99, sizeof(NSDecimal));
NSLocale *usLocale = [[NSLocale alloc] initWithLocaleIdentifier:@”en_US”];
NSDecimalString(&myDecimal, usLocale);
What happens?
If we quickly just run this in the iOS Simulator (x86), we crash with a write access violation at the following line in NSDecimalString():
<+0505> mov %al,(%esi,%edx,1)
(gdb) info reg esi edx
esi 0xffffffca -54
edx 0x38fff3f4 956298228
Something has clearly gone wrong here, since there’s no way that address is going to be mapped and writable…
It turns out that the above line of assembly is part of a loop which uses length values derived from
the invalid values in our NSDecimal struct. Let’s set a breakpoint at the line above our crashing line, and see what things look like at the first hit of the
breakpoint, and then, at crash time.
0x008f4275 <+0499> mov -0x11c(%ebp),%edx
0x008f427b <+0505> mov %al,(%esi,%edx,1)
(gdb) x/x $ebp-0x11c
0xbffff3bc: 0xbffff3f4
So 0xbffff3f4 is the base address of where the loop is copying data to. And after the write AV, i.e. at crash time, the base pointer looks like:
(gdb) x/x $ebp-0x11c
0xbffff3bc: 0x38fff3f4
(gdb)
Thus after a little analysis, it becomes apparent that the root cause of the crash is stack corruption – the most significant byte of the base destination address is being overwritten (with a 0x38 byte) on the stack during the loop. This is at least a nods towards several Cocoa APIs not being designed to deal with malformed structs with “private” fields. There are likely to be more such cases, considering the sheer size of Cocoa.
Although NSDecimalString() is where the crash occurred, I wouldn’t really consider this a bug in the API per se, since it is well-documented that members of NSDecimal structs
are private. This could be considered akin to memory corruption bugs caused by misuse of strcpy() – the bug isn’t really in the API as such – it’s doing what is was designed to do – it’s the manner in which you used it that constitutes a bug.
Interestingly, it seems to be possible to detect which compiler an app was built with by running a strings dump on the Info.plist file found in an app’s IPA bundle.
Apple LLVM
sh-3.2# strings Info.plist | grep compiler
“com.apple.compilers.llvm.clang.1_0
LLVM GCC
sh-3.2# strings Info.plist | grep compiler
com.apple.compilers.llvmgcc42
GCC
sh-3.2# strings Info.plist | grep compiler
sh-3.2#
What are the take home notes here? Basically, if you use a method that returns a structure type, check the object against nil first! Even if you know YOU’RE not going to be using a mid-2011 version
of Xcode, if you post your library on GitHub or similar, how do you know your code is not going to go into a widely used banking product, for example? – the developers for which may still be using a slightly older version of Xcode, perhaps even due to corporate policy.
It’d therefore be a decent idea to include this class of bugs on your secure code review checklist for iOS applications.
Thanks for reading.
Shaun.
[1] http://www.opensource.apple.com/source/objc4/objc4-532/runtime/Messengers.subproj/objc-msg-arm.s
[2] http://developer.apple.com/library/mac/#documentation/DeveloperTools/Conceptual/WhatsNewXcode/Articles/xcode_4_1.html
[3] https://developer.apple.com/library/mac/#documentation/Cocoa/Reference/Foundation/Miscellaneous/Foundation_DataTypes/Reference/reference.html
P.S. I’ve heard that Objective-C apps running on PowerPC platforms can also be vulnerable to such bugs – except with other return types as well, such as float and long long. But I can’t confirm that, since I don’t readily have access to a system running on the PowerPC architecture.